Ireland Sam M, Martin Andrew C R
Division of Biosciences, Institute of Structural and Molecular Biology, University College London, London WC1E 6BT, UK.
Bioinform Adv. 2021 Sep 29;1(1):vbab023. doi: 10.1093/bioadv/vbab023. eCollection 2021.
Many bioinformatics resources are provided as 'web services', with large databases and analysis software stored on a central server, and clients interacting with them using the hypertext transport protocol (HTTP). While some provide only a visual HTML interface, requiring a web browser to use them, many provide programmatic access using a web application programming interface (API) which returns XML, JSON or plain text that computer programs can interpret more easily. This allows access to be automated. Initially, many bioinformatics APIs used the 'simple object access protocol' (SOAP) and, more recently, representational state transfer (REST).
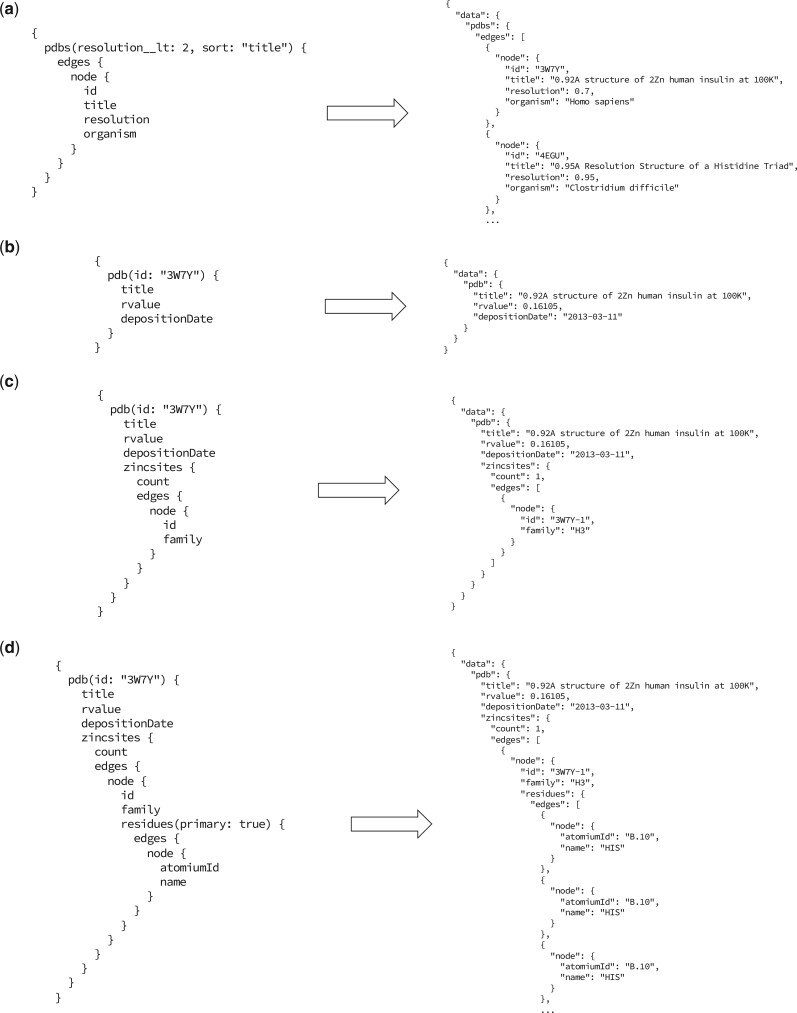
GraphQL is a novel, increasingly prevalent alternative to REST and SOAP that represents the available data in the form of a graph to which any conceivable query can be submitted, and which is seeing increasing adoption in industry. Here, we review the principles of GraphQL, outline its particular suitability to the delivery of bioinformatics resources and describe its implementation in our ZincBind resource.
Supplementary data are available at online.
许多生物信息学资源以“网络服务”的形式提供,大型数据库和分析软件存储在中央服务器上,客户端使用超文本传输协议(HTTP)与它们进行交互。虽然有些只提供可视化的HTML界面,需要使用网页浏览器来使用它们,但许多提供了使用网络应用程序编程接口(API)的编程访问,该接口返回计算机程序可以更轻松解释的XML、JSON或纯文本。这使得访问能够自动化。最初,许多生物信息学API使用“简单对象访问协议”(SOAP),最近则采用了代表性状态转移(REST)。
GraphQL是一种新颖且越来越流行的替代REST和SOAP的方法,它以图的形式表示可用数据,可以提交任何可想象的查询,并且在行业中越来越受到采用。在这里,我们回顾了GraphQL的原理,概述了它对生物信息学资源交付的特别适用性,并描述了它在我们的ZincBind资源中的实现。
补充数据可在网上获取。