Department of Computer Science, University of Toronto, Toronto, Canada.
DATA Team & Techna Institute, University Health Network, Toronto, Canada.
Nat Commun. 2021 Sep 7;12(1):5319. doi: 10.1038/s41467-021-25578-4.
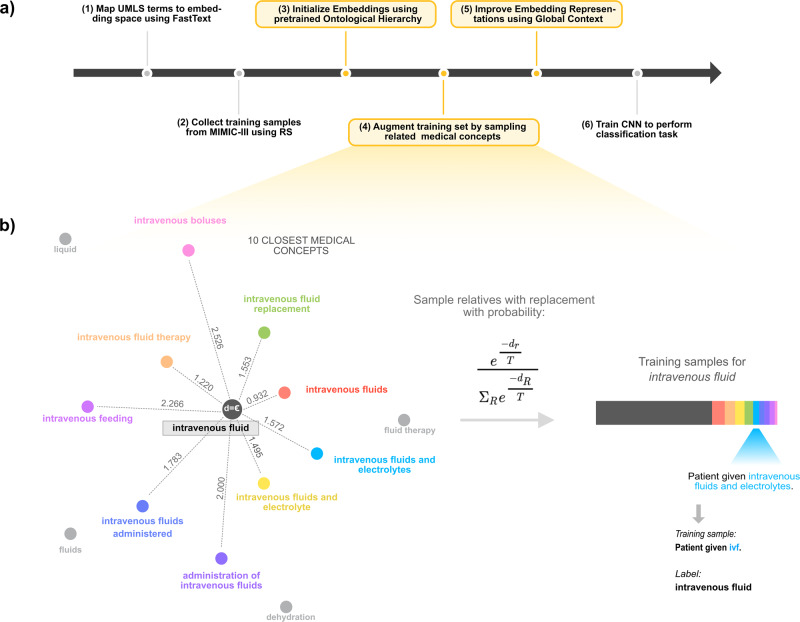
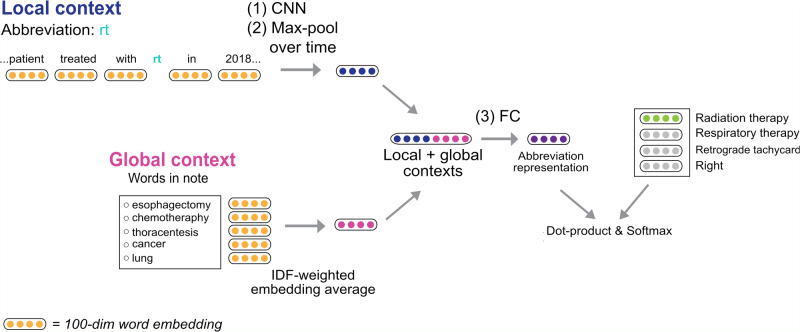
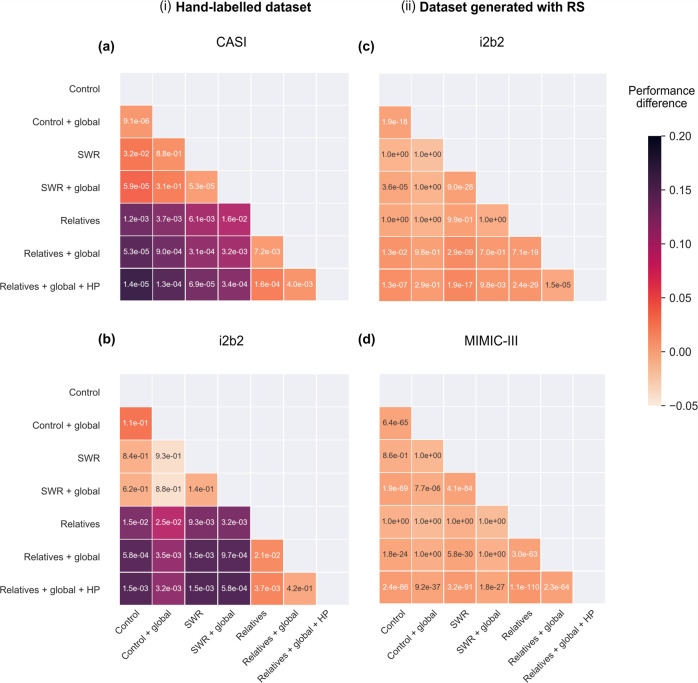
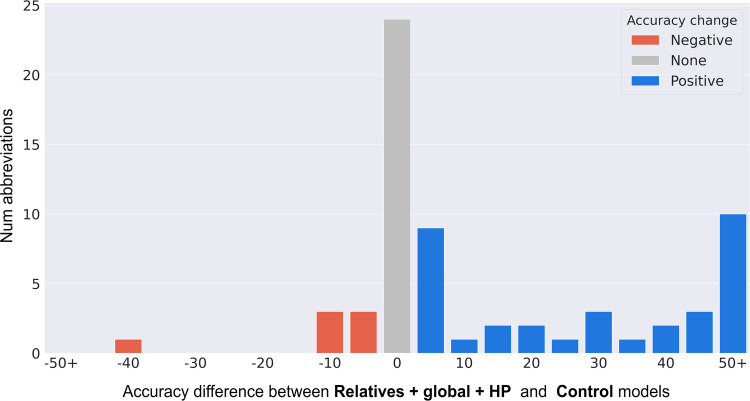
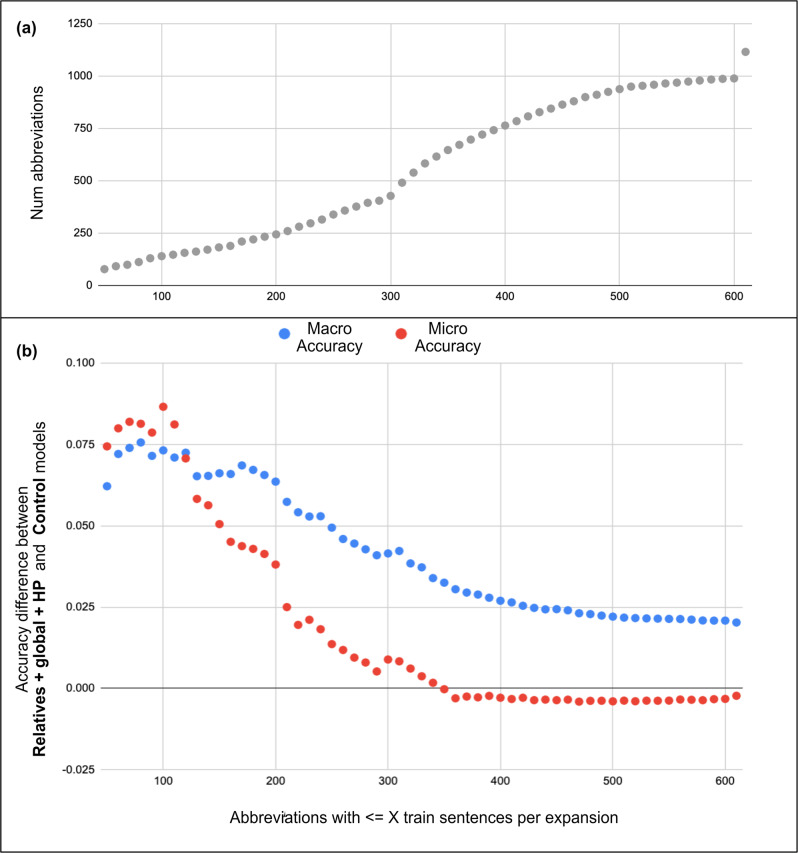
Modern machine learning (ML) technologies have great promise for automating diverse clinical and research workflows; however, training them requires extensive hand-labelled datasets. Disambiguating abbreviations is important for automated clinical note processing; however, broad deployment of ML for this task is restricted by the scarcity and imbalance of labeled training data. In this work we present a method that improves a model's ability to generalize through novel data augmentation techniques that utilizes information from biomedical ontologies in the form of related medical concepts, as well as global context information within the medical note. We train our model on a public dataset (MIMIC III) and test its performance on automatically generated and hand-labelled datasets from different sources (MIMIC III, CASI, i2b2). Together, these techniques boost the accuracy of abbreviation disambiguation by up to 17% on hand-labeled data, without sacrificing performance on a held-out test set from MIMIC III.
现代机器学习 (ML) 技术在自动化各种临床和研究工作流程方面具有巨大的潜力;然而,训练它们需要广泛的手动标记数据集。消除缩写词对于自动化临床记录处理很重要;然而,由于标记训练数据的稀缺性和不平衡,限制了 ML 对此任务的广泛应用。在这项工作中,我们提出了一种通过利用生物医学本体的相关医学概念形式的信息以及医学记录中的全局上下文信息的新的数据增强技术来提高模型泛化能力的方法。我们在一个公共数据集 (MIMIC III) 上训练我们的模型,并在来自不同来源的自动生成和手动标记数据集 (MIMIC III、CASI、i2b2) 上测试其性能。这些技术结合起来,在手写标记数据上将缩写词消歧的准确性提高了 17%,而不会牺牲对 MIMIC III 中保留测试集的性能。