Castro Dopico Xaquin, Muschiol Sandra, Grinberg Nastasiya F, Aleman Soo, Sheward Daniel J, Hanke Leo, Ahl Marcus, Vikström Linnea, Forsell Mattias, Coquet Jonathan M, McInerney Gerald, Dillner Joakim, Bogdanovic Gordana, Murrell Ben, Albert Jan, Wallace Chris, Karlsson Hedestam Gunilla B
Department of Microbiology, Tumor and Cell Biology Karolinska Institutet Stockholm Sweden.
Department of Clinical Microbiology Karolinska University Hospital Stockholm Sweden.
Clin Transl Immunology. 2022 Mar 2;11(3):e1379. doi: 10.1002/cti2.1379. eCollection 2022.
Population-level measures of seropositivity are critical for understanding the epidemiology of an emerging pathogen, yet most antibody tests apply a strict cutoff for seropositivity that is not learnt in a data-driven manner, leading to uncertainty when classifying low-titer responses. To improve upon this, we evaluated cutoff-independent methods for their ability to assign likelihood of SARS-CoV-2 seropositivity to individual samples.
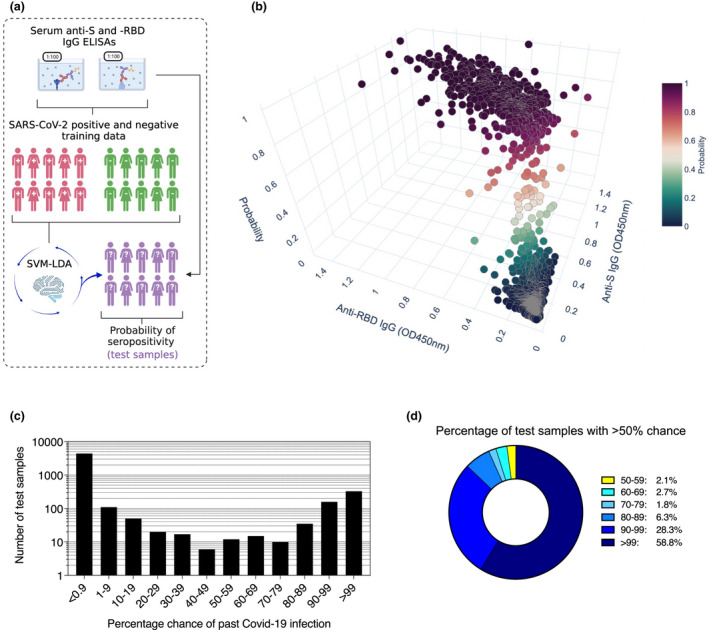
Using robust ELISAs based on SARS-CoV-2 spike (S) and the receptor-binding domain (RBD), we profiled antibody responses in a group of SARS-CoV-2 PCR+ individuals ( = 138). Using these data, we trained probabilistic learners to assign likelihood of seropositivity to test samples of unknown serostatus ( = 5100), identifying a support vector machines-linear discriminant analysis learner (SVM-LDA) suited for this purpose.
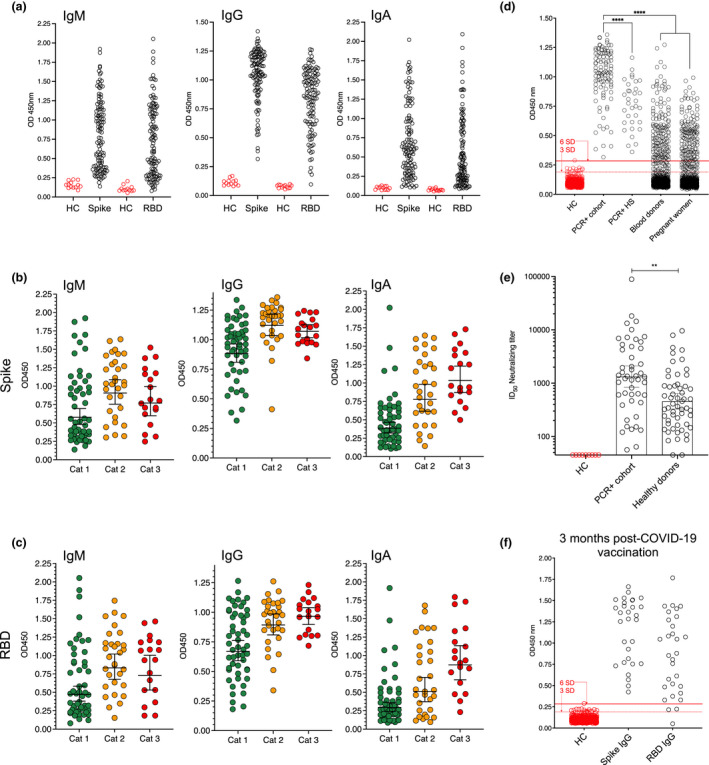
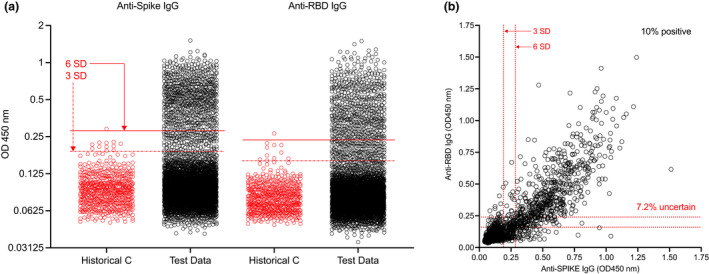
In the training data from confirmed ancestral SARS-CoV-2 infections, 99% of participants had detectable anti-S and -RBD IgG in the circulation, with titers differing > 1000-fold between persons. In data of otherwise healthy individuals, 7.2% (367) of samples were of uncertain serostatus, with values in the range of 3-6SD from the mean of pre-pandemic negative controls ( = 595). In contrast, SVM-LDA classified 6.4% ( = 328) of test samples as having a high likelihood (> 99% chance) of past infection, 4.5% ( = 230) to have a 50-99% likelihood, and 4.0% ( = 203) to have a 10-49% likelihood. As different probabilistic approaches were more consistent with each other than conventional SD-based methods, such tools allow for more statistically-sound seropositivity estimates in large cohorts.
Probabilistic antibody testing frameworks can improve seropositivity estimates in populations with large titer variability.
群体水平的血清阳性率测量对于理解新出现病原体的流行病学至关重要,但大多数抗体检测对血清阳性采用严格的临界值,且该临界值并非通过数据驱动的方式得出,这导致在对低滴度反应进行分类时存在不确定性。为改善这一情况,我们评估了与临界值无关的方法,以确定其为个体样本赋予SARS-CoV-2血清阳性可能性的能力。
使用基于SARS-CoV-2刺突蛋白(S)和受体结合域(RBD)的稳健酶联免疫吸附测定(ELISA),我们对一组SARS-CoV-2聚合酶链反应阳性个体(n = 138)的抗体反应进行了分析。利用这些数据,我们训练概率学习器,为血清状态未知的检测样本(n = 5100)赋予血清阳性可能性,确定了一种适用于此目的的支持向量机-线性判别分析学习器(SVM-LDA)。
在确诊的原始SARS-CoV-2感染的训练数据中,99%的参与者循环中可检测到抗S和抗RBD IgG,个体之间的滴度差异超过1000倍。在其他方面健康个体的数据中,7.2%(367)的样本血清状态不确定,其值在大流行前阴性对照均值的3 - 6个标准差范围内(n = 595)。相比之下,SVM-LDA将6.4%(n = 328)的检测样本分类为过去感染可能性高(> 99%概率),4.5%(n = 230)的样本可能性为50 - 99%,4.0%(n = 203)的样本可能性为10 - 49%。由于不同的概率方法彼此之间比传统的基于标准差的方法更一致,此类工具能够在大型队列中进行更具统计学依据的血清阳性率估计。
概率性抗体检测框架可改善滴度变异性大的人群中的血清阳性率估计。