Srinivasan Shriram, O'Malley Daniel, Mudunuru Maruti K, Sweeney Matthew R, Hyman Jeffrey D, Karra Satish, Frash Luke, Carey J William, Gross Michael R, Guthrie George D, Carr Timothy, Li Liwei, Viswanathan Hari S
Los Alamos National Laboratory, Los Alamos, NM, 87544, USA.
Watershed & Ecosystem Science, Pacific Northwest National Laboratory, Richland, WA, 99352, USA.
Sci Rep. 2021 Nov 5;11(1):21730. doi: 10.1038/s41598-021-01023-w.
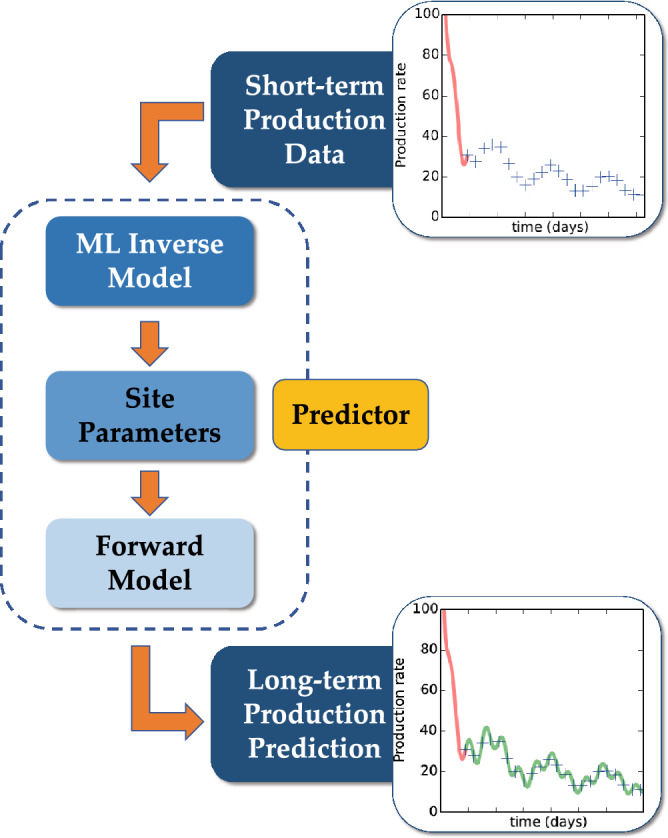
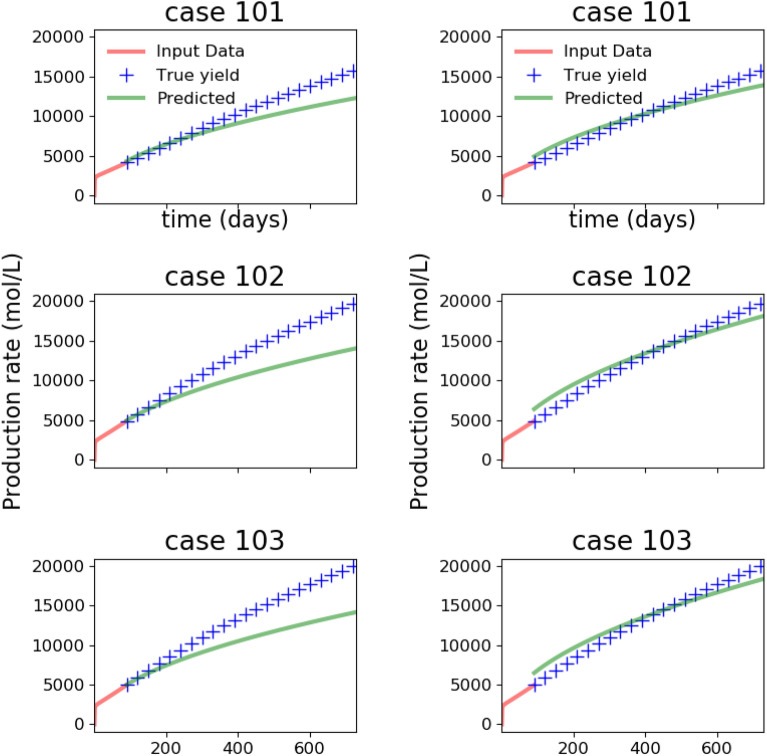
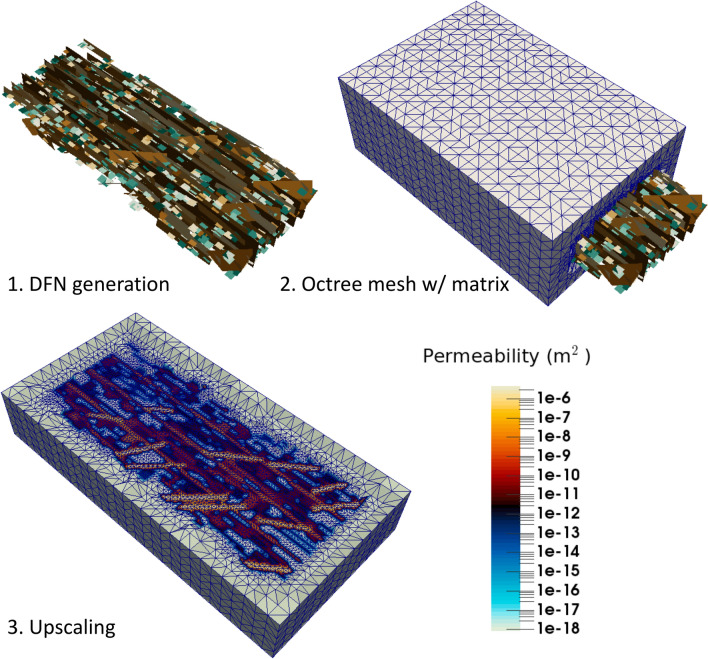
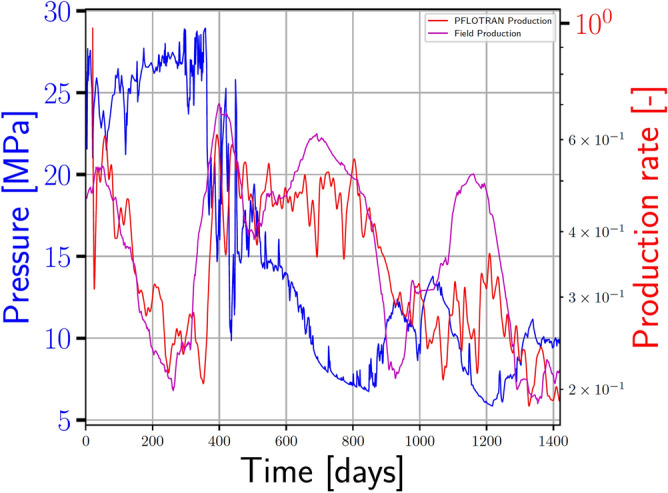
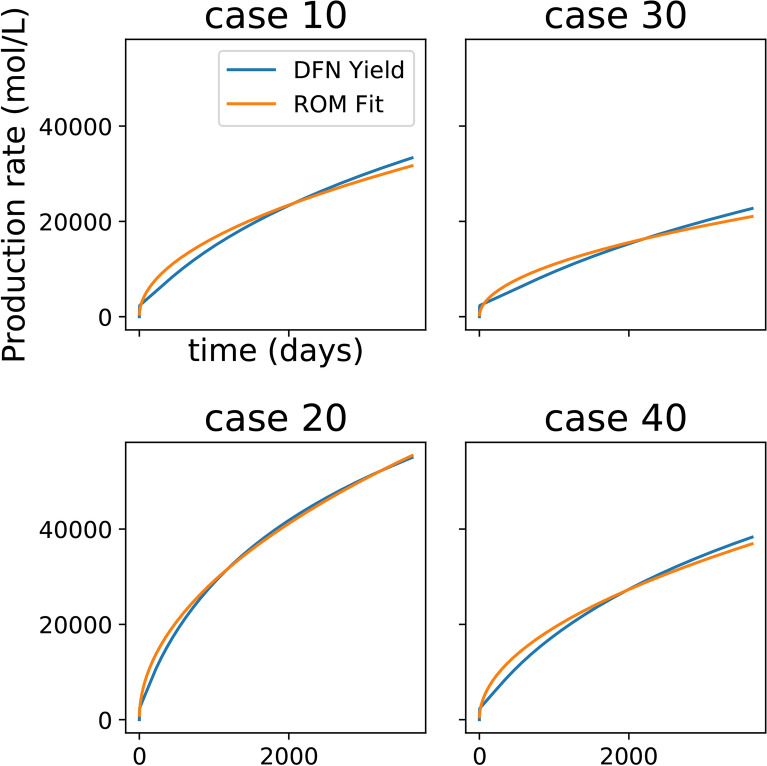
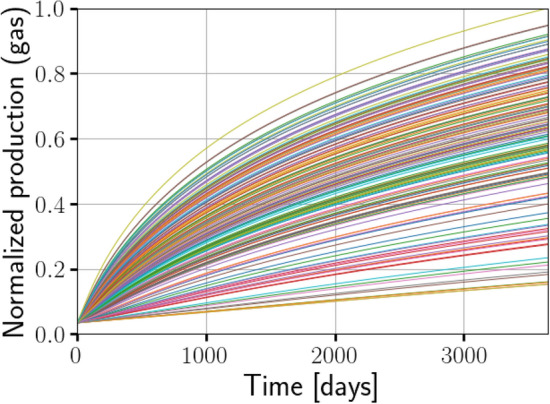
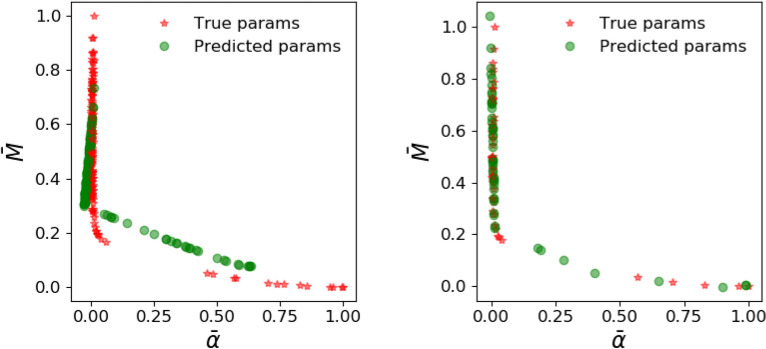
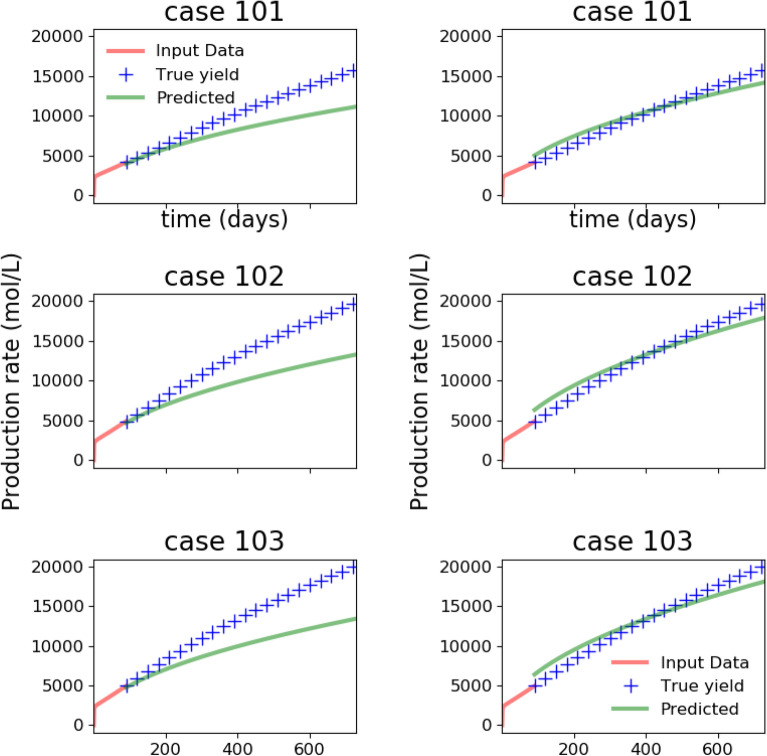
We present a novel workflow for forecasting production in unconventional reservoirs using reduced-order models and machine-learning. Our physics-informed machine-learning workflow addresses the challenges to real-time reservoir management in unconventionals, namely the lack of data (i.e., the time-frame for which the wells have been producing), and the significant computational expense of high-fidelity modeling. We do this by applying the machine-learning paradigm of transfer learning, where we combine fast, but less accurate reduced-order models with slow, but accurate high-fidelity models. We use the Patzek model (Proc Natl Acad Sci 11:19731-19736, https://doi.org/10.1073/pnas.1313380110 , 2013) as the reduced-order model to generate synthetic production data and supplement this data with synthetic production data obtained from high-fidelity discrete fracture network simulations of the site of interest. Our results demonstrate that training with low-fidelity models is not sufficient for accurate forecasting, but transfer learning is able to augment the knowledge and perform well once trained with the small set of results from the high-fidelity model. Such a physics-informed machine-learning (PIML) workflow, grounded in physics, is a viable candidate for real-time history matching and production forecasting in a fractured shale gas reservoir.
我们提出了一种使用降阶模型和机器学习来预测非常规油藏产量的新颖工作流程。我们基于物理知识的机器学习工作流程解决了非常规油藏实时管理面临的挑战,即缺乏数据(即油井生产的时间范围)以及高保真建模的巨大计算成本。我们通过应用迁移学习的机器学习范式来实现这一点,在该范式中,我们将快速但不太准确的降阶模型与缓慢但准确的高保真模型相结合。我们使用Patzek模型(《美国国家科学院院刊》11:19731 - 19736,https://doi.org/10.1073/pnas.1313380110,2013)作为降阶模型来生成合成生产数据,并用从感兴趣区域的高保真离散裂缝网络模拟中获得的合成生产数据来补充这些数据。我们的结果表明,仅用低保真模型进行训练不足以进行准确预测,但迁移学习能够在利用高保真模型的少量结果进行训练后增强知识并表现良好。这种基于物理知识且以物理为基础的机器学习(PIML)工作流程,是裂缝性页岩气藏实时历史拟合和产量预测的一个可行候选方案。