Department of Electrical and Computer Engineering, Ajou University, Suwon 16449, Korea.
Department of Artificial Intelligence, Ajou University, Suwon 16449, Korea.
Sensors (Basel). 2022 Mar 29;22(7):2623. doi: 10.3390/s22072623.
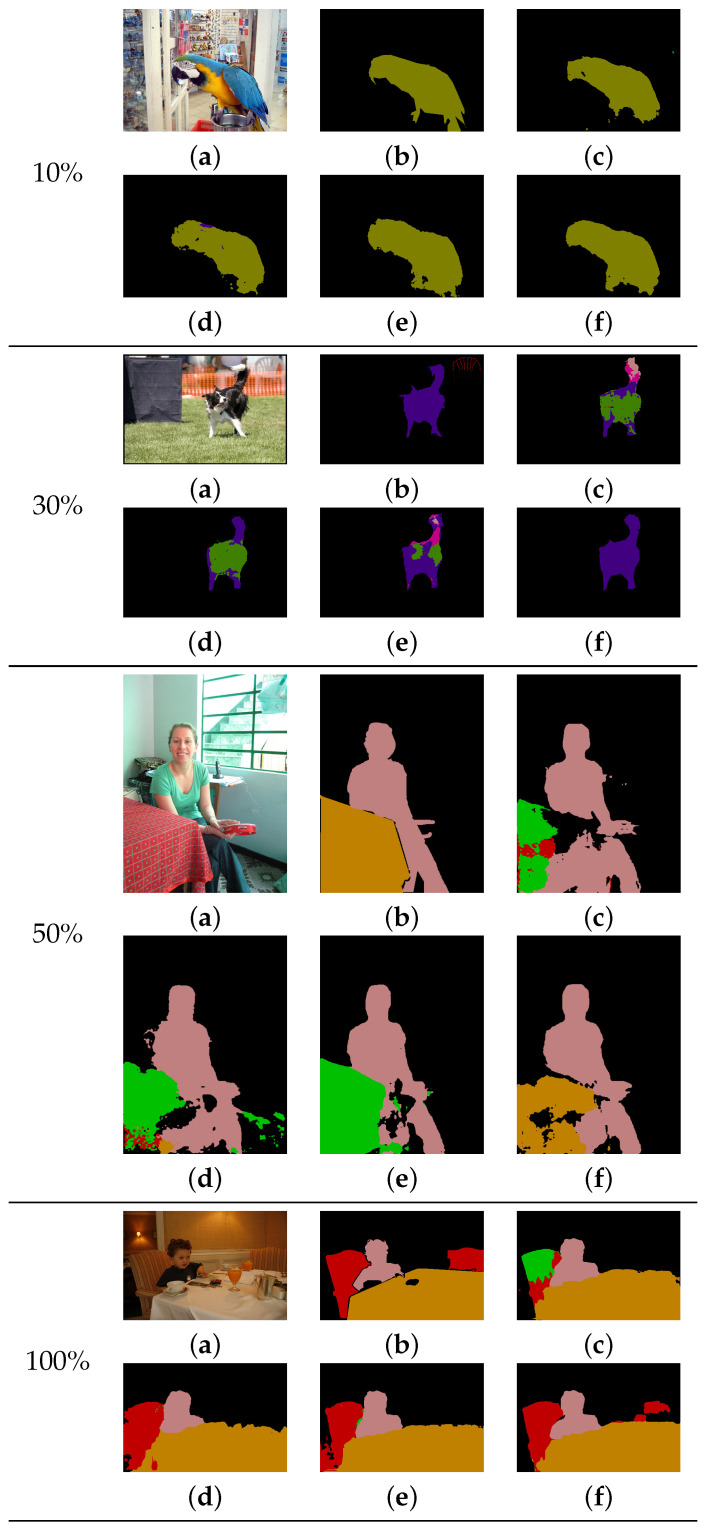
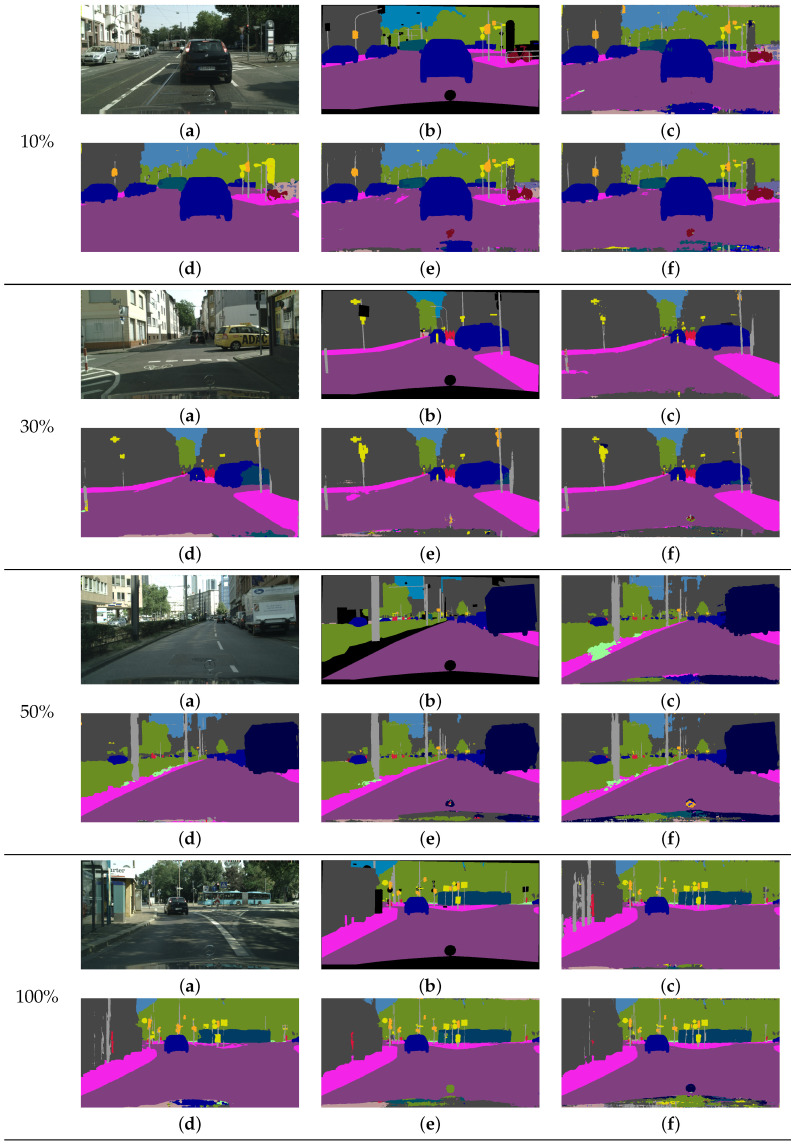
To achieve high performance, most deep convolutional neural networks (DCNNs) require a significant amount of training data with ground truth labels. However, creating ground-truth labels for semantic segmentation requires more time, human effort, and cost compared with other tasks such as classification and object detection, because the ground-truth label of every pixel in an image is required. Hence, it is practically demanding to train DCNNs using a limited amount of training data for semantic segmentation. Generally, training DCNNs using a limited amount of data is problematic as it easily results in a decrease in the accuracy of the networks because of overfitting to the training data. Here, we propose a new regularization method called pixel-wise adaptive label smoothing (PALS) via self-knowledge distillation to stably train semantic segmentation networks in a practical situation, in which only a limited amount of training data is available. To mitigate the problem caused by limited training data, our method fully utilizes the internal statistics of pixels within an input image. Consequently, the proposed method generates a pixel-wise aggregated probability distribution using a similarity matrix that encodes the affinities between all pairs of pixels. To further increase the accuracy, we add one-hot encoded distributions with ground-truth labels to these aggregated distributions, and obtain our final soft labels. We demonstrate the effectiveness of our method for the Cityscapes dataset and the Pascal VOC2012 dataset using limited amounts of training data, such as 10%, 30%, 50%, and 100%. Based on various quantitative and qualitative comparisons, our method demonstrates more accurate results compared with previous methods. Specifically, for the Cityscapes test set, our method achieved mIoU improvements of 0.076%, 1.848%, 1.137%, and 1.063% for 10%, 30%, 50%, and 100% training data, respectively, compared with the method of the cross-entropy loss using one-hot encoding with ground truth labels.
为了实现高性能,大多数深度卷积神经网络 (DCNN) 需要大量具有真实标签的训练数据。然而,与分类和目标检测等其他任务相比,创建语义分割的真实标签需要更多的时间、人力和成本,因为需要图像中每个像素的真实标签。因此,在语义分割中使用有限数量的训练数据来训练 DCNN 在实践中是非常具有挑战性的。一般来说,使用有限数量的数据训练 DCNN 存在问题,因为它容易导致网络精度下降,因为网络过度拟合训练数据。在这里,我们提出了一种新的正则化方法,称为像素自适应标签平滑 (PALS),通过自我知识蒸馏,在只有有限数量的训练数据的实际情况下稳定地训练语义分割网络。为了解决有限训练数据带来的问题,我们的方法充分利用了输入图像中像素的内部统计信息。因此,该方法使用相似度矩阵生成像素级聚合概率分布,相似度矩阵编码所有像素对之间的亲和力。为了进一步提高精度,我们将具有真实标签的 One-hot 编码分布添加到这些聚合分布中,并获得最终的软标签。我们使用有限数量的训练数据(例如 10%、30%、50%和 100%)在 Cityscapes 数据集和 Pascal VOC2012 数据集上证明了我们方法的有效性。通过各种定量和定性比较,我们的方法与以前的方法相比表现出更准确的结果。具体来说,对于 Cityscapes 测试集,我们的方法在 10%、30%、50%和 100%的训练数据下,与使用真实标签的 One-hot 编码的交叉熵损失方法相比,分别提高了 mIoU 0.076%、1.848%、1.137%和 1.063%。