Lamsal Rabindra
School of Computer and Systems Sciences, Jawaharlal Nehru University, New Delhi, 110067 India.
Appl Intell (Dordr). 2021;51(5):2790-2804. doi: 10.1007/s10489-020-02029-z. Epub 2020 Nov 6.
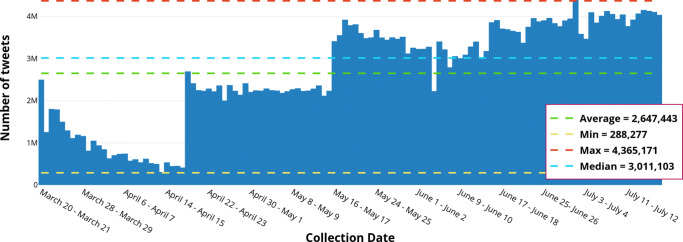
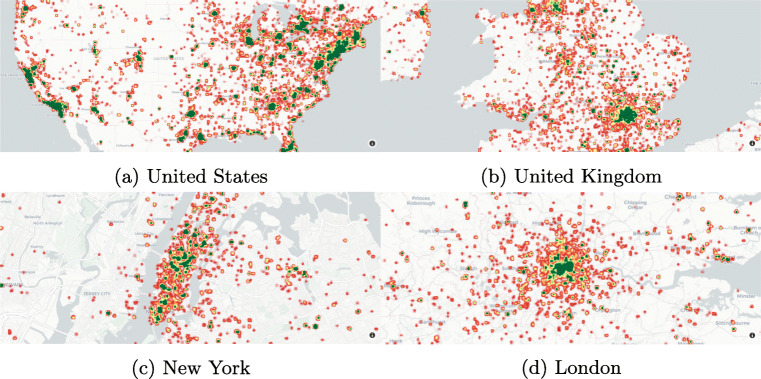
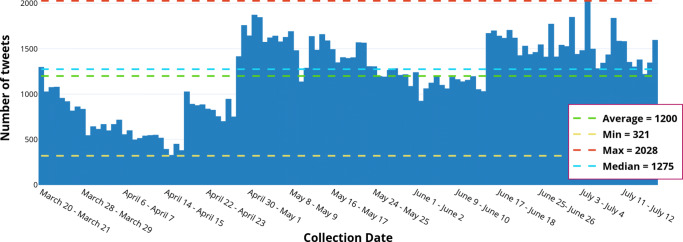
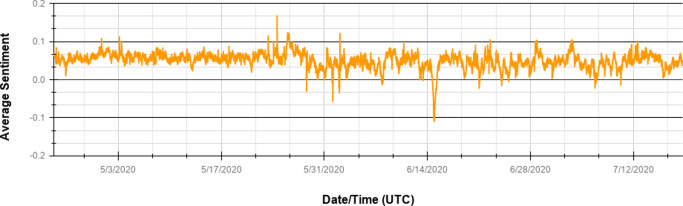
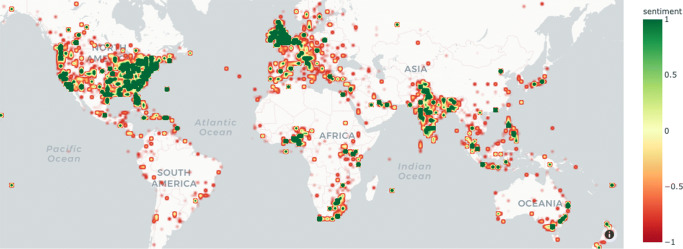
As of July 17, 2020, more than thirteen million people have been diagnosed with the Novel Coronavirus (COVID-19), and half a million people have already lost their lives due to this infectious disease. The World Health Organization declared the COVID-19 outbreak as a pandemic on March 11, 2020. Since then, social media platforms have experienced an exponential rise in the content related to the pandemic. In the past, Twitter data have been observed to be indispensable in the extraction of situational awareness information relating to any crisis. This paper presents COV19Tweets Dataset (Lamsal 2020a), a large-scale Twitter dataset with more than 310 million COVID-19 specific English language tweets and their sentiment scores. The dataset's geo version, the GeoCOV19Tweets Dataset (Lamsal 2020b), is also presented. The paper discusses the datasets' design in detail, and the tweets in both the datasets are analyzed. The datasets are released publicly, anticipating that they would contribute to a better understanding of spatial and temporal dimensions of the public discourse related to the ongoing pandemic. As per the stats, the datasets (Lamsal 2020a, 2020b) have been accessed over 74.5k times, collectively.
截至2020年7月17日,已有超过1300万人被确诊感染新型冠状病毒(COVID-19),50万人已因这种传染病丧生。2020年3月11日,世界卫生组织宣布COVID-19疫情为大流行病。自那时以来,社交媒体平台上与该疫情相关的内容呈指数级增长。过去,人们发现推特数据在提取与任何危机相关的态势感知信息方面不可或缺。本文介绍了COV19Tweets数据集(拉姆萨尔,2020a),这是一个大规模的推特数据集,包含超过3.1亿条与COVID-19相关的英语推文及其情感得分。还介绍了该数据集的地理版本,即GeoCOV19Tweets数据集(拉姆萨尔,2020b)。本文详细讨论了数据集的设计,并对两个数据集中的推文进行了分析。这些数据集已公开发布,预计它们将有助于更好地理解与当前疫情相关的公众话语的时空维度。据统计,这些数据集(拉姆萨尔,2020a,2020b)总共被访问了超过74500次。