Department of Computer Science and Engineering, College of Applied Studies and Community Services, King Saud University, P.O. BOX 22459, Riyadh 11495, Saudi Arabia.
College of Computer and Information Sciences, King Saud University, P.O. Box 51178, Riyadh 11543, Saudi Arabia.
Comput Intell Neurosci. 2022 Mar 31;2022:7463091. doi: 10.1155/2022/7463091. eCollection 2022.
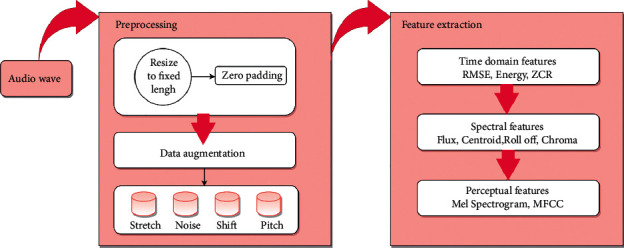
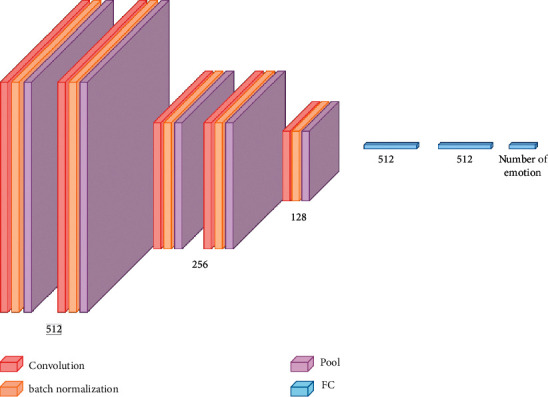
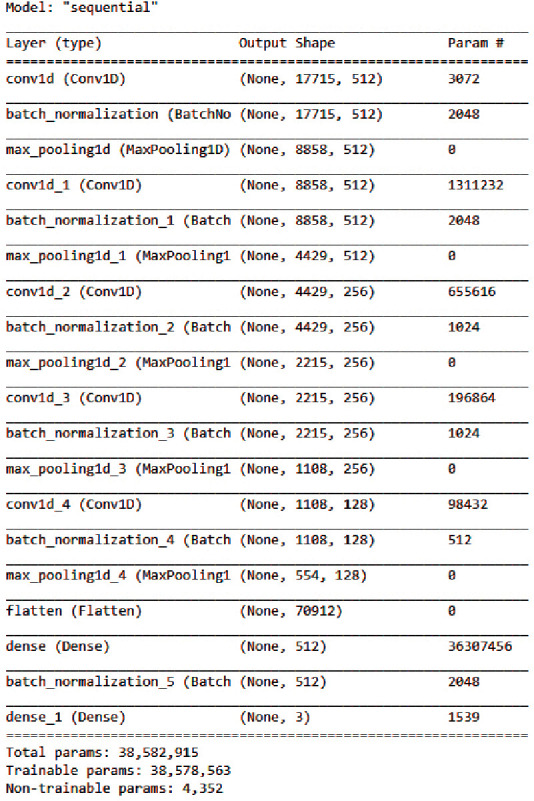
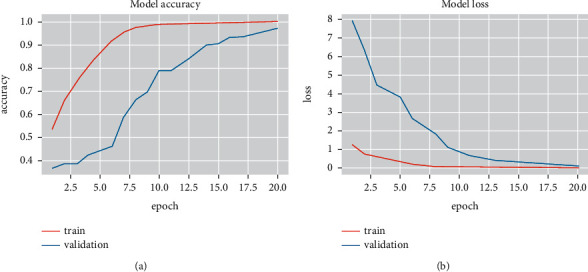
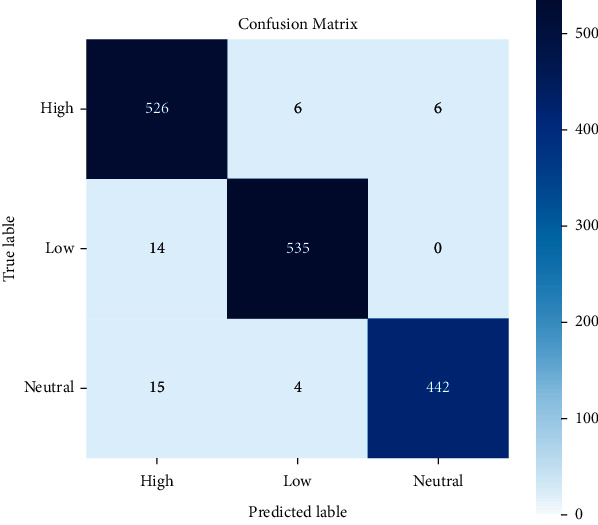
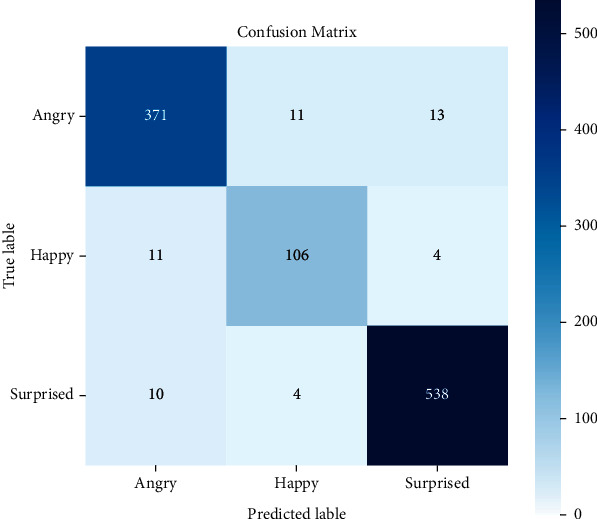
Emotions play an essential role in human relationships, and many real-time applications rely on interpreting the speaker's emotion from their words. Speech emotion recognition (SER) modules aid human-computer interface (HCI) applications, but they are challenging to implement because of the lack of balanced data for training and clarity about which features are sufficient for categorization. This research discusses the impact of the classification approach, identifying the most appropriate combination of features and data augmentation on speech emotion detection accuracy. Selection of the correct combination of handcrafted features with the classifier plays an integral part in reducing computation complexity. The suggested classification model, a 1D convolutional neural network (1D CNN), outperforms traditional machine learning approaches in classification. Unlike most earlier studies, which examined emotions primarily through a single language lens, our analysis looks at numerous language data sets. With the most discriminating features and data augmentation, our technique achieves 97.09%, 96.44%, and 83.33% accuracy for the BAVED, ANAD, and SAVEE data sets, respectively.
情绪在人际关系中起着至关重要的作用,许多实时应用程序都依赖于从说话者的话语中解释其情绪。语音情感识别 (SER) 模块辅助人机交互 (HCI) 应用程序,但由于缺乏用于训练的平衡数据以及关于哪些特征足以进行分类的问题不够明确,因此实现起来具有挑战性。本研究讨论了分类方法的影响,确定了特征和数据增强的最佳组合对语音情感检测准确性的影响。选择与分类器配合使用的手工制作特征的正确组合在降低计算复杂性方面起着不可或缺的作用。所提出的分类模型,即一维卷积神经网络 (1D CNN),在分类方面优于传统的机器学习方法。与大多数早期仅通过单一语言视角研究情绪的研究不同,我们的分析着眼于多个语言数据集。通过使用最具辨别力的特征和数据增强,我们的技术分别为 BAVED、ANAD 和 SAVEE 数据集实现了 97.09%、96.44%和 83.33%的准确率。