Kilicoglu Halil, Demner-Fushman Dina
Lister Hill National Center for Biomedical Communications, National Library of Medicine, National Institutes of Health, Bethesda, MD, United States of America.
PLoS One. 2016 Mar 2;11(3):e0148538. doi: 10.1371/journal.pone.0148538. eCollection 2016.
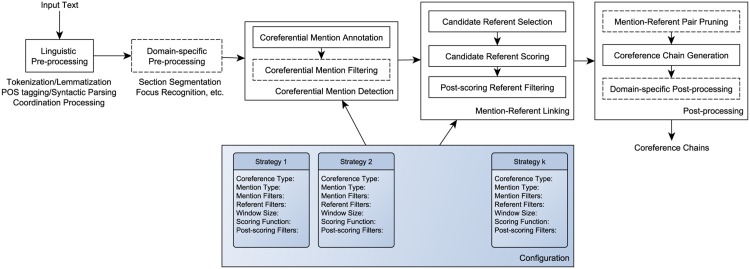
Coreference resolution is one of the fundamental and challenging tasks in natural language processing. Resolving coreference successfully can have a significant positive effect on downstream natural language processing tasks, such as information extraction and question answering. The importance of coreference resolution for biomedical text analysis applications has increasingly been acknowledged. One of the difficulties in coreference resolution stems from the fact that distinct types of coreference (e.g., anaphora, appositive) are expressed with a variety of lexical and syntactic means (e.g., personal pronouns, definite noun phrases), and that resolution of each combination often requires a different approach. In the biomedical domain, it is common for coreference annotation and resolution efforts to focus on specific subcategories of coreference deemed important for the downstream task. In the current work, we aim to address some of these concerns regarding coreference resolution in biomedical text. We propose a general, modular framework underpinned by a smorgasbord architecture (Bio-SCoRes), which incorporates a variety of coreference types, their mentions and allows fine-grained specification of resolution strategies to resolve coreference of distinct coreference type-mention pairs. For development and evaluation, we used a corpus of structured drug labels annotated with fine-grained coreference information. In addition, we evaluated our approach on two other corpora (i2b2/VA discharge summaries and protein coreference dataset) to investigate its generality and ease of adaptation to other biomedical text types. Our results demonstrate the usefulness of our novel smorgasbord architecture. The specific pipelines based on the architecture perform successfully in linking coreferential mention pairs, while we find that recognition of full mention clusters is more challenging. The corpus of structured drug labels (SPL) as well as the components of Bio-SCoRes and some of the pipelines based on it are publicly available at https://github.com/kilicogluh/Bio-SCoRes. We believe that Bio-SCoRes can serve as a strong and extensible baseline system for coreference resolution of biomedical text.
指代消解是自然语言处理中一项基本且具有挑战性的任务。成功解决指代问题对下游自然语言处理任务(如信息提取和问答)会产生显著的积极影响。指代消解在生物医学文本分析应用中的重要性已日益得到认可。指代消解的困难之一在于,不同类型的指代(如回指、同位语)通过多种词汇和句法手段(如人称代词、限定名词短语)来表达,而且每种组合的消解通常需要不同的方法。在生物医学领域,指代标注和消解工作通常聚焦于对下游任务而言重要的特定指代子类别。在当前工作中,我们旨在解决生物医学文本中与指代消解相关的一些问题。我们提出了一个通用的模块化框架,该框架以杂烩式架构(Bio - SCoRes)为基础,它纳入了多种指代类型及其提及内容,并允许对消解策略进行细粒度的指定,以解决不同指代类型 - 提及对的指代问题。为了进行开发和评估,我们使用了一个标注有细粒度指代信息的结构化药品标签语料库。此外,我们在另外两个语料库(i2b2/VA出院小结和蛋白质指代数据集)上评估了我们的方法,以研究其通用性以及对其他生物医学文本类型的适应难易程度。我们的结果证明了我们新颖的杂烩式架构的有用性。基于该架构的特定管道在链接指代提及对方面表现成功,而我们发现识别完整的提及簇更具挑战性。结构化药品标签(SPL)语料库以及Bio - SCoRes的组件和一些基于它的管道可在https://github.com/kilicogluh/Bio - SCoRes上公开获取。我们相信Bio - SCoRes可以作为生物医学文本指代消解的一个强大且可扩展的基线系统。