Massachusetts Institute of Technology, Cambridge, MA, USA.
Broad Institute of MIT and Harvard, Cambridge, MA, USA.
Nature. 2022 Mar;603(7901):455-463. doi: 10.1038/s41586-022-04506-6. Epub 2022 Mar 9.
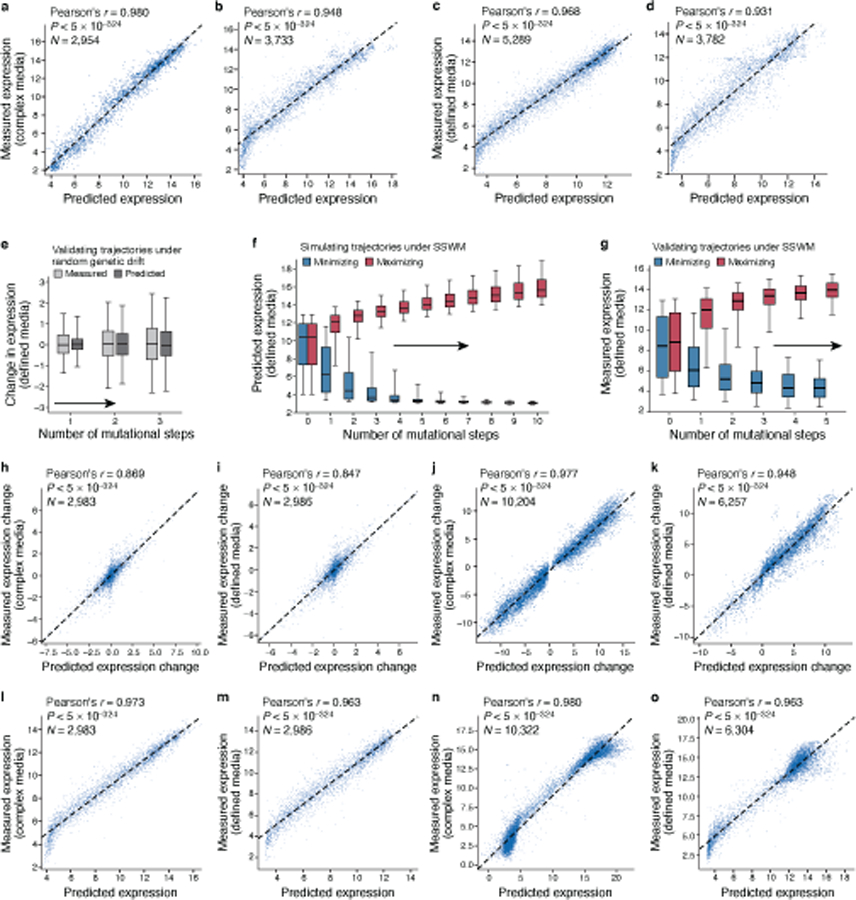
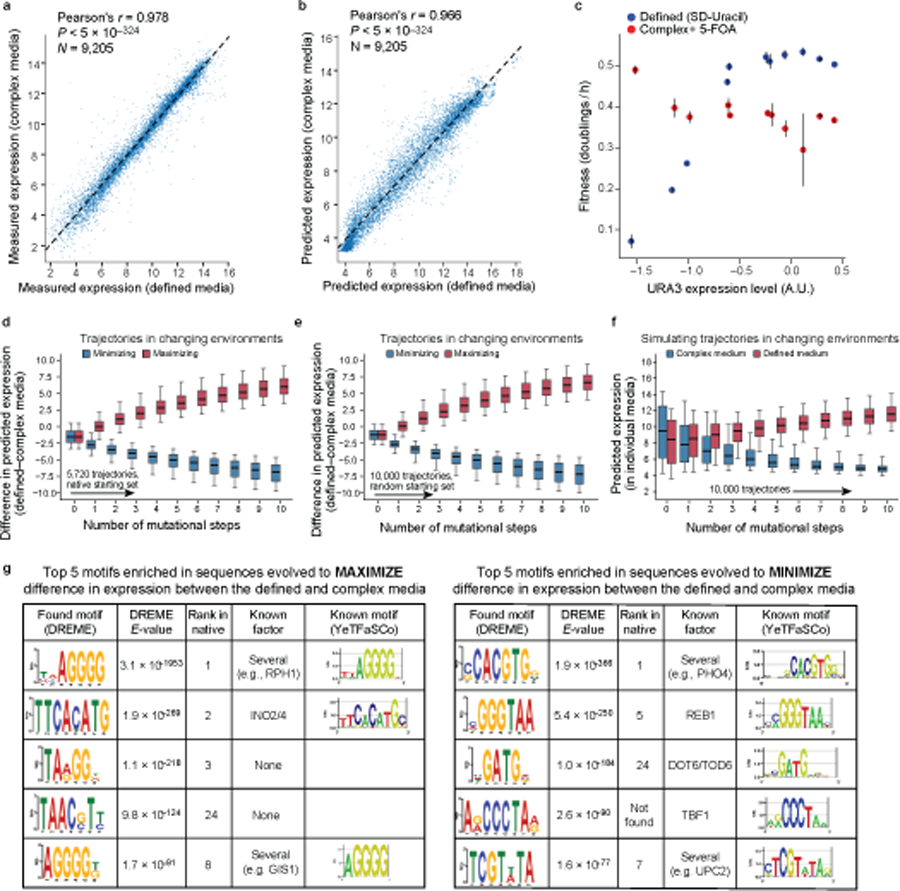
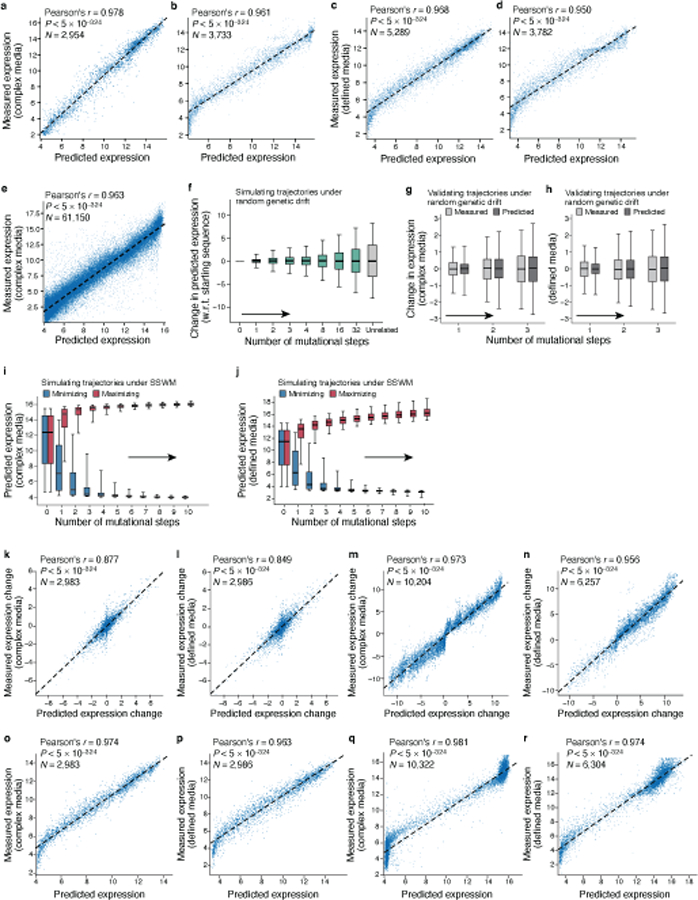
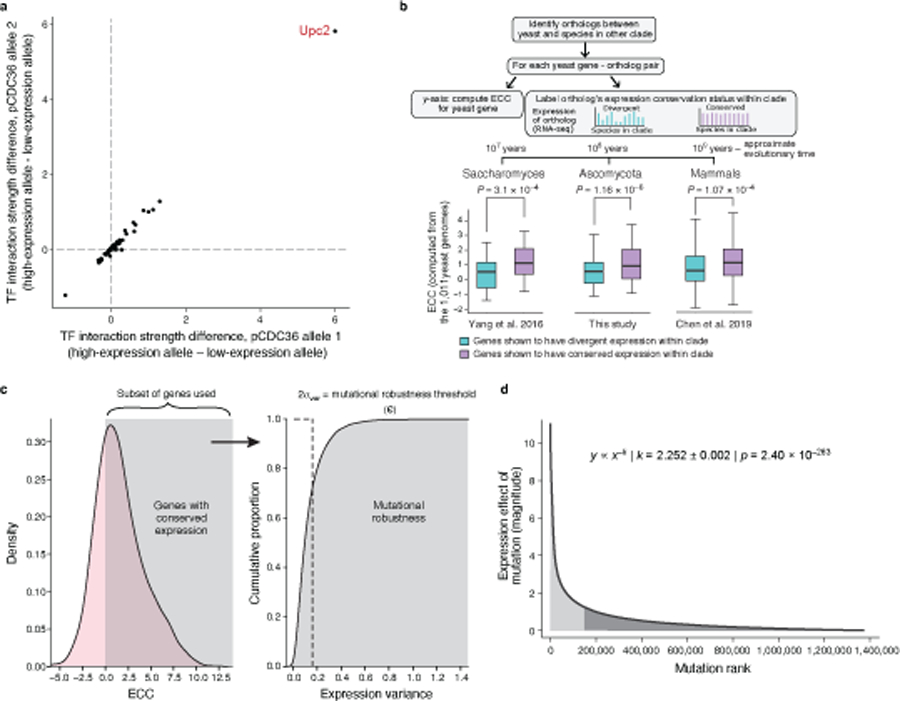
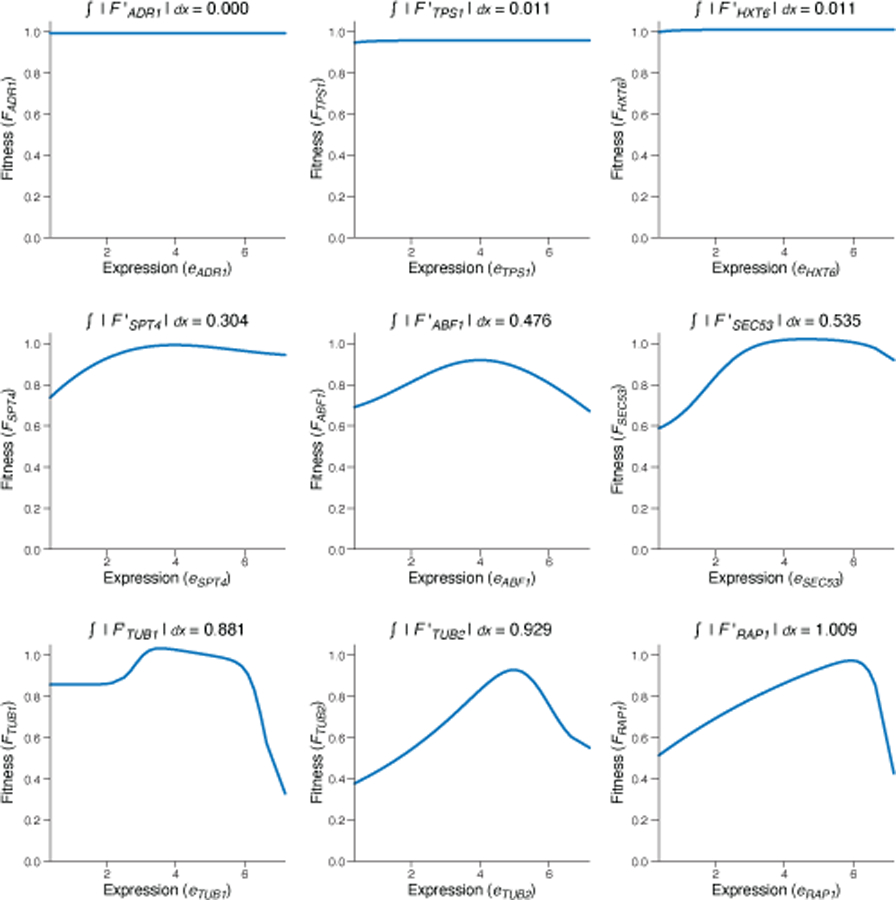
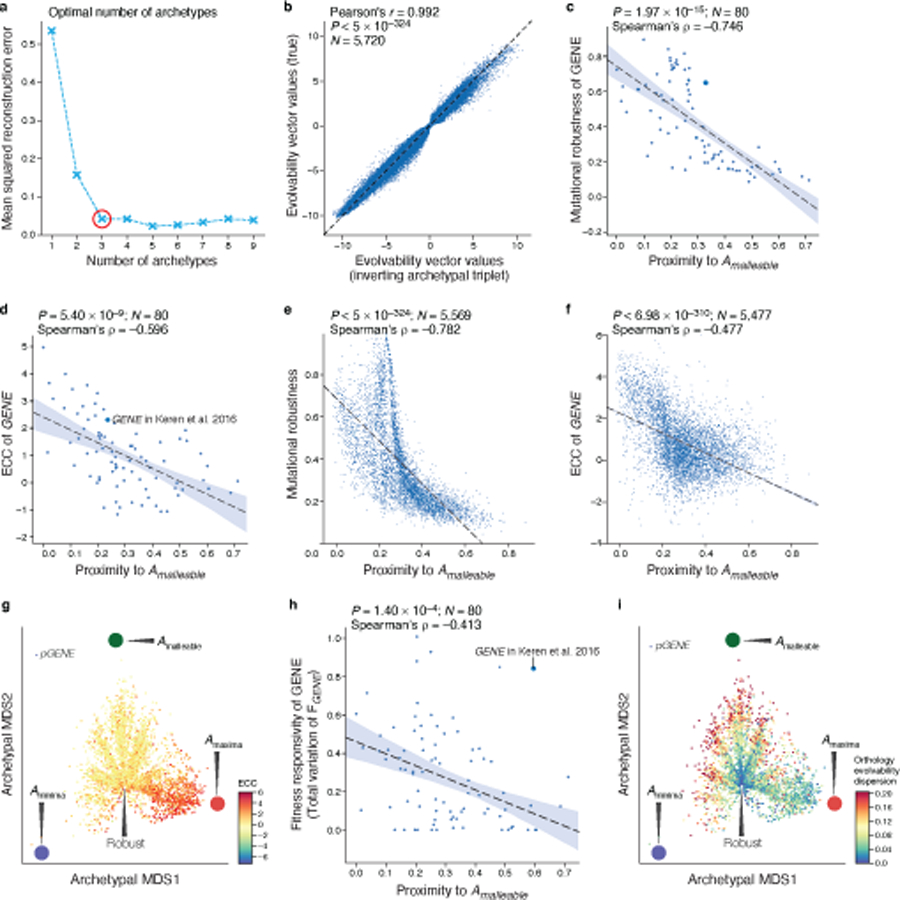
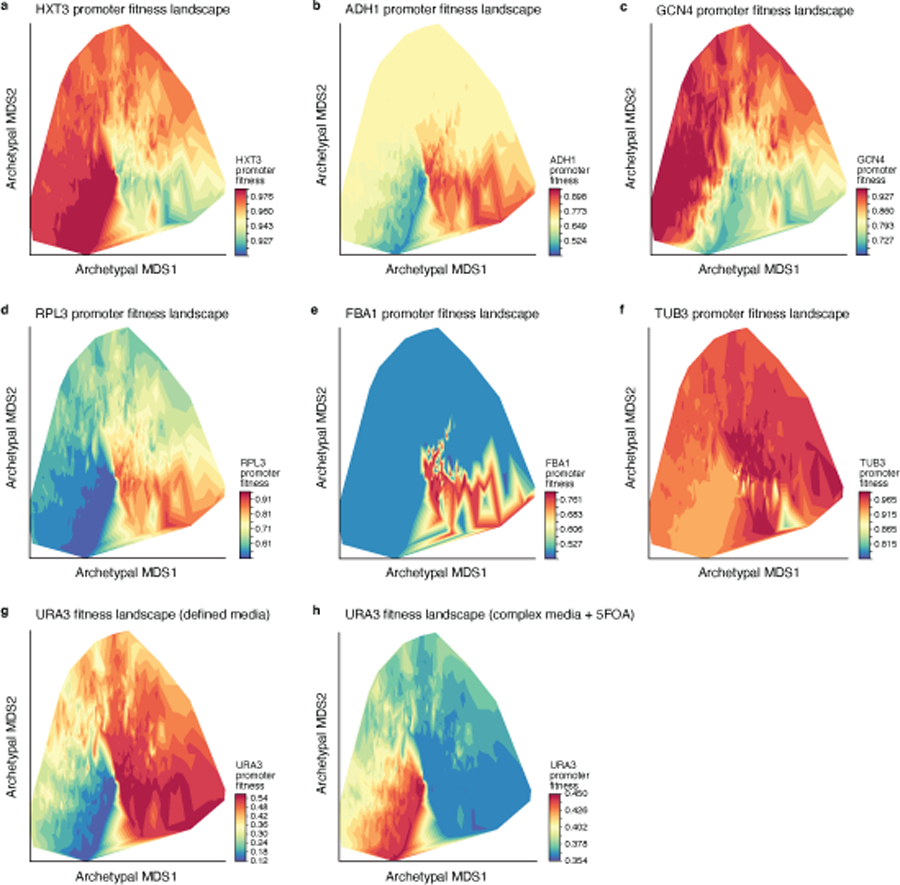
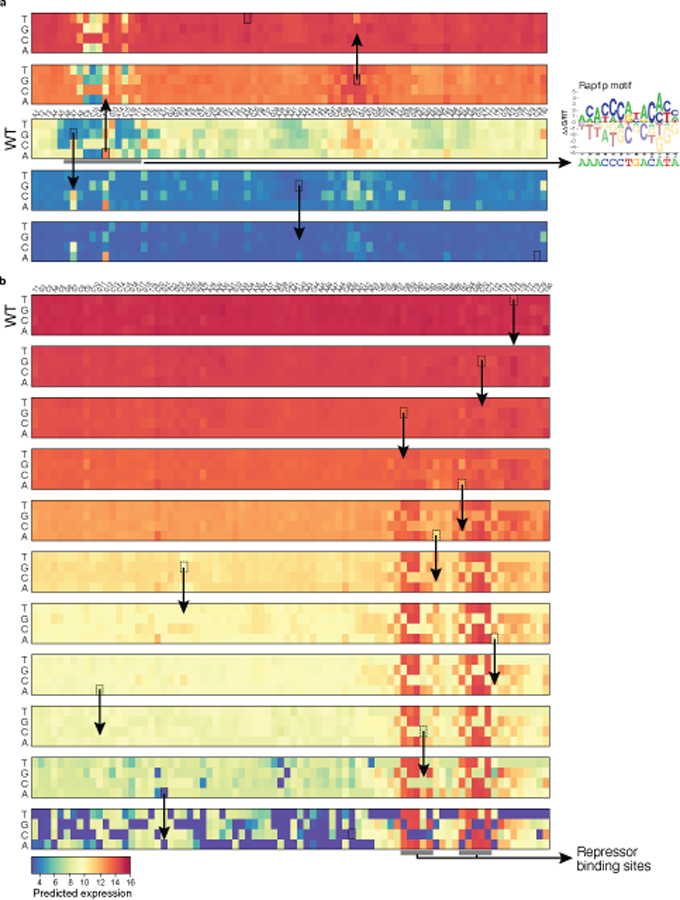
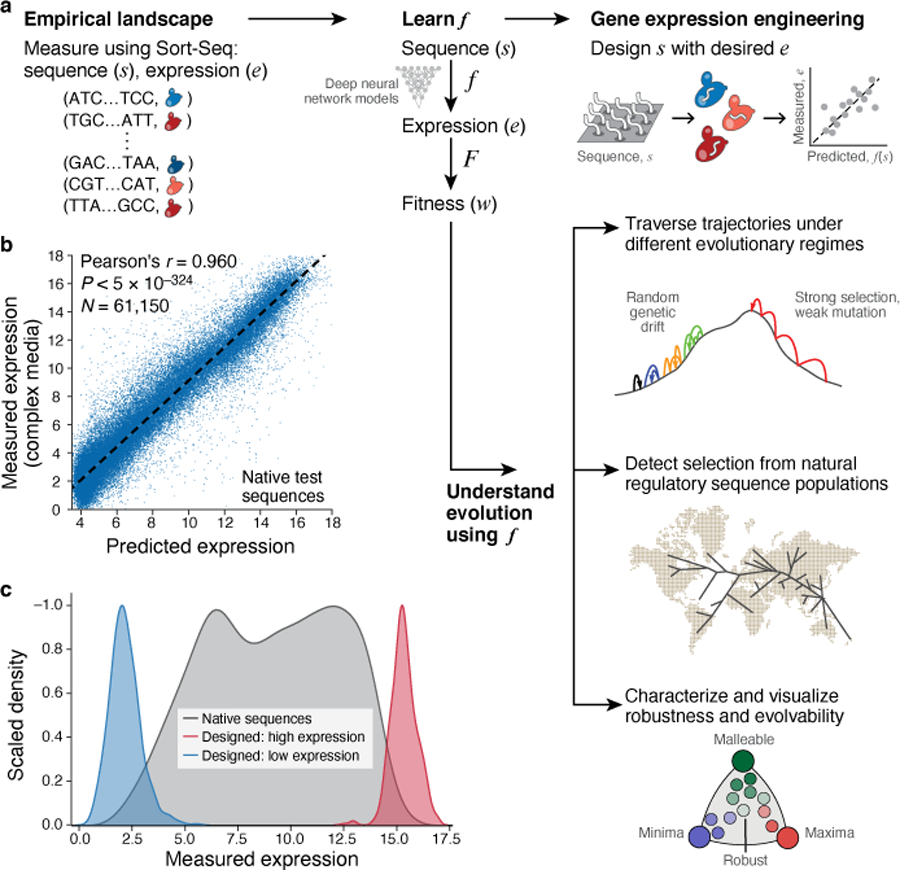
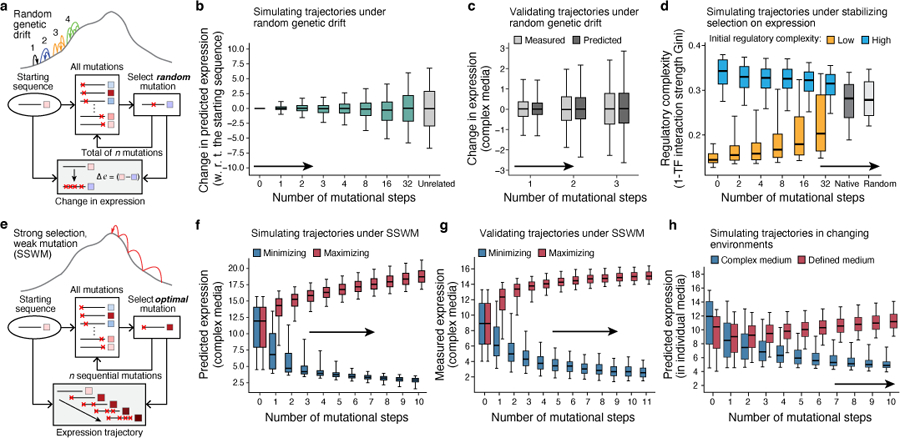
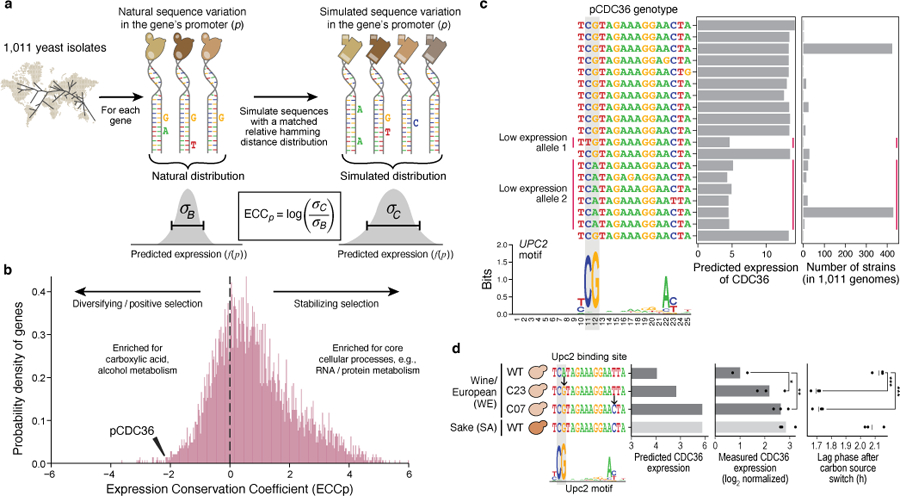
Mutations in non-coding regulatory DNA sequences can alter gene expression, organismal phenotype and fitness. Constructing complete fitness landscapes, in which DNA sequences are mapped to fitness, is a long-standing goal in biology, but has remained elusive because it is challenging to generalize reliably to vast sequence spaces. Here we build sequence-to-expression models that capture fitness landscapes and use them to decipher principles of regulatory evolution. Using millions of randomly sampled promoter DNA sequences and their measured expression levels in the yeast Saccharomyces cerevisiae, we learn deep neural network models that generalize with excellent prediction performance, and enable sequence design for expression engineering. Using our models, we study expression divergence under genetic drift and strong-selection weak-mutation regimes to find that regulatory evolution is rapid and subject to diminishing returns epistasis; that conflicting expression objectives in different environments constrain expression adaptation; and that stabilizing selection on gene expression leads to the moderation of regulatory complexity. We present an approach for using such models to detect signatures of selection on expression from natural variation in regulatory sequences and use it to discover an instance of convergent regulatory evolution. We assess mutational robustness, finding that regulatory mutation effect sizes follow a power law, characterize regulatory evolvability, visualize promoter fitness landscapes, discover evolvability archetypes and illustrate the mutational robustness of natural regulatory sequence populations. Our work provides a general framework for designing regulatory sequences and addressing fundamental questions in regulatory evolution.
非编码调控 DNA 序列中的突变可以改变基因表达、生物个体表型和适应度。构建完整的适应度景观,即将 DNA 序列映射到适应度,是生物学中长期以来的目标,但由于难以可靠地推广到广阔的序列空间,因此仍然难以实现。在这里,我们构建了可以捕捉适应度景观的序列到表达模型,并利用它们来揭示调控进化的原理。我们使用了数百万个随机采样的启动子 DNA 序列及其在酵母酿酒酵母中的测量表达水平,学习了深度神经网络模型,这些模型具有出色的预测性能,并且可以进行序列设计以进行表达工程。使用我们的模型,我们研究了遗传漂变和强选择弱突变条件下的表达分歧,发现调控进化是快速的,并受到递减回报的上位性限制;不同环境中的表达目标冲突限制了表达适应;以及基因表达的稳定选择导致调节复杂性的缓和。我们提出了一种使用此类模型从调控序列中的自然变异中检测表达选择的方法,并使用它发现了一个趋同调控进化的实例。我们评估了突变稳健性,发现调节突变效应大小遵循幂律,表征了调节可进化性,可视化了启动子适应度景观,发现了可进化原型,并说明了自然调节序列群体的突变稳健性。我们的工作为设计调控序列提供了一个通用框架,并解决了调控进化中的基本问题。