School of Computer Science and Engineering, Kyungpook National University, 80 Daehak-ro, Buk-gu, Daegu 41566, Korea.
Department of Computer Science, Durham University, Stockton Road, Durham DH1 3LE, UK.
Sensors (Basel). 2021 Sep 29;21(19):6509. doi: 10.3390/s21196509.
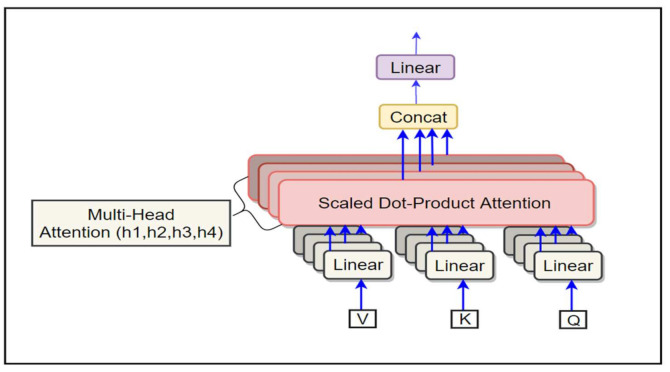
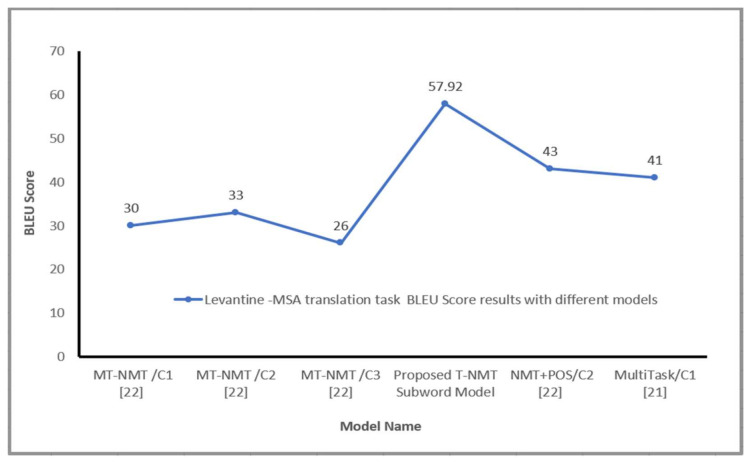
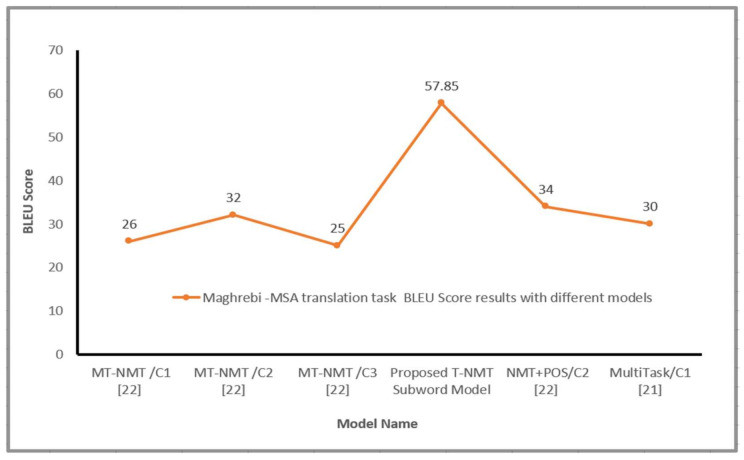
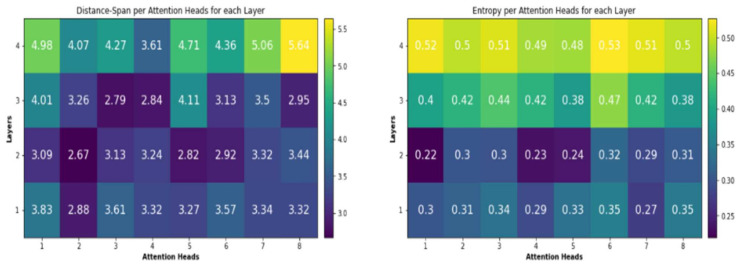
Languages that allow free word order, such as Arabic dialects, are of significant difficulty for neural machine translation (NMT) because of many scarce words and the inefficiency of NMT systems to translate these words. Unknown Word (UNK) tokens represent the out-of-vocabulary words for the reason that NMT systems run with vocabulary that has fixed size. Scarce words are encoded completely as sequences of subword pieces employing the Word-Piece Model. This research paper introduces the first Transformer-based neural machine translation model for Arabic vernaculars that employs subword units. The proposed solution is based on the Transformer model that has been presented lately. The use of subword units and shared vocabulary within the Arabic dialect (the source language) and modern standard Arabic (the target language) enhances the behavior of the multi-head attention sublayers for the encoder by obtaining the overall dependencies between words of input sentence for Arabic vernacular. Experiments are carried out from Levantine Arabic vernacular (LEV) to modern standard Arabic (MSA) and Maghrebi Arabic vernacular (MAG) to MSA, Gulf-MSA, Nile-MSA, Iraqi Arabic (IRQ) to MSA translation tasks. Extensive experiments confirm that the suggested model adequately addresses the unknown word issue and boosts the quality of translation from Arabic vernaculars to Modern standard Arabic (MSA).
允许自由词序的语言,如阿拉伯语方言,由于词汇量少且神经机器翻译(NMT)系统翻译这些词的效率低下,因此对 NMT 来说具有很大的难度。未知词(UNK)标记表示词汇表外的词,因为 NMT 系统使用词汇量固定的词汇表。稀有词完全通过使用子词单元的词块模型进行子词序列编码。本研究论文介绍了第一个基于 Transformer 的阿拉伯语白话神经机器翻译模型,该模型使用子词单元。所提出的解决方案基于最近提出的 Transformer 模型。在阿拉伯语方言(源语言)和现代标准阿拉伯语(目标语言)中使用子词单元和共享词汇,通过获得阿拉伯语白话输入句子中单词之间的整体依赖关系,增强了编码器多头注意力子层的行为。实验是从 Levantine 阿拉伯语白话(LEV)到现代标准阿拉伯语(MSA)和 Maghrebi 阿拉伯语白话(MAG)到 MSA、海湾 MSA、尼罗河 MSA、伊拉克阿拉伯语(IRQ)到 MSA 翻译任务进行的。广泛的实验证实,所提出的模型充分解决了未知词问题,并提高了从阿拉伯语白话到现代标准阿拉伯语(MSA)的翻译质量。