Department of Pharmacology, University of Colorado Anschutz Medical Campus, Aurora, CO, USA.
BMC Bioinformatics. 2012 Jul 9;13:161. doi: 10.1186/1471-2105-13-161.
Manually annotated corpora are critical for the training and evaluation of automated methods to identify concepts in biomedical text.
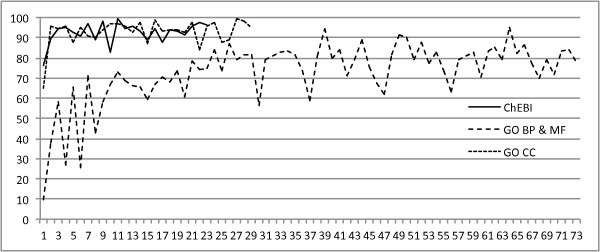
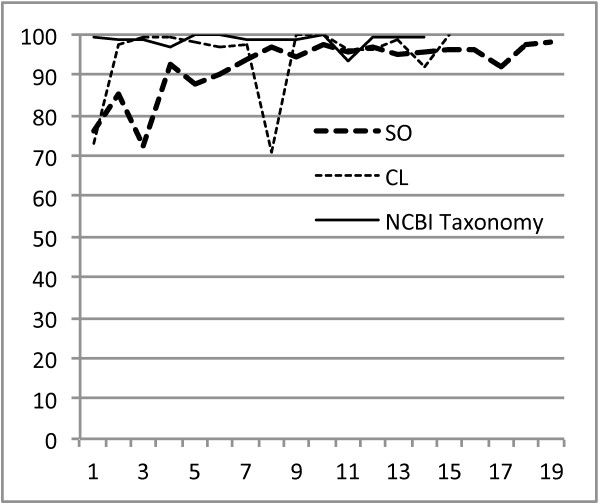
This paper presents the concept annotations of the Colorado Richly Annotated Full-Text (CRAFT) Corpus, a collection of 97 full-length, open-access biomedical journal articles that have been annotated both semantically and syntactically to serve as a research resource for the biomedical natural-language-processing (NLP) community. CRAFT identifies all mentions of nearly all concepts from nine prominent biomedical ontologies and terminologies: the Cell Type Ontology, the Chemical Entities of Biological Interest ontology, the NCBI Taxonomy, the Protein Ontology, the Sequence Ontology, the entries of the Entrez Gene database, and the three subontologies of the Gene Ontology. The first public release includes the annotations for 67 of the 97 articles, reserving two sets of 15 articles for future text-mining competitions (after which these too will be released). Concept annotations were created based on a single set of guidelines, which has enabled us to achieve consistently high interannotator agreement.
As the initial 67-article release contains more than 560,000 tokens (and the full set more than 790,000 tokens), our corpus is among the largest gold-standard annotated biomedical corpora. Unlike most others, the journal articles that comprise the corpus are drawn from diverse biomedical disciplines and are marked up in their entirety. Additionally, with a concept-annotation count of nearly 100,000 in the 67-article subset (and more than 140,000 in the full collection), the scale of conceptual markup is also among the largest of comparable corpora. The concept annotations of the CRAFT Corpus have the potential to significantly advance biomedical text mining by providing a high-quality gold standard for NLP systems. The corpus, annotation guidelines, and other associated resources are freely available at http://bionlp-corpora.sourceforge.net/CRAFT/index.shtml.
人工标注语料库对于训练和评估自动方法识别生物医学文本中的概念至关重要。
本文介绍了科罗拉多州丰富标注全文(CRAFT)语料库的概念标注,这是一个包含 97 篇全文、开放获取的生物医学期刊文章的集合,这些文章已经进行了语义和句法标注,作为生物医学自然语言处理(NLP)社区的研究资源。CRAFT 从九个著名的生物医学本体和术语学中识别出几乎所有概念的提及:细胞类型本体、生物化学实体本体、NCBI 分类法、蛋白质本体、序列本体、Entrez Gene 数据库条目,以及基因本体的三个子本体。第一个公开版本包括 97 篇文章中的 67 篇的注释,保留了两套 15 篇文章用于未来的文本挖掘竞赛(之后也将发布这些文章)。概念注释是基于一套单一的指南创建的,这使得我们能够实现始终如一的高注释者间一致性。
由于初始的 67 篇文章发布版本包含超过 560,000 个标记(并且完整版本包含超过 790,000 个标记),我们的语料库是最大的黄金标准生物医学语料库之一。与大多数其他语料库不同,构成语料库的期刊文章来自不同的生物医学学科,并进行了完整的标注。此外,在 67 篇文章的子集(以及完整集合中的超过 140,000 个)中,概念标记的规模也是可比语料库中最大的之一。CRAFT 语料库的概念注释有可能通过为 NLP 系统提供高质量的黄金标准来显著推进生物医学文本挖掘。语料库、注释指南和其他相关资源可在 http://bionlp-corpora.sourceforge.net/CRAFT/index.shtml 上免费获得。