Lavergne Thomas, Grouin Cyril, Zweigenbaum Pierre
BMC Bioinformatics. 2015;16 Suppl 10(Suppl 10):S6. doi: 10.1186/1471-2105-16-S10-S6. Epub 2015 Jul 13.
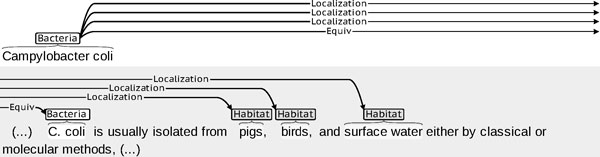
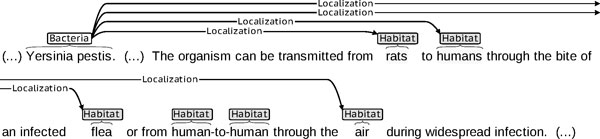
The acquisition of knowledge about relations between bacteria and their locations (habitats and geographical locations) in short texts about bacteria, as defined in the BioNLP-ST 2013 Bacteria Biotope task, depends on the detection of co-reference links between mentions of entities of each of these three types. To our knowledge, no participant in this task has investigated this aspect of the situation. The present work specifically addresses issues raised by this situation: (i) how to detect these co-reference links and associated co-reference chains; (ii) how to use them to prepare positive and negative examples to train a supervised system for the detection of relations between entity mentions; (iii) what context around which entity mentions contributes to relation detection when co-reference chains are provided.
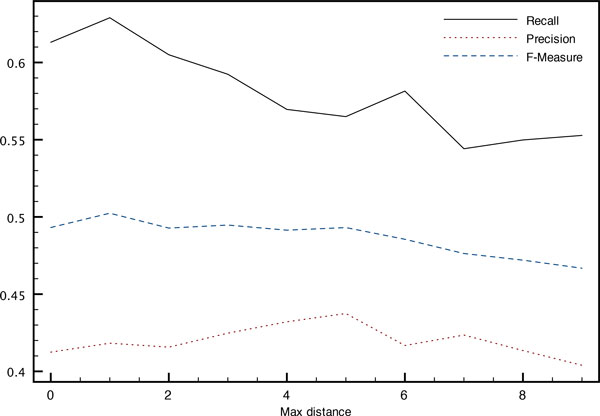
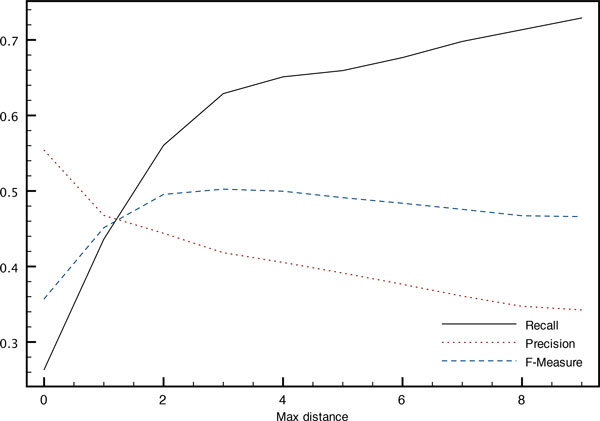
We present experiments and results obtained both with gold entity mentions (task 2 of BioNLP-ST 2013) and with automatically detected entity mentions (end-to-end system, in task 3 of BioNLP-ST 2013). Our supervised mention detection system uses a linear chain Conditional Random Fields classifier, and our relation detection system relies on a Logistic Regression (aka Maximum Entropy) classifier. They use a set of morphological, morphosyntactic and semantic features. To minimize false inferences, co-reference resolution applies a set of heuristic rules designed to optimize precision. They take into account the types of the detected entity mentions, and take advantage of the didactic nature of the texts of the corpus, where a large proportion of bacteria naming is fairly explicit (although natural referring expressions such as "the bacteria" are common). The resulting system achieved a 0.495 F-measure on the official test set when taking as input the gold entity mentions, and a 0.351 F-measure when taking as input entity mentions predicted by our CRF system, both of which are above the best BioNLP-ST 2013 participant system.
We show that co-reference resolution substantially improves over a baseline system which does not use co-reference information: about 3.5 F-measure points on the test corpus for the end-to-end system (5.5 points on the development corpus) and 7 F-measure points on both development and test corpora when gold mentions are used. While this outperforms the best published system on the BioNLP-ST 2013 Bacteria Biotope dataset, we consider that it provides mostly a stronger baseline from which more work can be started. We also emphasize the importance and difficulty of designing a comprehensive gold standard co-reference annotation, which we explain is a key point to further progress on the task.
在BioNLP - ST 2013细菌生态位任务中所定义的关于细菌的短文本里,获取细菌与其位置(栖息地和地理位置)之间关系的知识,依赖于检测这三种类型的实体提及之间的共指链接。据我们所知,该任务的参与者均未研究过这种情况。本研究专门探讨了这种情况引发的问题:(i)如何检测这些共指链接及相关的共指链;(ii)如何利用它们来准备正例和反例,以训练一个用于检测实体提及之间关系的监督系统;(iii)当提供共指链时,哪些实体提及周围的上下文有助于关系检测。
我们展示了使用金标准实体提及(BioNLP - ST 2013的任务2)和自动检测的实体提及(BioNLP - ST 2013的任务3中的端到端系统)所获得的实验和结果。我们的监督提及检测系统使用线性链条件随机场分类器,关系检测系统依赖于逻辑回归(又名最大熵)分类器。它们使用一组形态、形态句法和语义特征。为了尽量减少错误推断,共指消解应用了一组旨在优化精度的启发式规则。这些规则考虑了检测到的实体提及的类型,并利用了语料库文本的教学性质,其中很大一部分细菌命名相当明确(尽管像“这种细菌”这样的自然指代表达很常见)。当将金标准实体提及作为输入时,所得到的系统在官方测试集上的F值为0.495,当将我们的条件随机场系统预测的实体提及作为输入时,F值为0.351,这两个结果均高于BioNLP - ST 2013中最佳参与者系统的结果。
我们表明,与不使用共指信息的基线系统相比,共指消解有显著改进:对于端到端系统,在测试语料库上提高了约3.5个F值点(在开发语料库上提高了5.5个点),当使用金标准提及时,在开发语料库和测试语料库上均提高了7个F值点。虽然这在BioNLP - ST 2013细菌生态位数据集上优于已发表的最佳系统,但我们认为它主要提供了一个更强的基线,可在此基础上开展更多工作。我们还强调了设计全面的金标准共指标注的重要性和难度,我们解释这是该任务进一步取得进展的关键。