Annu Int Conf IEEE Eng Med Biol Soc. 2021 Nov;2021:2413-2418. doi: 10.1109/EMBC46164.2021.9630199.
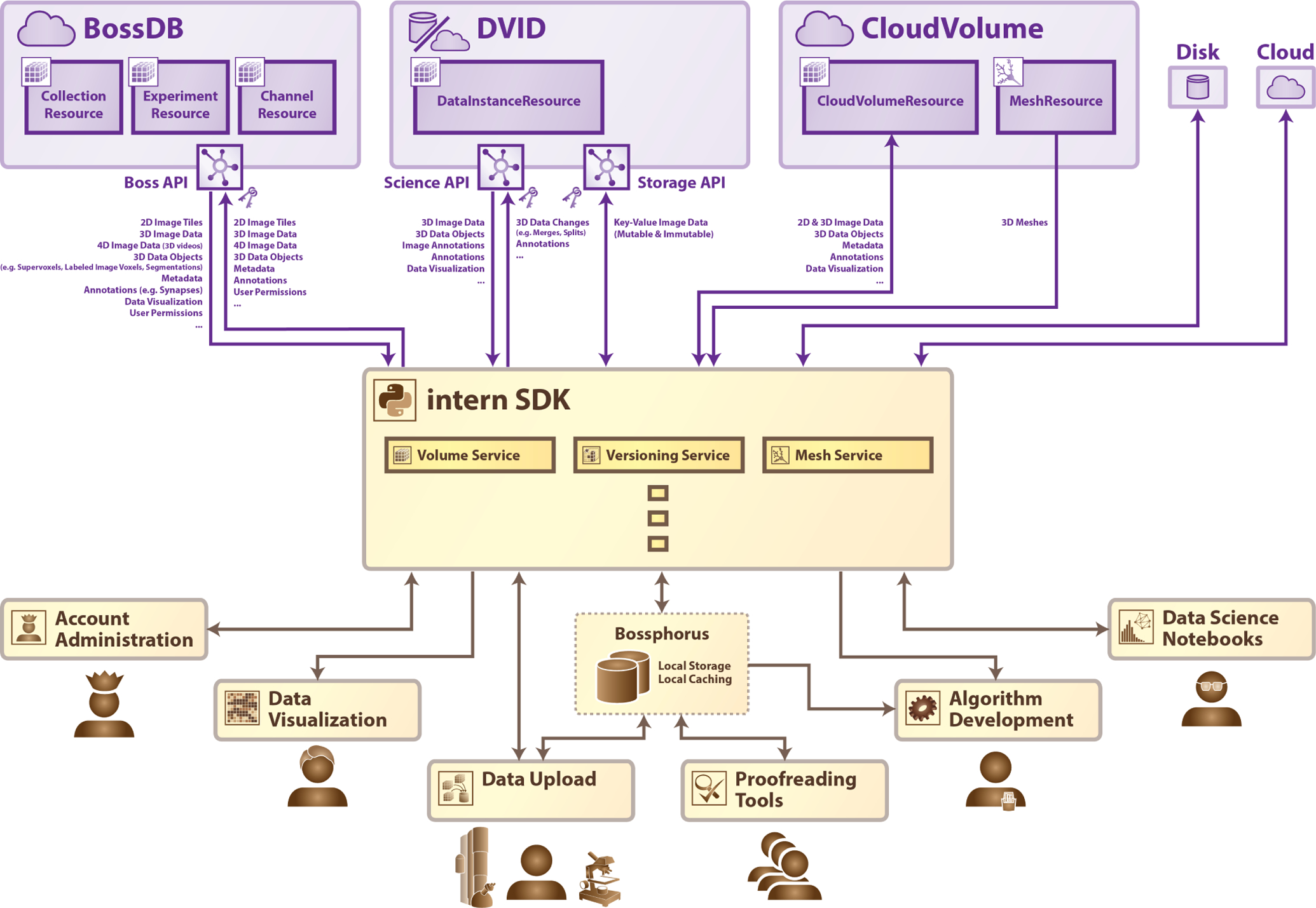
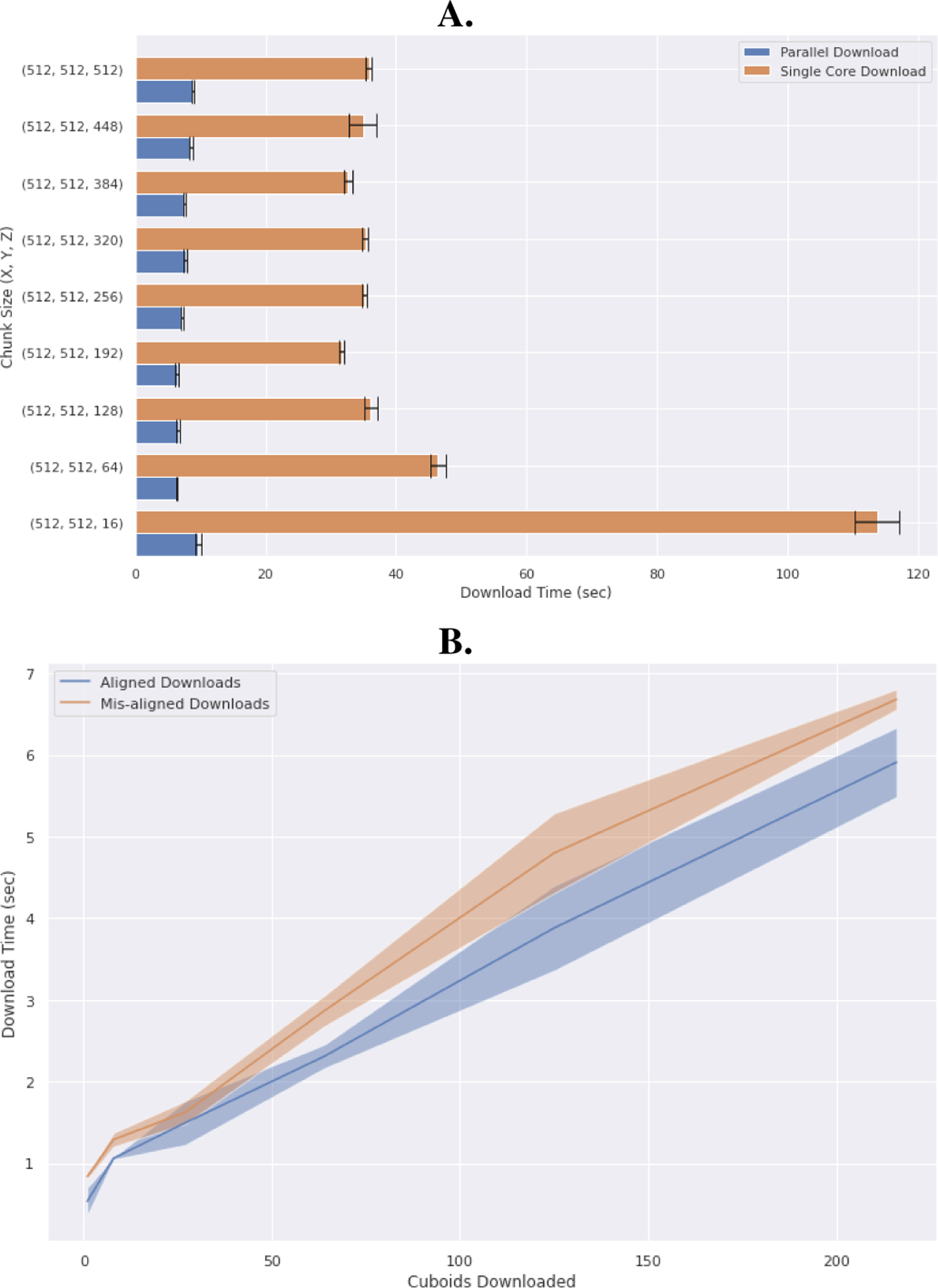
As neuroimagery datasets continue to grow in size, the complexity of data analyses can require a detailed understanding and implementation of systems computer science for storage, access, processing, and sharing. Currently, several general data standards (e.g., Zarr, HDF5, precomputed) and purpose-built ecosystems (e.g., BossDB, CloudVolume, DVID, and Knossos) exist. Each of these systems has advantages and limitations and is most appropriate for different use cases. Using datasets that don't fit into RAM in this heterogeneous environment is challenging, and significant barriers exist to leverage underlying research investments. In this manuscript, we outline our perspective for how to approach this challenge through the use of community provided, standardized interfaces that unify various computational backends and abstract computer science challenges from the scientist. We introduce desirable design patterns and share our reference implementation called intern.
随着神经影像学数据集的规模不断增长,数据分析的复杂性可能需要深入了解和实施系统计算机科学,以实现存储、访问、处理和共享。目前,有几个通用的数据标准(例如 Zarr、HDF5、预先计算)和专门构建的生态系统(例如 BossDB、CloudVolume、DVID 和 Knossos)。这些系统中的每一个都有优点和局限性,最适合不同的用例。在这个异构环境中使用无法装入 RAM 的数据集具有挑战性,并且在利用基础研究投资方面存在重大障碍。在本文中,我们通过使用社区提供的标准化接口来概述我们解决此挑战的方法,这些接口统一了各种计算后端,并为科学家抽象了计算机科学方面的挑战。我们介绍了理想的设计模式,并分享了我们的参考实现 intern。