Health Technology Program, Pontifical Catholic University of Paraná, Rua Imaculada Conceição, 1155 - Curitiba, Paraná, 80215-901, Brazil.
AI Lab, Philips Research North America, Cambridge, MA, USA.
J Biomed Semantics. 2022 May 8;13(1):13. doi: 10.1186/s13326-022-00269-1.
The high volume of research focusing on extracting patient information from electronic health records (EHRs) has led to an increase in the demand for annotated corpora, which are a precious resource for both the development and evaluation of natural language processing (NLP) algorithms. The absence of a multipurpose clinical corpus outside the scope of the English language, especially in Brazilian Portuguese, is glaring and severely impacts scientific progress in the biomedical NLP field.
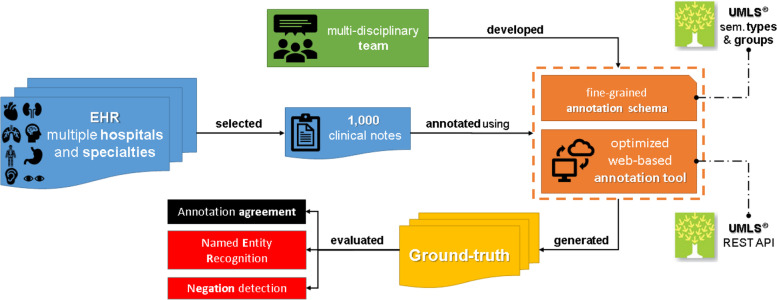
In this study, a semantically annotated corpus was developed using clinical text from multiple medical specialties, document types, and institutions. In addition, we present, (1) a survey listing common aspects, differences, and lessons learned from previous research, (2) a fine-grained annotation schema that can be replicated to guide other annotation initiatives, (3) a web-based annotation tool focusing on an annotation suggestion feature, and (4) both intrinsic and extrinsic evaluation of the annotations.
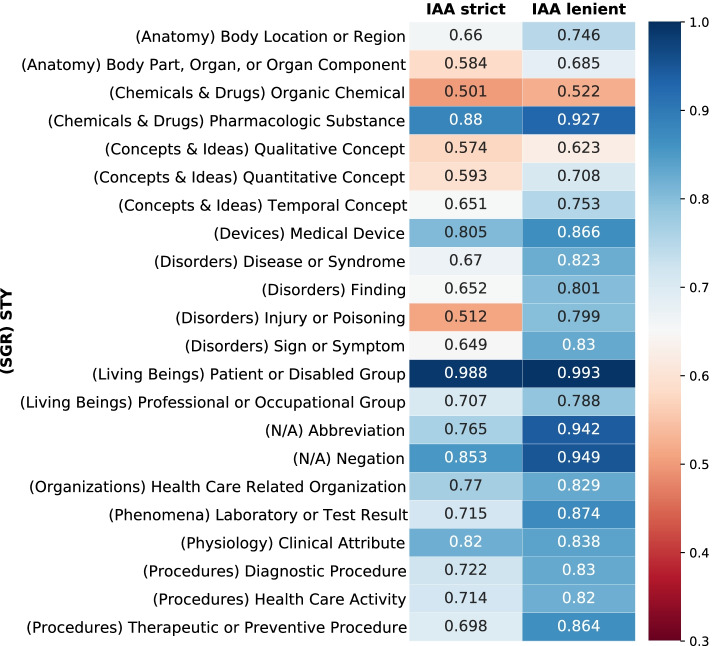
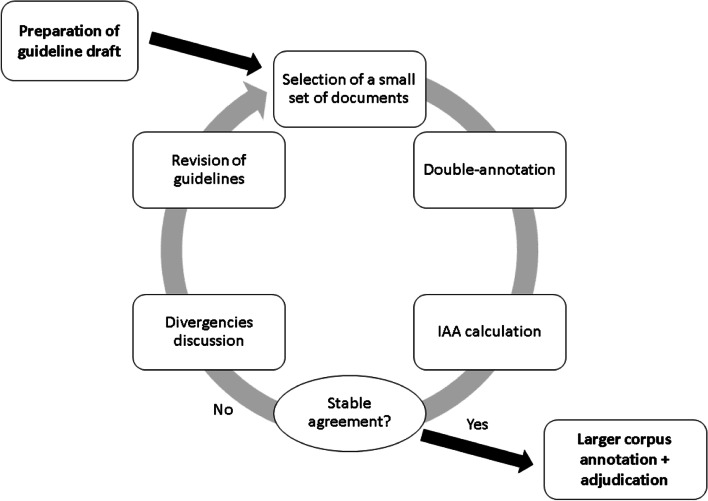
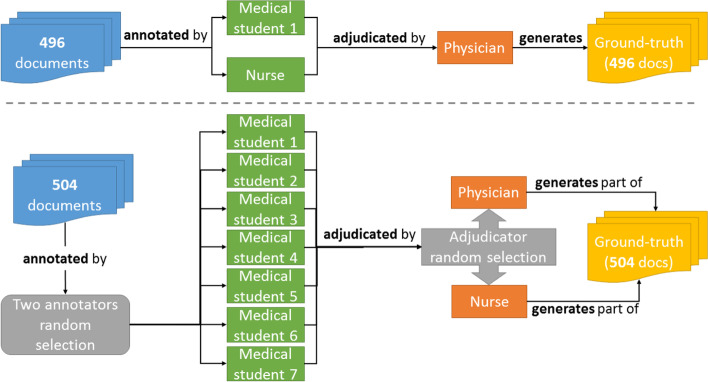
This study resulted in SemClinBr, a corpus that has 1000 clinical notes, labeled with 65,117 entities and 11,263 relations. In addition, both negation cues and medical abbreviation dictionaries were generated from the annotations. The average annotator agreement score varied from 0.71 (applying strict match) to 0.92 (considering a relaxed match) while accepting partial overlaps and hierarchically related semantic types. The extrinsic evaluation, when applying the corpus to two downstream NLP tasks, demonstrated the reliability and usefulness of annotations, with the systems achieving results that were consistent with the agreement scores.
The SemClinBr corpus and other resources produced in this work can support clinical NLP studies, providing a common development and evaluation resource for the research community, boosting the utilization of EHRs in both clinical practice and biomedical research. To the best of our knowledge, SemClinBr is the first available Portuguese clinical corpus.
大量研究致力于从电子健康记录 (EHR) 中提取患者信息,这导致对标注语料库的需求增加,标注语料库是自然语言处理 (NLP) 算法的开发和评估的宝贵资源。除了英语范围之外,特别是在巴西葡萄牙语中,缺乏多用途的临床语料库,这是显而易见的,严重影响了生物医学 NLP 领域的科学进展。
本研究使用来自多个医学专业、文档类型和机构的临床文本开发了一个语义标注语料库。此外,我们还展示了:(1) 一份列出先前研究的常见方面、差异和经验教训的调查;(2) 可复制的细粒度标注方案,以指导其他标注计划;(3) 一个专注于标注建议功能的基于网络的标注工具;以及 (4) 标注的内在和外在评估。
本研究产生了 SemClinBr,这是一个包含 1000 个临床笔记、标注了 65117 个实体和 11263 个关系的语料库。此外,还从标注中生成了否定提示和医学缩写词典。平均注释者一致性评分从 0.71(应用严格匹配)到 0.92(考虑宽松匹配)不等,同时接受部分重叠和层次相关的语义类型。在将语料库应用于两个下游 NLP 任务的外部评估中,证明了标注的可靠性和有用性,系统的结果与一致性评分一致。
SemClinBr 语料库和本工作中生成的其他资源可以支持临床 NLP 研究,为研究社区提供一个共同的开发和评估资源,促进 EHR 在临床实践和生物医学研究中的利用。据我们所知,SemClinBr 是第一个可用的葡萄牙语临床语料库。