Akinyelu Andronicus A, Blignaut Pieter
Department of Computer Science and Informatics, Faculty of Natural and Agricultural Sciences, University of the Free State, Bloemfontein, South Africa.
Front Artif Intell. 2022 Jan 26;4:796825. doi: 10.3389/frai.2021.796825. eCollection 2021.
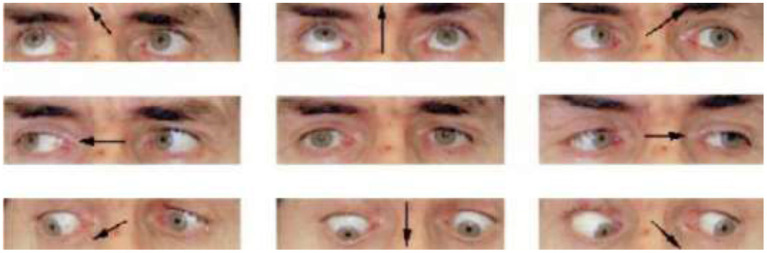
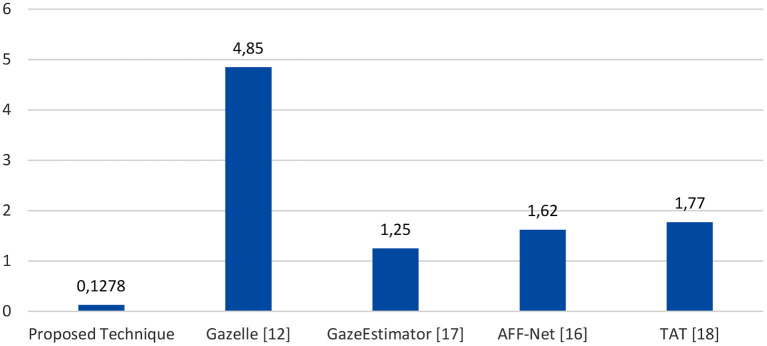
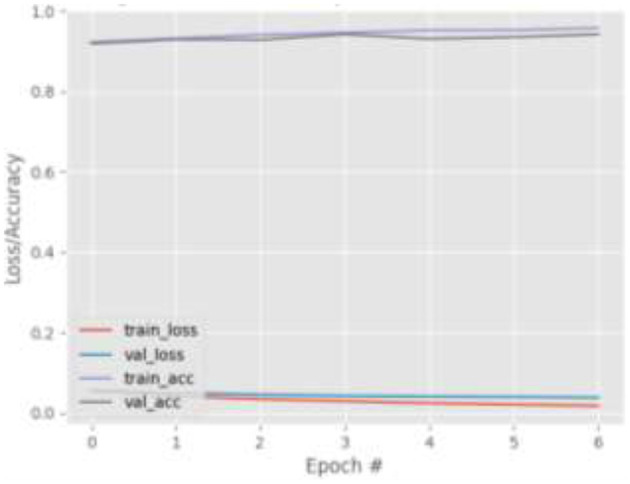
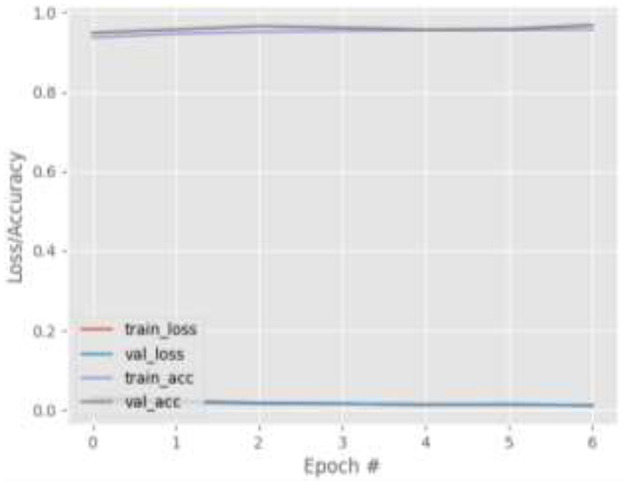
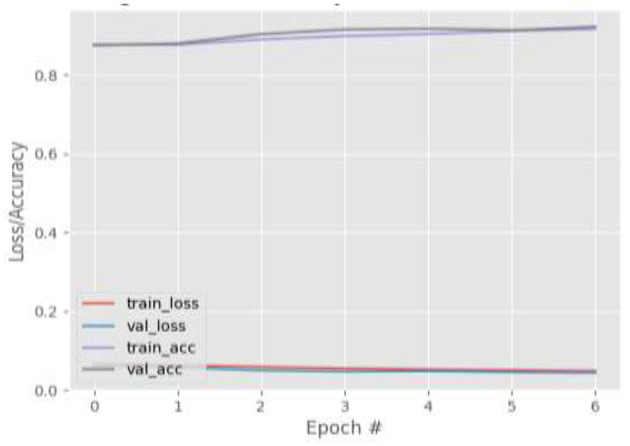
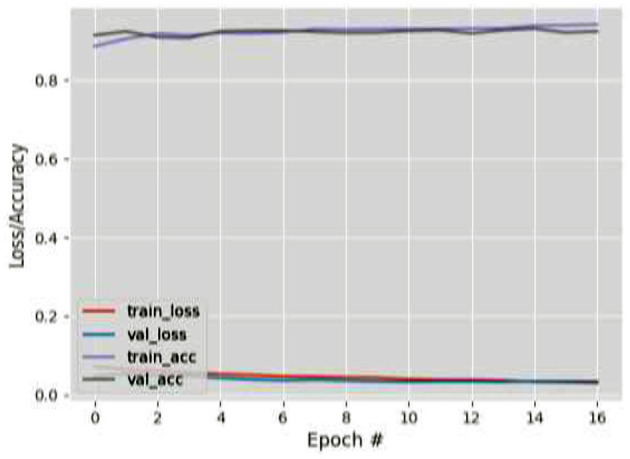
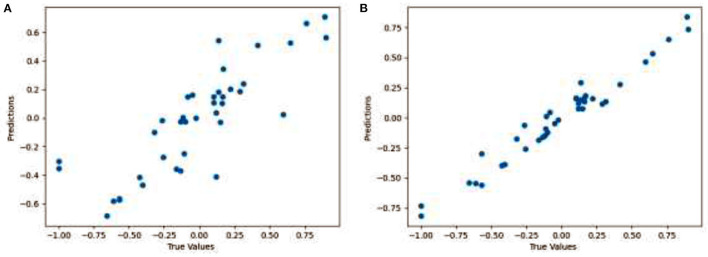
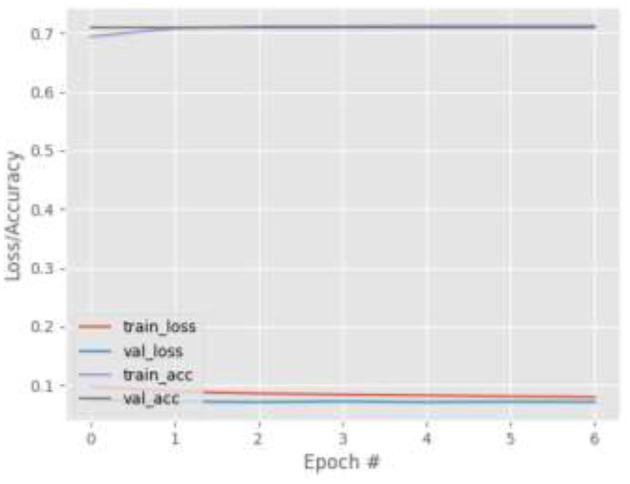
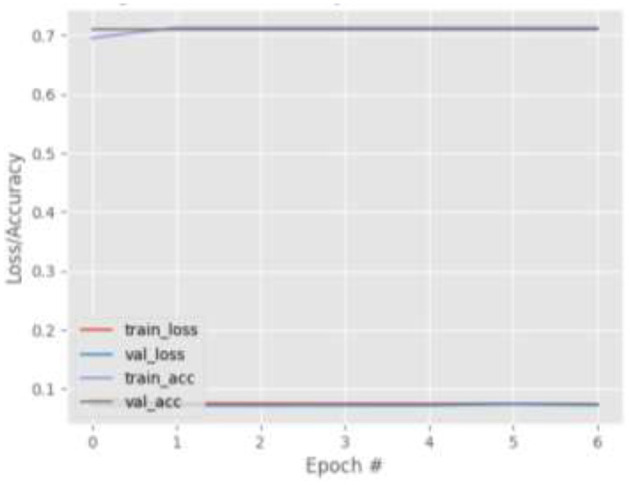
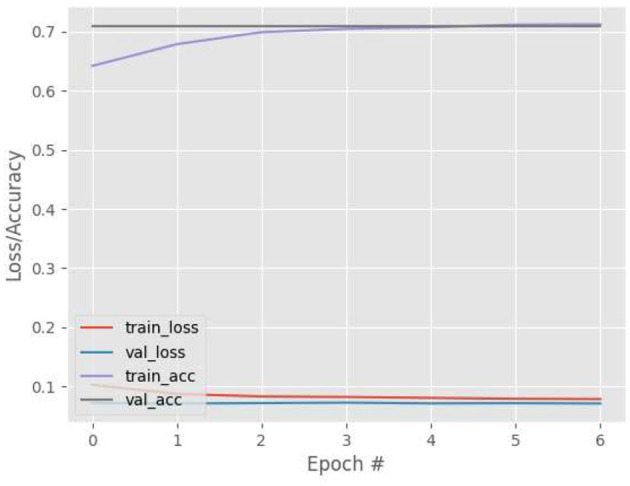
Eye tracking is becoming a very popular, useful, and important technology. Many eye tracking technologies are currently expensive and only available to large corporations. Some of them necessitate explicit personal calibration, which makes them unsuitable for use in real-world or uncontrolled environments. Explicit personal calibration can also be cumbersome and degrades the user experience. To address these issues, this study proposes a Convolutional Neural Network (CNN) based calibration-free technique for improved gaze estimation in unconstrained environments. The proposed technique consists of two components, namely a face component and a 39-point facial landmark component. The face component is used to extract the gaze estimation features from the eyes, while the 39-point facial landmark component is used to encode the shape and location of the eyes (within the face) into the network. Adding this information can make the network learn free-head and eye movements. Another CNN model was designed in this study primarily for the sake of comparison. The CNN model accepts only the face images as input. Different experiments were performed, and the experimental result reveals that the proposed technique outperforms the second model. Fine-tuning was also performed using the VGG16 pre-trained model. Experimental results show that the fine-tuned results of the proposed technique perform better than the fine-tuned results of the second model. Overall, the results show that 39-point facial landmarks can be used to improve the performance of CNN-based gaze estimation models.
眼动追踪正成为一项非常流行、实用且重要的技术。目前,许多眼动追踪技术价格昂贵,只有大公司才能使用。其中一些技术需要进行明确的个人校准,这使得它们不适用于现实世界或不受控制的环境。明确的个人校准也可能很麻烦,并会降低用户体验。为了解决这些问题,本研究提出了一种基于卷积神经网络(CNN)的免校准技术,以在无约束环境中改进注视估计。所提出的技术由两个组件组成,即面部组件和39点面部地标组件。面部组件用于从眼睛中提取注视估计特征,而39点面部地标组件用于将眼睛(在面部内)的形状和位置编码到网络中。添加此信息可以使网络学习头部和眼睛的自由移动。本研究还设计了另一个CNN模型,主要用于比较。该CNN模型仅接受面部图像作为输入。进行了不同的实验,实验结果表明所提出的技术优于第二个模型。还使用预训练的VGG16模型进行了微调。实验结果表明,所提出技术的微调结果比第二个模型的微调结果表现更好。总体而言,结果表明39点面部地标可用于提高基于CNN的注视估计模型的性能。