School of Computer Science and Technology, Xi'an Jiaotong University, Xi'an, 710049, Shaanxi, China.
National Engineering Lab for Big Data Analytics, Xi'an Jiaotong University, Xi'an, 710049, Shaanxi, China.
BMC Med Inform Decis Mak. 2022 Apr 30;22(1):116. doi: 10.1186/s12911-022-01862-1.
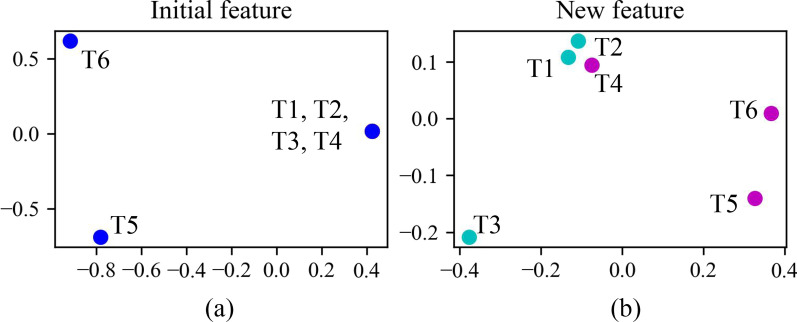
Bio-entity Coreference Resolution (CR) is a vital task in biomedical text mining. An important issue in CR is the differential representation of identical mentions as their similar representations may make the coreference more puzzling. However, when extracting features, existing neural network-based models may bring additional noise to the distinction of identical mentions since they tend to get similar or even identical feature representations.
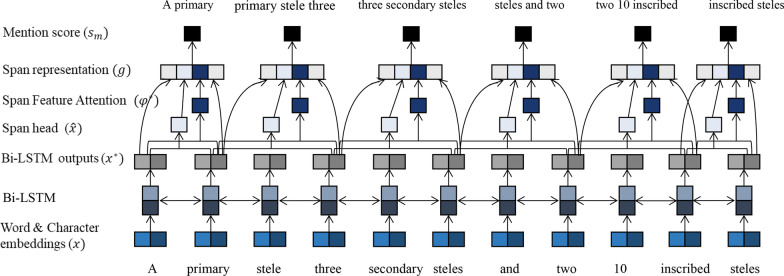
We propose a context-aware feature attention model to distinguish similar or identical text units effectively for better resolving coreference. The new model can represent the identical mentions based on different contexts by adaptively exploiting features, which enables the model reduce the text noise and capture the semantic information effectively.
The experimental results show that the proposed model brings significant improvements on most of the baseline for coreference resolution and mention detection on the BioNLP dataset and CRAFT-CR dataset. The empirical studies further demonstrate its superior performance on the differential representation and coreferential link of identical mentions.
Identical mentions impose difficulties on the current methods of Bio-entity coreference resolution. Thus, we propose the context-aware feature attention model to better distinguish identical mentions and achieve superior performance on both coreference resolution and mention detection, which will further improve the performance of the downstream tasks.
生物实体共指消解(CR)是生物医学文本挖掘中的一项重要任务。在 CR 中,一个重要问题是相同提及的不同表示,因为它们的相似表示可能会使共指更加复杂。然而,在提取特征时,现有的基于神经网络的模型可能会给相同提及的区分带来额外的噪声,因为它们往往会得到相似甚至相同的特征表示。
我们提出了一种上下文感知特征注意力模型,以有效地区分相似或相同的文本单元,从而更好地解决共指问题。该新模型可以基于不同的上下文自适应地表示相同的提及,从而使模型能够减少文本噪声并有效地捕获语义信息。
实验结果表明,该模型在 BioNLP 数据集和 CRAFT-CR 数据集上的大多数基线的共指消解和提及检测方面都有显著的改进。实证研究进一步证明了其在相同提及的差异化表示和共指链接方面的优越性能。
相同提及给当前的生物实体共指消解方法带来了困难。因此,我们提出了上下文感知特征注意力模型,以更好地区分相同提及,并在共指消解和提及检测方面取得优异的性能,从而进一步提高下游任务的性能。