Department of Materials Science and Engineering, University of California, Berkeley, CA, 94720, USA.
Materials Sciences Division, Lawrence Berkeley National Laboratory, Berkeley, CA, 94720, USA.
Sci Data. 2022 May 26;9(1):234. doi: 10.1038/s41597-022-01321-6.
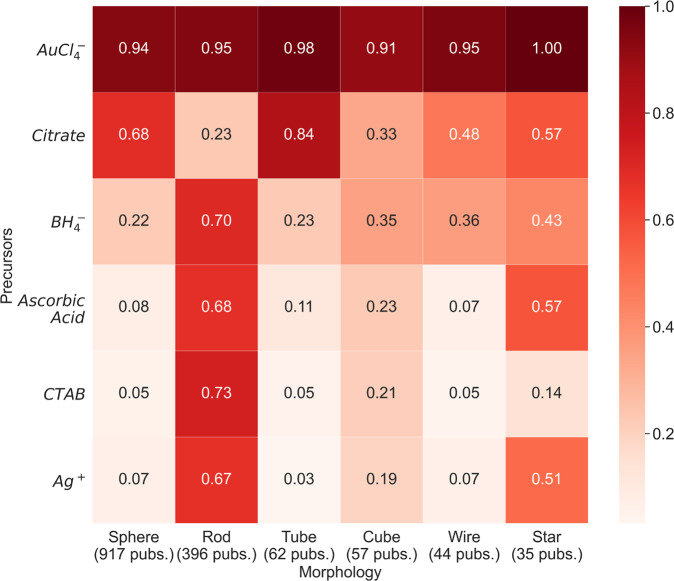
Gold nanoparticles are highly desired for a range of technological applications due to their tunable properties, which are dictated by the size and shape of the constituent particles. Many heuristic methods for controlling the morphological characteristics of gold nanoparticles are well known. However, the underlying mechanisms controlling their size and shape remain poorly understood, partly due to the immense range of possible combinations of synthesis parameters. Data-driven methods can offer insight to help guide understanding of these underlying mechanisms, so long as sufficient synthesis data are available. To facilitate data mining in this direction, we have constructed and made publicly available a dataset of codified gold nanoparticle synthesis protocols and outcomes extracted directly from the nanoparticle materials science literature using natural language processing and text-mining techniques. This dataset contains 5,154 data records, each representing a single gold nanoparticle synthesis article, filtered from a database of 4,973,165 publications. Each record contains codified synthesis protocols and extracted morphological information from a total of 7,608 experimental and 12,519 characterization paragraphs.
金纳米颗粒由于其可调的性质而在各种技术应用中受到高度的期望,这些性质是由组成颗粒的大小和形状决定的。许多用于控制金纳米颗粒形态特征的启发式方法是众所周知的。然而,控制其大小和形状的基本机制仍然理解得很差,部分原因是合成参数的可能组合范围非常大。数据驱动的方法可以提供有助于指导对这些基本机制的理解的见解,只要有足够的合成数据可用。为了在这个方向上促进数据挖掘,我们使用自然语言处理和文本挖掘技术,从纳米颗粒材料科学文献中直接提取了一个编码的金纳米颗粒合成方案和结果的数据集,并将其构建并公开。该数据集包含 5154 个数据记录,每个记录代表一个单一的金纳米颗粒合成文章,从 4973165 篇出版物的数据库中筛选出来。每个记录包含从总共 7608 个实验和 12519 个表征段落中编码的合成方案和提取的形态信息。