Dobbie Samuel, Strafford Huw, Pickrell W Owen, Fonferko-Shadrach Beata, Jones Carys, Akbari Ashley, Thompson Simon, Lacey Arron
Health Data Research UK, Swansea University Medical School, Swansea University, Swansea, United Kingdom.
Swansea University Medical School, Swansea University, Swansea, United Kingdom.
Front Digit Health. 2021 Jul 26;3:598916. doi: 10.3389/fdgth.2021.598916. eCollection 2021.
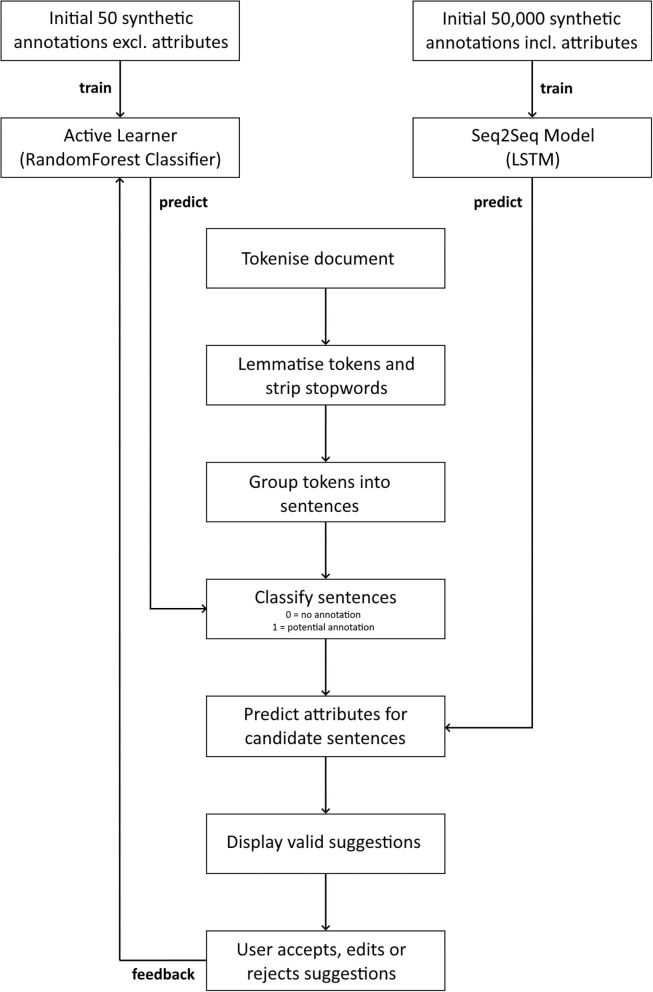
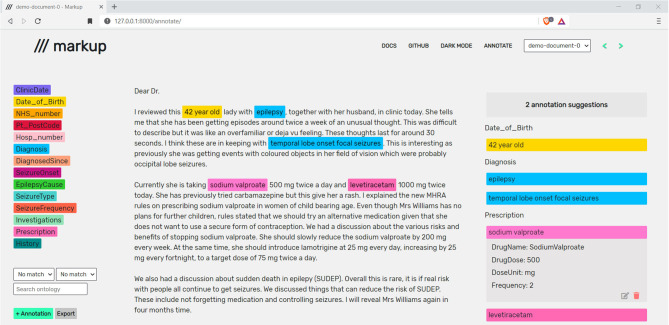
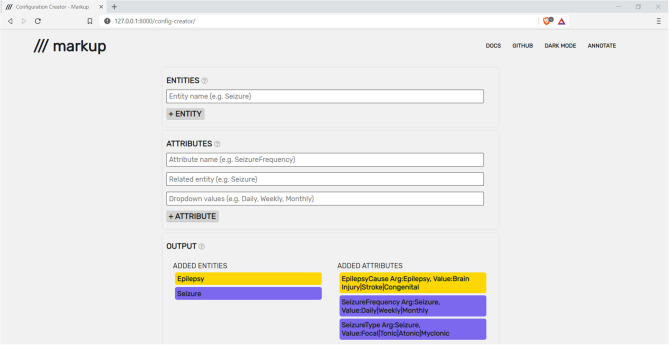
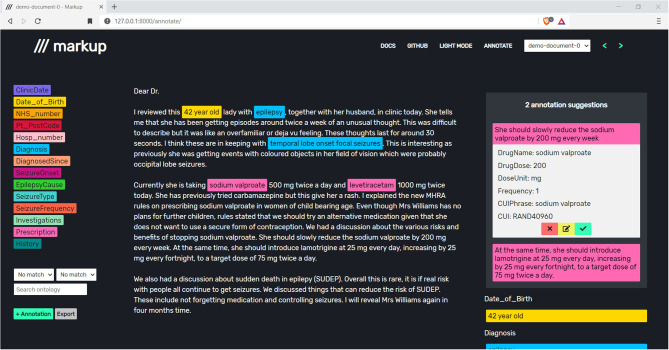
Across various domains, such as health and social care, law, news, and social media, there are increasing quantities of unstructured texts being produced. These potential data sources often contain rich information that could be used for domain-specific and research purposes. However, the unstructured nature of free-text data poses a significant challenge for its utilisation due to the necessity of substantial manual intervention from domain-experts to label embedded information. Annotation tools can assist with this process by providing functionality that enables the accurate capture and transformation of unstructured texts into structured annotations, which can be used individually, or as part of larger Natural Language Processing (NLP) pipelines. We present Markup (https://www.getmarkup.com/) an open-source, web-based annotation tool that is undergoing continued development for use across all domains. Markup incorporates NLP and Active Learning (AL) technologies to enable rapid and accurate annotation using custom user configurations, predictive annotation suggestions, and automated mapping suggestions to both domain-specific ontologies, such as the Unified Medical Language System (UMLS), and custom, user-defined ontologies. We demonstrate a real-world use case of how Markup has been used in a healthcare setting to annotate structured information from unstructured clinic letters, where captured annotations were used to build and test NLP applications.
在健康与社会护理、法律、新闻和社交媒体等各个领域,正在产生越来越多的非结构化文本。这些潜在的数据源通常包含丰富的信息,可用于特定领域和研究目的。然而,自由文本数据的非结构化性质对其利用构成了重大挑战,因为需要领域专家进行大量人工干预来标记嵌入的信息。注释工具可以通过提供相关功能来辅助这一过程,该功能能够将非结构化文本准确地捕获并转换为结构化注释,这些注释既可以单独使用,也可以作为更大的自然语言处理(NLP)管道的一部分。我们展示了Markup(https://www.getmarkup.com/),这是一个基于网络的开源注释工具,目前正在持续开发,以便在所有领域使用。Markup整合了自然语言处理和主动学习(AL)技术,能够使用自定义用户配置、预测性注释建议以及针对特定领域本体(如统一医学语言系统(UMLS))和自定义用户定义本体的自动映射建议,实现快速准确的注释。我们展示了一个实际应用案例,说明Markup如何在医疗环境中用于注释非结构化临床信件中的结构化信息,其中捕获的注释用于构建和测试自然语言处理应用程序。