Merhbene Ghofrane, Nath Sukanya, Puttick Alexandre R, Kurpicz-Briki Mascha
Applied Machine Intelligence Research Group, Department of Engineering and Information Technology, Bern University of Applied Sciences, Bern, Switzerland.
Institute for Research in Open, Distance and eLearning (IFeL), Swiss Distance University of Applied Sciences, Brig, Switzerland.
Front Big Data. 2022 Apr 5;5:863100. doi: 10.3389/fdata.2022.863100. eCollection 2022.
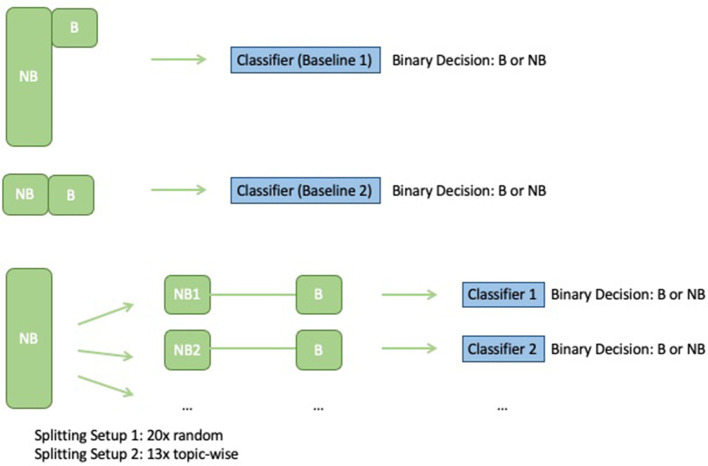
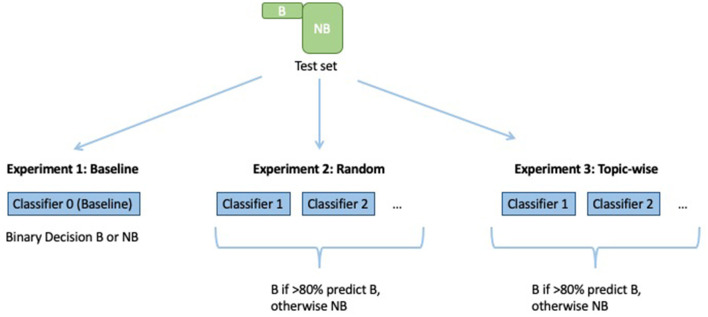
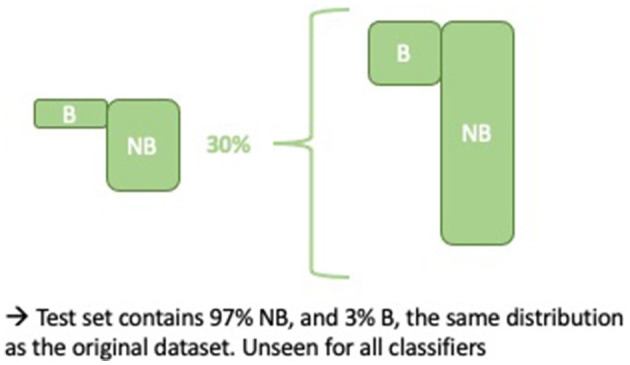
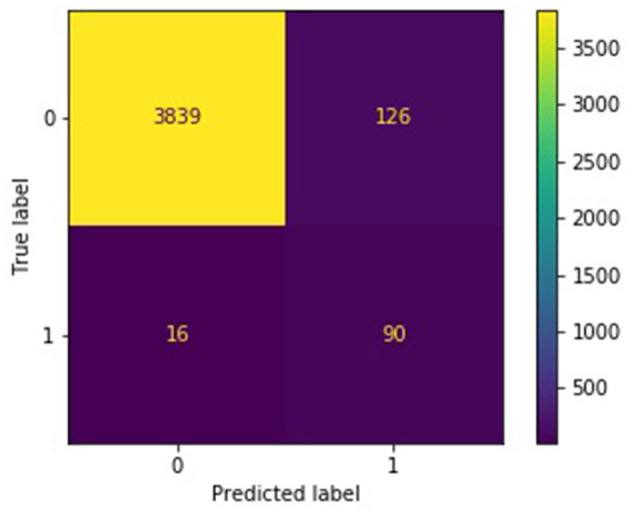
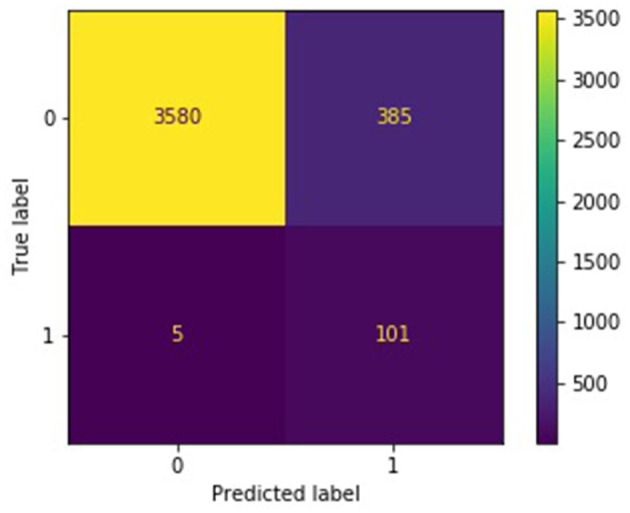
Burnout, a state of emotional, physical, and mental exhaustion caused by excessive and prolonged stress, is a growing concern. It is known to occur when an individual feels overwhelmed, emotionally exhausted, and unable to meet the constant demands imposed upon them. Detecting burnout is not an easy task, in large part because symptoms can overlap with those of other illnesses or syndromes. The use of natural language processing (NLP) methods has the potential to mitigate the limitations of typical burnout detection inventories. In this article, the performance of NLP methods on anonymized free text data samples collected from the online forum/social media platform Reddit was analyzed. A dataset consisting of 13,568 samples describing first-hand experiences, of which 352 are related to burnout and 979 to depression, was compiled. This work demonstrates the effectiveness of NLP and machine learning methods in detecting indicators for burnout. Finally, it improves upon standard baseline classifiers by building and training an ensemble classifier using two methods (subreddit and random batching). The best ensemble models attain a balanced accuracy of 0.93, test F1 score of 0.43, and test recall of 0.93. Both the subreddit and random batching ensembles outperform the single classifier baselines in the experimental setup.
职业倦怠是一种由过度且长期的压力导致的情绪、身体和精神上的疲惫状态,日益受到关注。当一个人感到不堪重负、情绪疲惫且无法满足加诸于他们身上的持续要求时,就会出现职业倦怠。检测职业倦怠并非易事,很大程度上是因为其症状可能与其他疾病或综合征的症状重叠。使用自然语言处理(NLP)方法有潜力减轻典型职业倦怠检测量表的局限性。在本文中,分析了NLP方法在从在线论坛/社交媒体平台Reddit收集的匿名自由文本数据样本上的表现。编制了一个由13568个描述第一手经历的样本组成的数据集,其中352个与职业倦怠相关,979个与抑郁症相关。这项工作证明了NLP和机器学习方法在检测职业倦怠指标方面的有效性。最后,通过使用两种方法(子版块和随机分批)构建和训练一个集成分类器,改进了标准基线分类器。最佳的集成模型实现了0.93的平衡准确率、0.43的测试F1分数和0.93的测试召回率。在实验设置中,子版块和随机分批集成均优于单个分类器基线。