Department of Primary Care and Public Health, Imperial College London, London, UK
Self-Care Academic Research Unit (SCARU), Department of Primary Care and Public Health, Imperial College London Faculty of Medicine, London, UK.
BMJ Open. 2022 Apr 27;12(4):e053566. doi: 10.1136/bmjopen-2021-053566.
Assess the suitability of clinical vignettes in benchmarking the performance of online symptom checkers (OSCs).
Observational study using a publicly available free OSC.
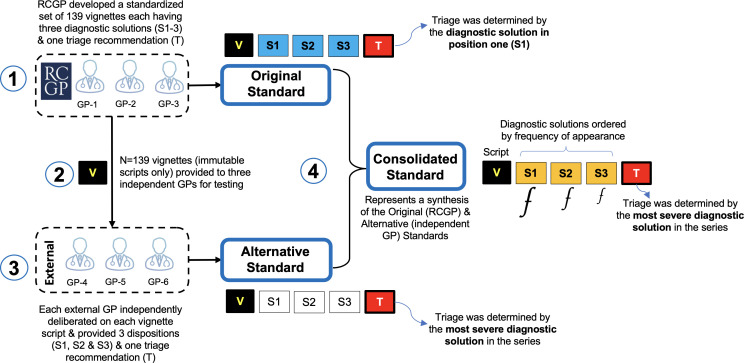
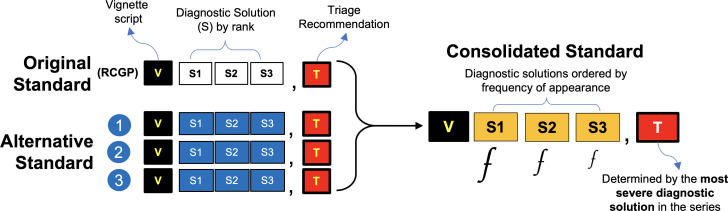
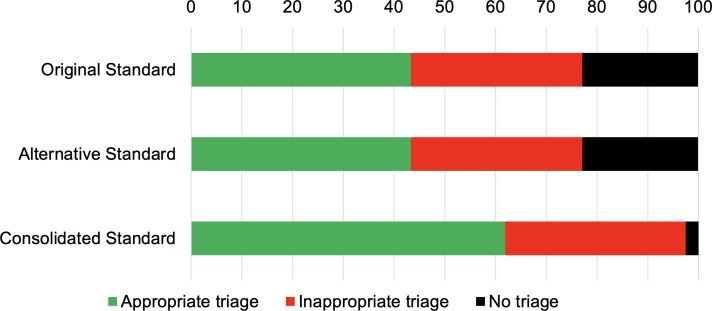
Healthily OSC, which provided consultations in English, was used to record consultation outcomes from two lay and four expert inputters using 139 standardised patient vignettes. Each vignette included three diagnostic solutions and a triage recommendation in one of three categories of triage urgency. A panel of three independent general practitioners interpreted the vignettes to arrive at an alternative set of diagnostic and triage solutions. Both sets of diagnostic and triage solutions were consolidated to arrive at a final consolidated version for benchmarking.
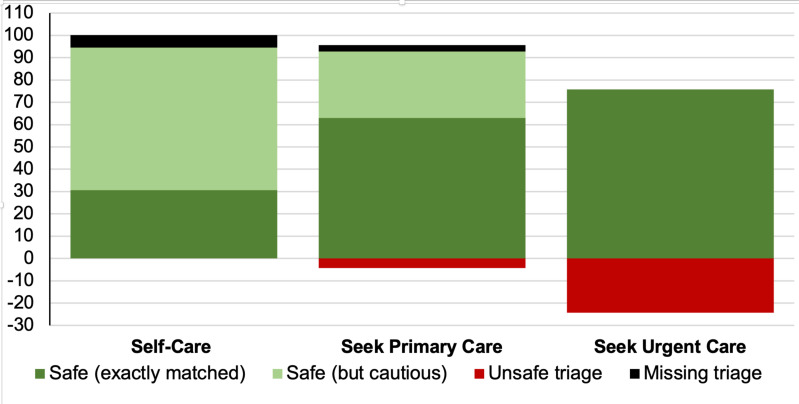
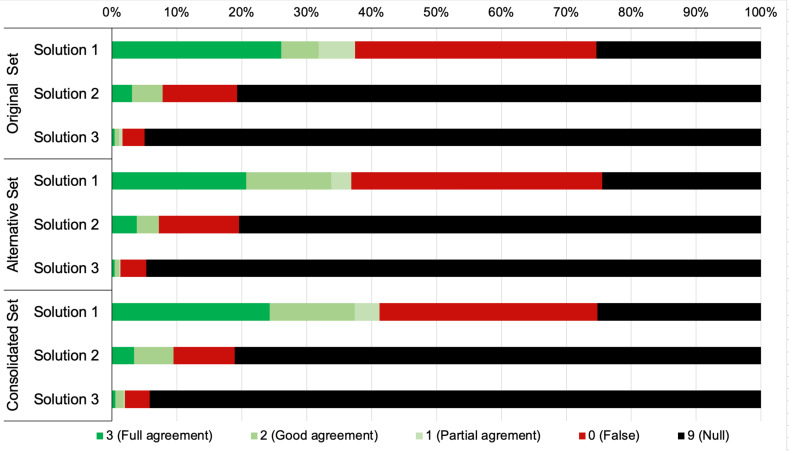
Six inputters simulated 834 standardised patient evaluations using Healthily OSC and recorded outputs (triage solution, signposting, and whether the correct diagnostic solution appeared first or within the first three differentials). We estimated Cohen's kappa to assess how interpretations by different inputters could lead to divergent OSC output even when using the same vignette or when compared with a separate panel of physicians.
There was moderate agreement on triage recommendation (kappa=0.48), and substantial agreement on consultation outcomes between all inputters (kappa=0.73). OSC performance improved significantly from baseline when compared against the final consolidated diagnostic and triage solution (p<0.001).
Clinical vignettes are inherently limited in their utility to benchmark the diagnostic accuracy or triage safety of OSC. Real-world evidence studies involving real patients are recommended to benchmark the performance of OSC against a panel of physicians.
评估临床病例在基准测试在线症状检查器(OSC)性能方面的适用性。
使用公开可用的免费 OSC 进行观察性研究。
健康 OSC 以英文提供咨询服务,使用 139 个标准化患者病例记录了两名外行和四名专家输入者的咨询结果。每个病例包括三个诊断方案和一个分诊建议,分为三个紧急程度类别之一。一个由三名独立的全科医生组成的小组对病例进行解释,以得出另一组诊断和分诊解决方案。将两套诊断和分诊解决方案合并为一套最终的基准测试合并版本。
六名输入者使用 Healthily OSC 模拟了 834 次标准化患者评估,并记录了输出结果(分诊解决方案、引导和正确的诊断解决方案是否首先出现或在前三个不同的方案中出现)。我们估计了 Cohen's kappa,以评估即使使用相同的病例或与单独的医生小组进行比较,不同输入者的解释如何导致 OSC 输出结果的分歧。
在分诊建议方面存在中度一致性(kappa=0.48),所有输入者在咨询结果方面存在高度一致性(kappa=0.73)。与最终的综合诊断和分诊解决方案相比,OSC 的性能有了显著提高(p<0.001)。
临床病例在基准测试 OSC 的诊断准确性或分诊安全性方面的实用性存在固有局限性。建议使用涉及真实患者的真实世界证据研究来基准测试 OSC 相对于医生小组的性能。