National Genomics Data Center & CAS Key Laboratory of Genome Sciences and Information, Beijing Institute of Genomics, Chinese Academy of Sciences, Beijing 100101, China.
China National Center for Bioinformation, Beijing 100101, China.
Nucleic Acids Res. 2022 Jan 7;50(D1):D962-D969. doi: 10.1093/nar/gkab979.
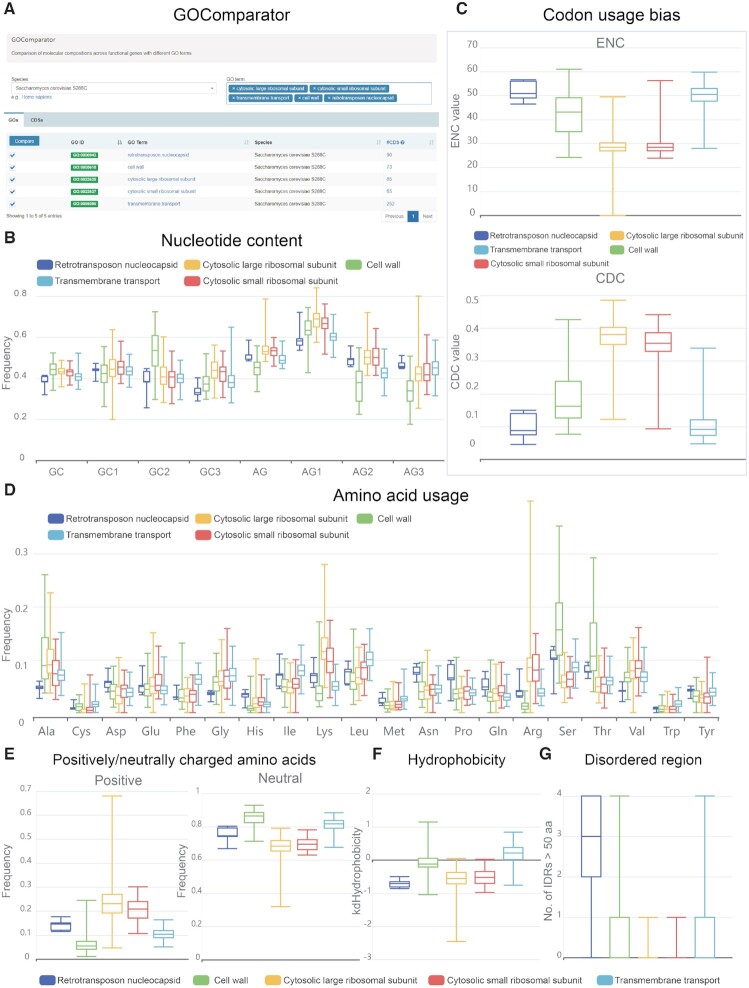
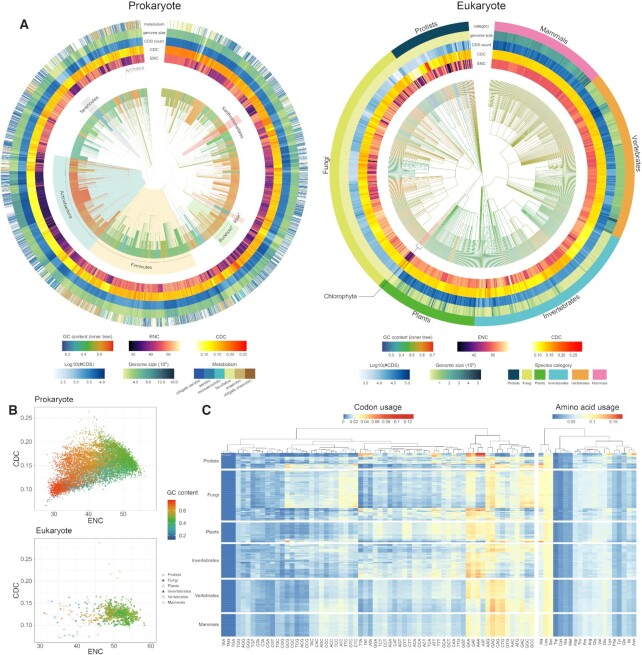
Sequence compositions of nucleic acids and proteins have significant impact on gene expression, RNA stability, translation efficiency, RNA/protein structure and molecular function, and are associated with genome evolution and adaptation across all kingdoms of life. Therefore, a devoted resource of sequence compositions and associated features is fundamentally crucial for a wide range of biological research. Here, we present CompoDynamics (https://ngdc.cncb.ac.cn/compodynamics/), a comprehensive database of sequence compositions of coding sequences (CDSs) and genomes for all kinds of species. Taking advantage of the exponential growth of RefSeq data, CompoDynamics presents a wealth of sequence compositions (nucleotide content, codon usage, amino acid usage) and derived features (coding potential, physicochemical property and phase separation) for 118 689 747 high-quality CDSs and 34 562 genomes across 24 995 species. Additionally, interactive analytical tools are provided to enable comparative analyses of sequence compositions and molecular features across different species and gene groups. Collectively, CompoDynamics bears the great potential to better understand the underlying roles of sequence composition dynamics across genes and genomes, providing a fundamental resource in support of a broad spectrum of biological studies.
核酸和蛋白质的序列组成对基因表达、RNA 稳定性、翻译效率、RNA/蛋白质结构和分子功能有重要影响,并与所有生命领域的基因组进化和适应有关。因此,专门的序列组成和相关特征资源对于广泛的生物学研究至关重要。在这里,我们介绍 CompoDynamics(https://ngdc.cncb.ac.cn/compodynamics/),这是一个包含所有物种编码序列(CDS)和基因组序列组成的综合数据库。利用 RefSeq 数据的指数增长,CompoDynamics 为 24995 个物种的 118689747 个高质量 CDS 和 34562 个基因组提供了丰富的序列组成(核苷酸含量、密码子使用、氨基酸使用)和衍生特征(编码潜力、理化性质和相分离)。此外,还提供了交互式分析工具,可用于比较不同物种和基因组之间的序列组成和分子特征。总之,CompoDynamics 具有更好地理解基因和基因组中序列组成动态的巨大潜力,为广泛的生物学研究提供了基本资源支持。