From the Department of Epidemiology and Biostatistics, Schulich School of Medicine & Dentistry, Western University, London, ON, Canada.
Department of Computer Science, Faculty of Science, Western University, London, ON, Canada.
Epidemiology. 2022 May 1;33(3):395-405. doi: 10.1097/EDE.0000000000001466.
Intersectionality theoretical frameworks have been increasingly incorporated into quantitative research. A range of methods have been applied to describing outcomes and disparities across large numbers of intersections of social identities or positions, with limited evaluation.
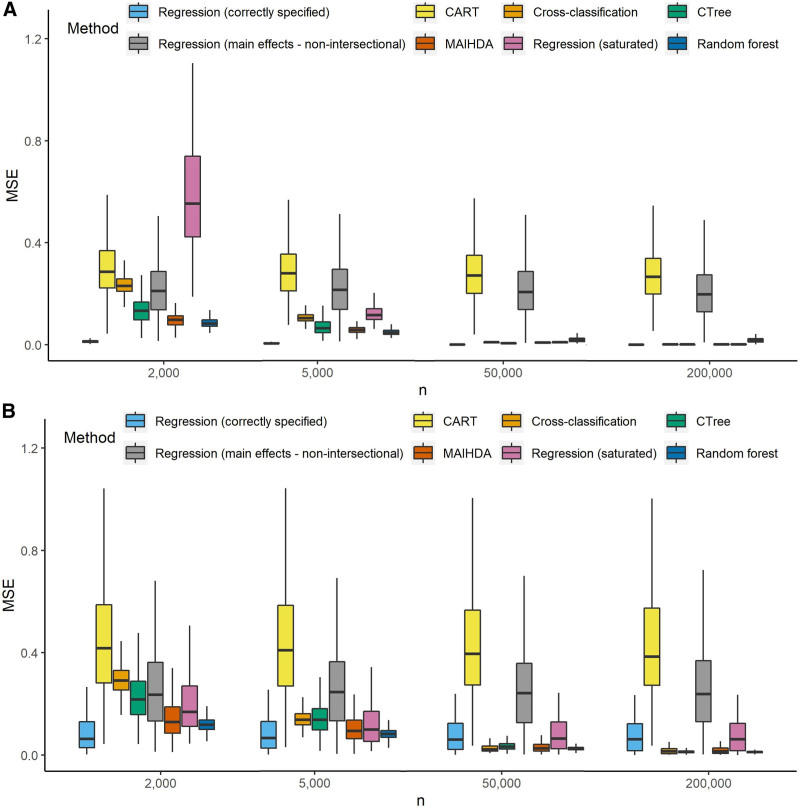
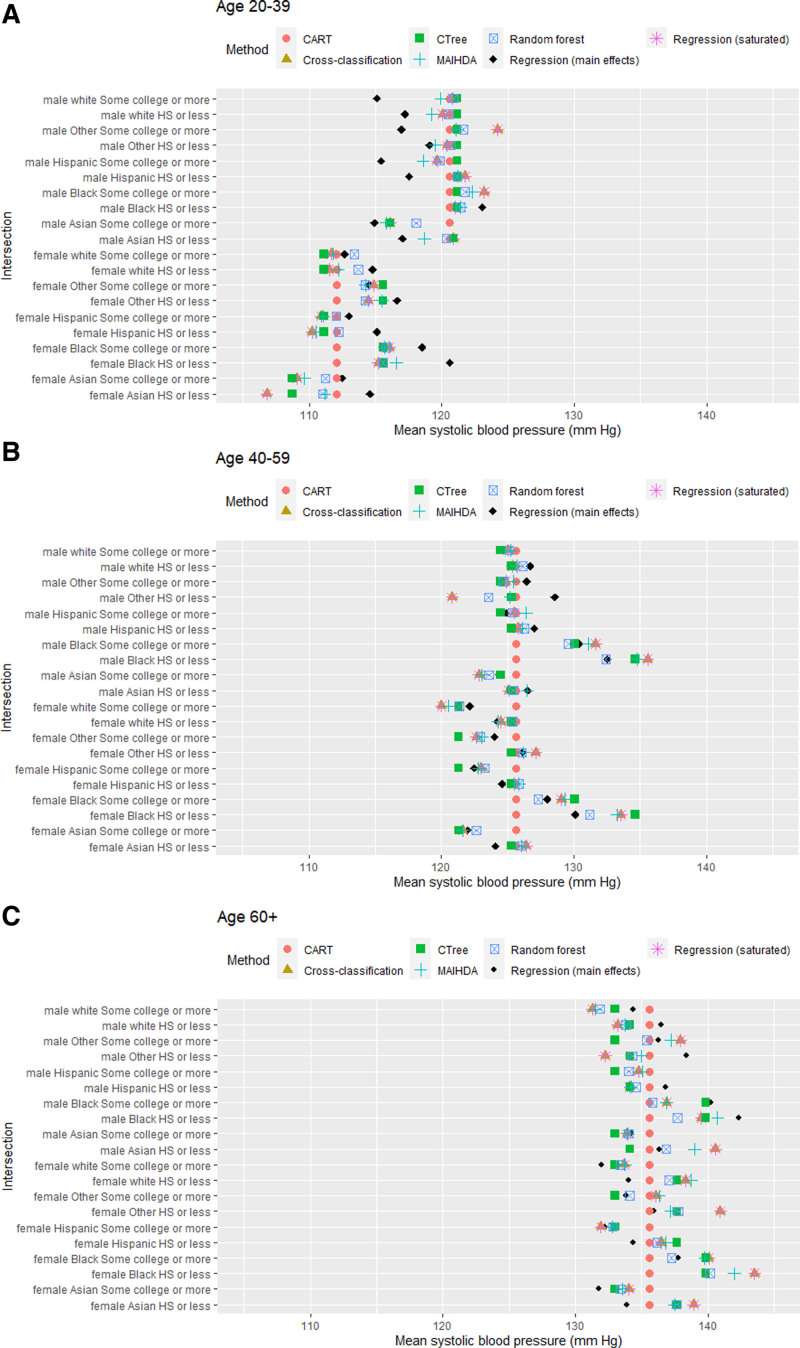
Using data simulated to reflect plausible epidemiologic data scenarios, we evaluated methods for intercategorical intersectional analysis of continuous outcomes, including cross-classification, regression with interactions, multilevel analysis of individual heterogeneity (MAIHDA), and decision-tree methods (classification and regression trees [CART], conditional inference trees [CTree], random forest). The primary outcome was estimation accuracy of intersection-specific means. We applied each method to an illustrative example using National Health and Nutrition Examination Study (NHANES) systolic blood pressure data.
When studying high-dimensional intersections at smaller sample sizes, MAIHDA, CTree, and random forest produced more accurate estimates. In large samples, all methods performed similarly except CART, which produced less accurate estimates. For variable selection, CART performed poorly across sample sizes, although random forest performed best. The NHANES example demonstrated that different methods resulted in meaningful differences in systolic blood pressure estimates, highlighting the importance of selecting appropriate methods.
This study evaluates some of a growing toolbox of methods for describing intersectional health outcomes and disparities. We identified more accurate methods for estimating outcomes for high-dimensional intersections across different sample sizes. As estimation is rarely the only objective for epidemiologists, we highlight different outputs each method creates, and suggest the sequential pairing of methods as a strategy for overcoming certain technical challenges.
交叉性理论框架已越来越多地被纳入定量研究中。已经应用了多种方法来描述大量社会身份或地位交叉点的连续结果和差异,但是评估的范围有限。
我们使用模拟数据来反映合理的流行病学数据情况,评估了用于连续结果的交叉分类分析的方法,包括交叉分类、具有交互作用的回归、个体异质性的多层次分析(MAIHDA)和决策树方法(分类和回归树[CART]、条件推断树[CTree]、随机森林)。主要结果是交叉特定平均值的估计准确性。我们使用国家健康和营养检查调查(NHANES)收缩压数据的示例来应用每种方法。
当在较小的样本量下研究高维交叉时,MAIHDA、CTree 和随机森林产生了更准确的估计。在大样本中,除了 CART 外,所有方法的性能都相似,CART 产生的估计值不太准确。对于变量选择,CART 在所有样本量下的性能都很差,尽管随机森林的性能最好。NHANES 示例表明,不同的方法导致收缩压估计值有明显差异,强调了选择适当方法的重要性。
本研究评估了一些用于描述交叉健康结果和差异的不断增长的工具包中的方法。我们确定了用于在不同样本量下估计高维交叉结果的更准确的方法。由于估计很少是流行病学家的唯一目标,因此我们突出了每种方法创建的不同输出,并建议将方法依次配对作为克服某些技术挑战的策略。