Enveda Biosciences, Boulder, Colorado, United States of America.
Bonn-Aachen International Center for IT, Rheinische Friedrich-Wilhelms-Universität Bonn, Bonn, Germany.
PLoS Comput Biol. 2022 Feb 25;18(2):e1009909. doi: 10.1371/journal.pcbi.1009909. eCollection 2022 Feb.
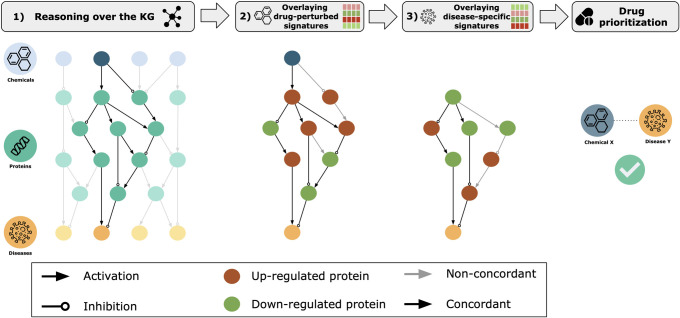
Network-based approaches are becoming increasingly popular for drug discovery as they provide a systems-level overview of the mechanisms underlying disease pathophysiology. They have demonstrated significant early promise over other methods of biological data representation, such as in target discovery, side effect prediction and drug repurposing. In parallel, an explosion of -omics data for the deep characterization of biological systems routinely uncovers molecular signatures of disease for similar applications. Here, we present RPath, a novel algorithm that prioritizes drugs for a given disease by reasoning over causal paths in a knowledge graph (KG), guided by both drug-perturbed as well as disease-specific transcriptomic signatures. First, our approach identifies the causal paths that connect a drug to a particular disease. Next, it reasons over these paths to identify those that correlate with the transcriptional signatures observed in a drug-perturbation experiment, and anti-correlate to signatures observed in the disease of interest. The paths which match this signature profile are then proposed to represent the mechanism of action of the drug. We demonstrate how RPath consistently prioritizes clinically investigated drug-disease pairs on multiple datasets and KGs, achieving better performance over other similar methodologies. Furthermore, we present two case studies showing how one can deconvolute the predictions made by RPath as well as predict novel targets.
基于网络的方法在药物发现中越来越受欢迎,因为它们提供了疾病病理生理学背后机制的系统级概述。与其他生物数据表示方法(如靶点发现、副作用预测和药物重定位)相比,它们具有显著的早期优势。与此同时,大量的组学数据也在蓬勃发展,用于对生物系统进行深入表征,这些数据通常会为类似的应用揭示疾病的分子特征。在这里,我们提出了 RPath,这是一种新颖的算法,通过在知识图谱(KG)中推理因果路径,同时考虑药物扰动和疾病特异性转录组特征,为给定的疾病对药物进行优先级排序。首先,我们的方法确定将药物与特定疾病联系起来的因果路径。接下来,它会根据这些路径推断出与药物扰动实验中观察到的转录本特征相关且与感兴趣疾病中的特征相反的那些路径。然后,将与该签名配置文件匹配的路径提议为药物的作用机制。我们证明了 RPath 如何在多个数据集和 KG 上一致地对经过临床研究的药物-疾病对进行优先级排序,并且比其他类似方法具有更好的性能。此外,我们还展示了两个案例研究,展示了如何分解 RPath 的预测以及预测新的靶点。