Xi'an Jiaotong University, Xi'an, 710049, Shaanxi, China.
Sci Rep. 2021 Oct 12;11(1):20244. doi: 10.1038/s41598-021-98794-z.
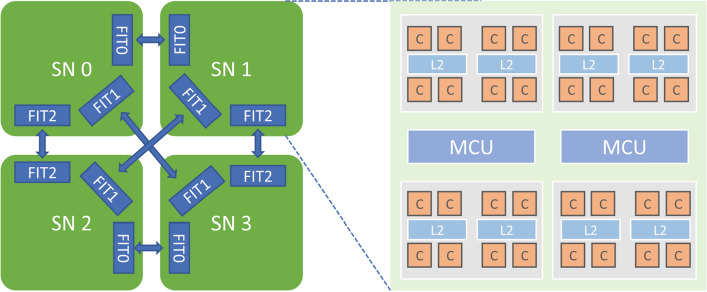
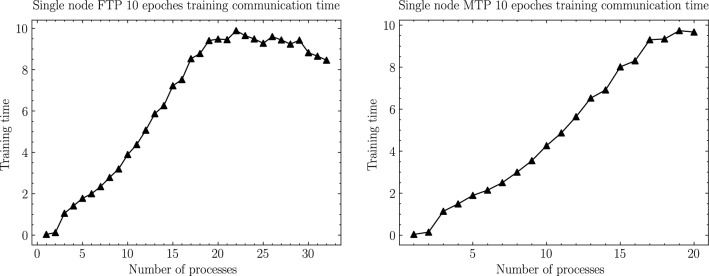
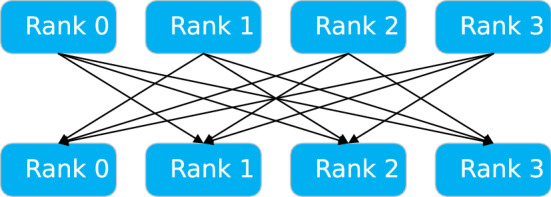
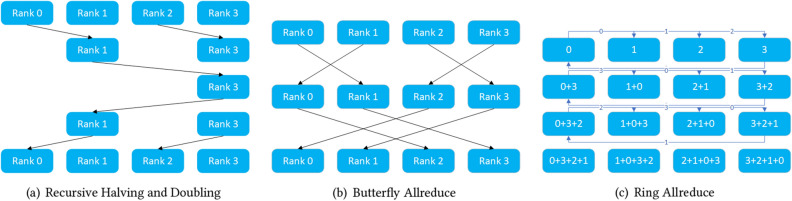
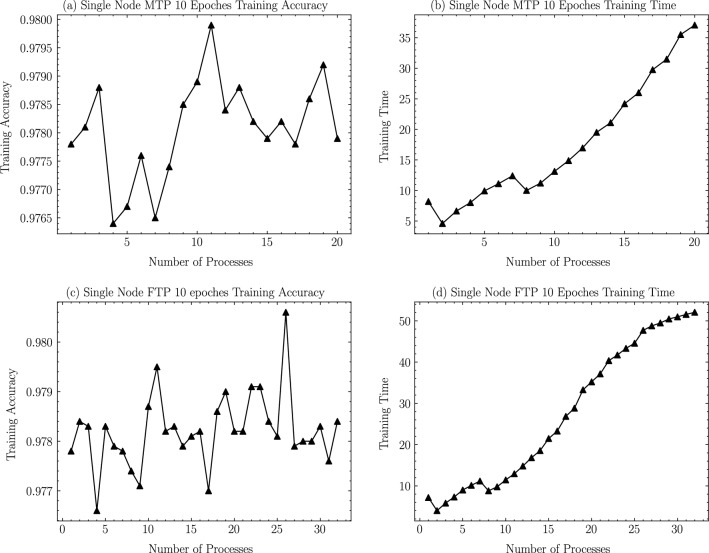
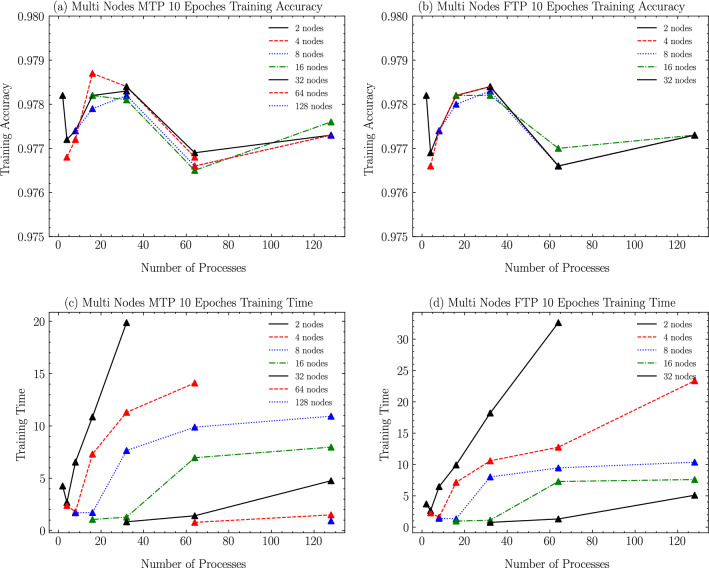
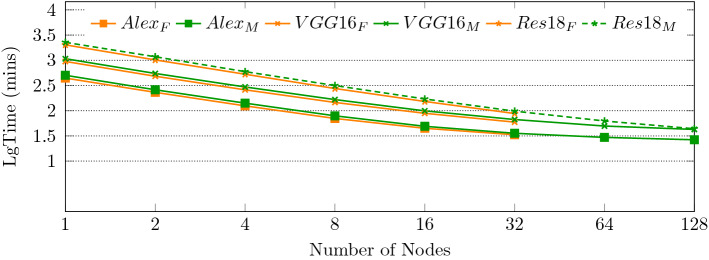
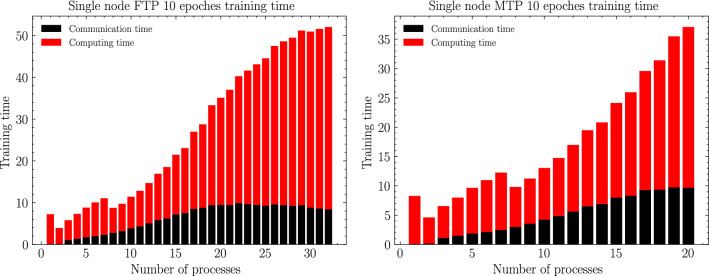
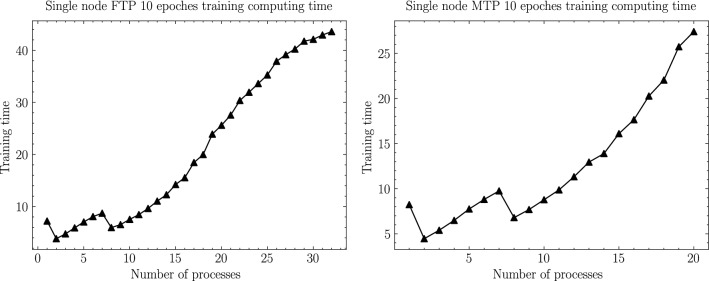
Due to the increase in computing power, it is possible to improve the feature extraction and data fitting capabilities of DNN networks by increasing their depth and model complexity. However, the big data and complex models greatly increase the training overhead of DNN, so accelerating their training process becomes a key task. The Tianhe-3 peak speed is designed to target E-class, and the huge computing power provides a potential opportunity for DNN training. We implement and extend LeNet, AlexNet, VGG, and ResNet model training for a single MT-2000+ and FT-2000+ compute nodes, as well as extended multi-node clusters, and propose an improved gradient synchronization process for Dynamic Allreduce communication optimization strategy for the gradient synchronization process base on the ARM architecture features of the Tianhe-3 prototype, providing experimental data and theoretical basis for further enhancing and improving the performance of the Tianhe-3 prototype in large-scale distributed training of neural networks.
由于计算能力的提高,可以通过增加 DNN 网络的深度和模型复杂度来提高其特征提取和数据拟合能力。然而,大数据和复杂模型大大增加了 DNN 的训练开销,因此加速其训练过程成为关键任务。天河三号的峰值速度设计针对 E 级,巨大的计算能力为 DNN 训练提供了潜在机会。我们在单个 MT-2000+ 和 FT-2000+ 计算节点上实现和扩展了 LeNet、AlexNet、VGG 和 ResNet 模型训练,以及扩展的多节点集群,并提出了一种改进的梯度同步过程,用于基于天河三号原型的 ARM 架构特性的动态 Allreduce 通信优化策略,为进一步增强和提高天河三号原型在神经网络大规模分布式训练中的性能提供了实验数据和理论依据。