Greenwood David, Taverner Thomas, Adderley Nicola J, Price Malcolm James, Gokhale Krishna, Sainsbury Christopher, Gallier Suzy, Welch Carly, Sapey Elizabeth, Murray Duncan, Fanning Hilary, Ball Simon, Nirantharakumar Krishnarajah, Croft Wayne, Moss Paul
Institute of Immunology and Immunotherapy, University of Birmingham, Birmingham, UK.
The Centre for Computational Biology, University of Birmingham, Birmingham, UK.
iScience. 2022 Jul 15;25(7):104480. doi: 10.1016/j.isci.2022.104480. Epub 2022 May 31.
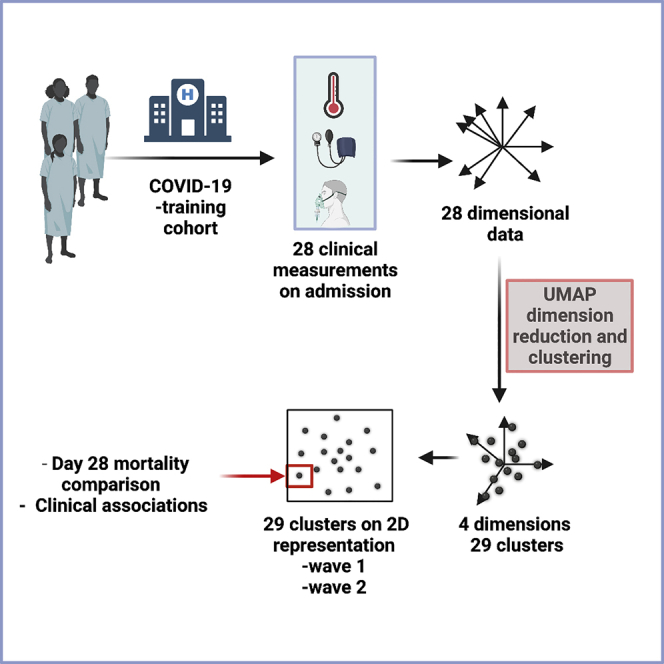
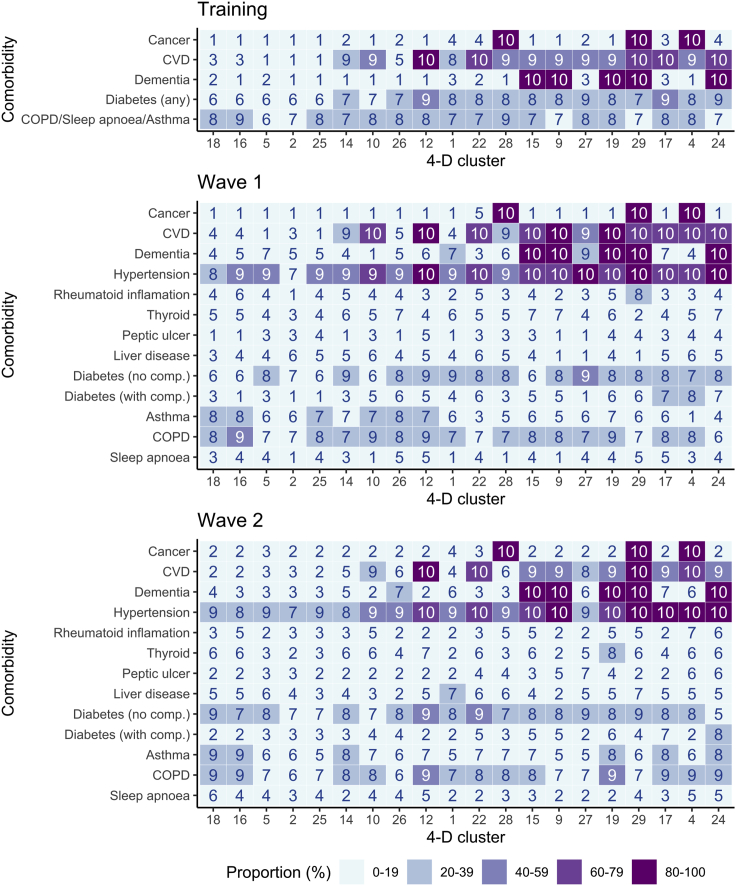
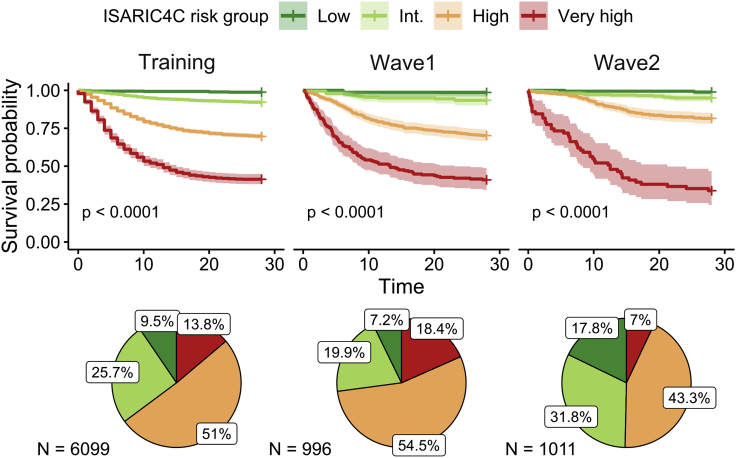
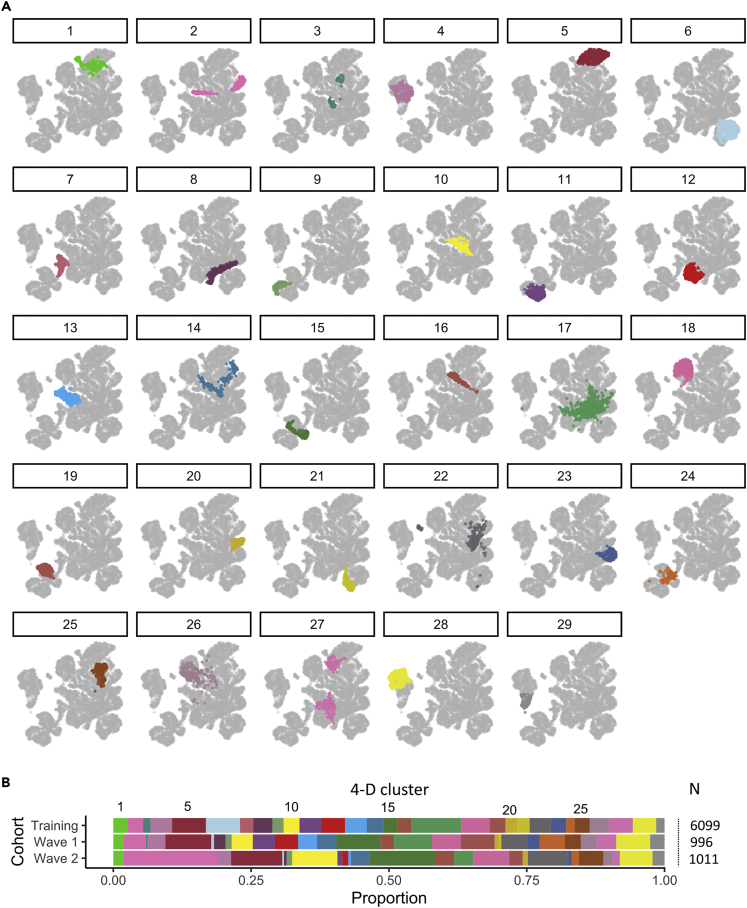
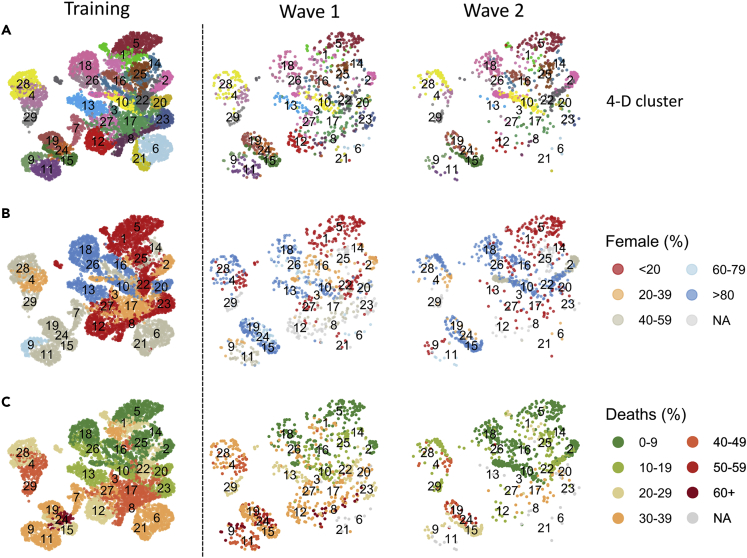
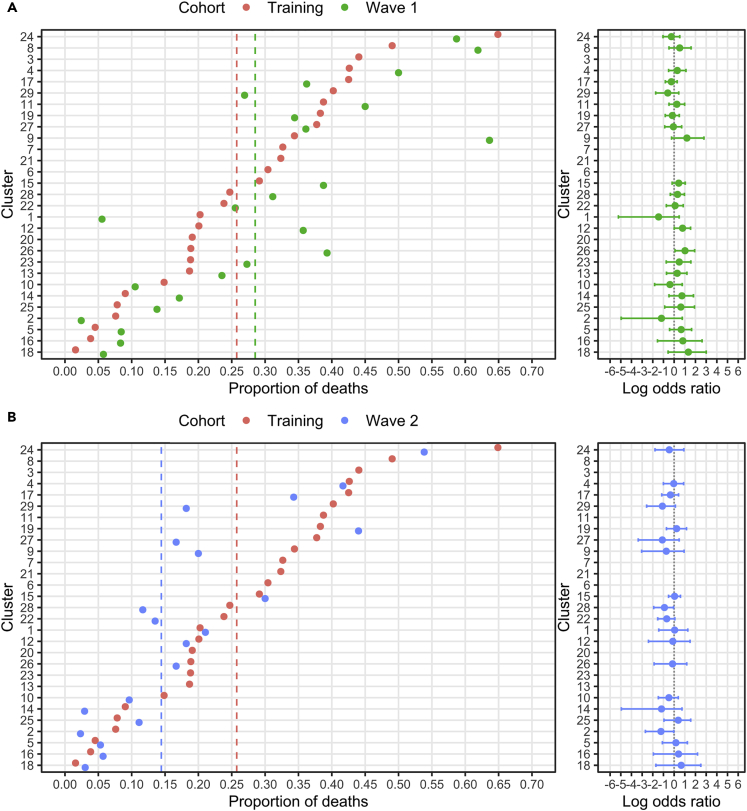
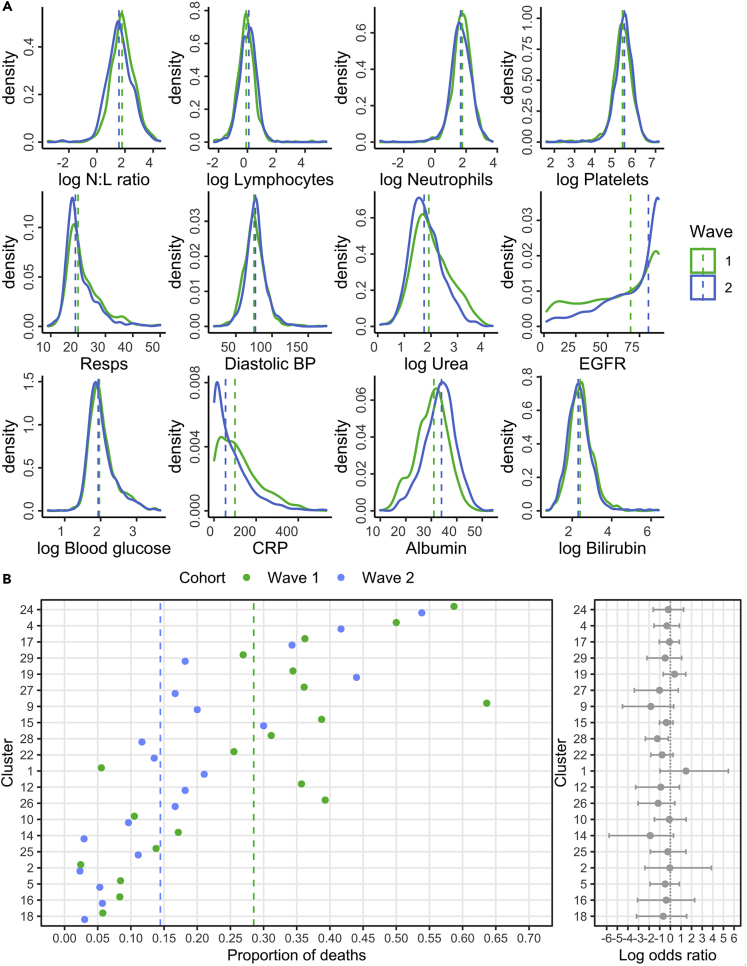
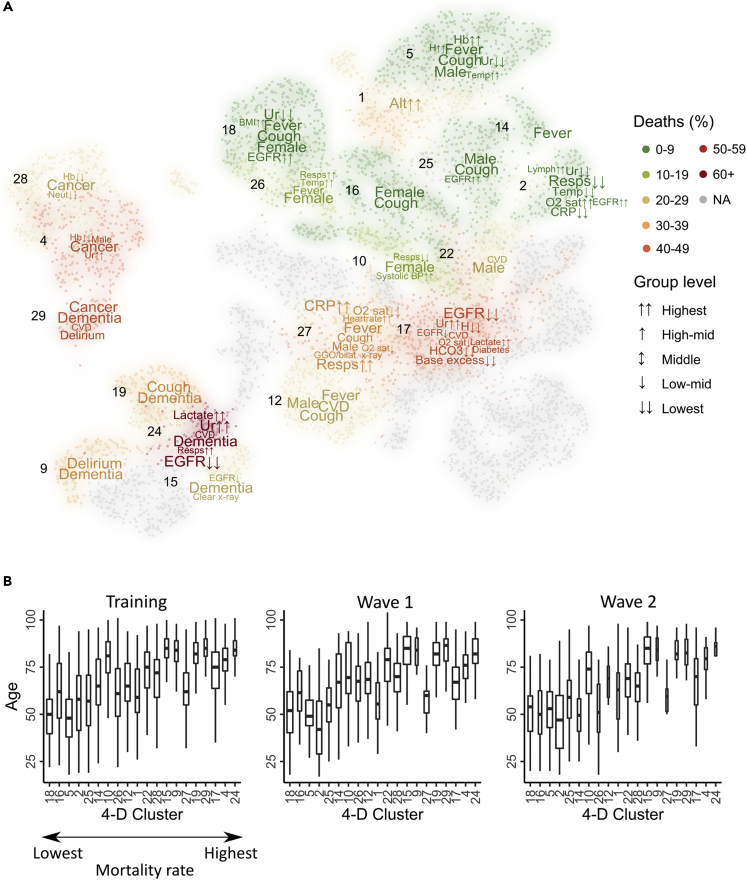
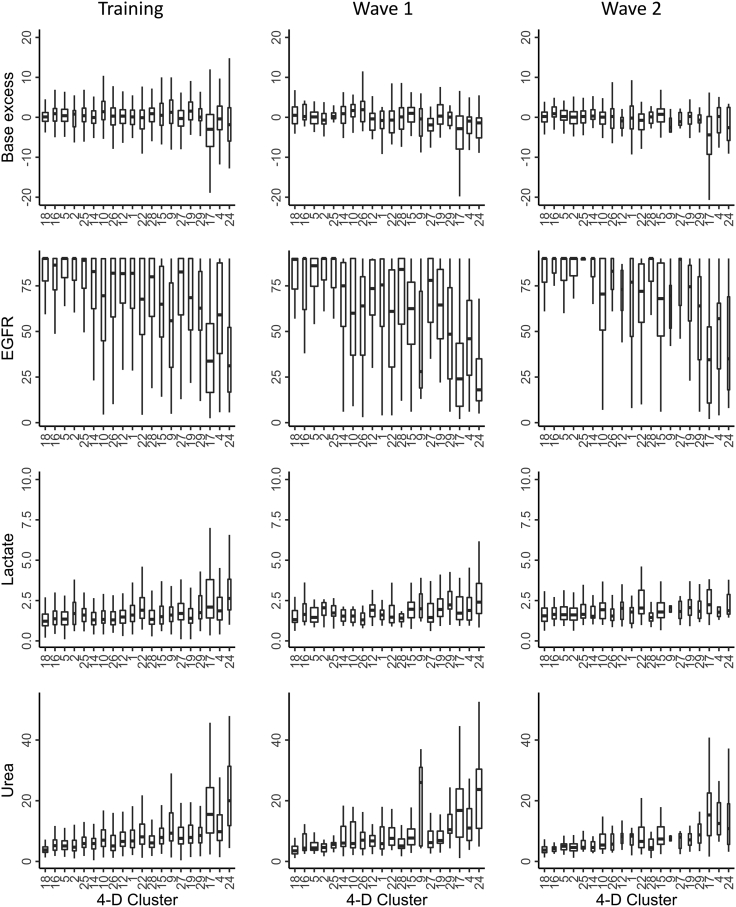
Clinical outcomes for patients with COVID-19 are heterogeneous and there is interest in defining subgroups for prognostic modeling and development of treatment algorithms. We obtained 28 demographic and laboratory variables in patients admitted to hospital with COVID-19. These comprised a training cohort (n = 6099) and two validation cohorts during the first and second waves of the pandemic (n = 996; n = 1011). Uniform manifold approximation and projection (UMAP) dimension reduction and Gaussian mixture model (GMM) analysis was used to define patient clusters. 29 clusters were defined in the training cohort and associated with markedly different mortality rates, which were predictive within confirmation datasets. Deconvolution of clinical features within clusters identified unexpected relationships between variables. Integration of large datasets using UMAP-assisted clustering can therefore identify patient subgroups with prognostic information and uncovers unexpected interactions between clinical variables. This application of machine learning represents a powerful approach for delineating disease pathogenesis and potential therapeutic interventions.
新型冠状病毒肺炎(COVID-19)患者的临床结局具有异质性,因此人们希望确定亚组,用于预后建模和治疗算法的开发。我们获取了因COVID-19住院患者的28个人口统计学和实验室变量。这些数据包括一个训练队列(n = 6099)以及疫情第一波和第二波期间的两个验证队列(n = 996;n = 1011)。使用均匀流形近似和投影(UMAP)降维和高斯混合模型(GMM)分析来定义患者聚类。在训练队列中定义了29个聚类,这些聚类与明显不同的死亡率相关,在验证数据集中具有预测性。聚类内临床特征的反卷积确定了变量之间意想不到的关系。因此,使用UMAP辅助聚类对大型数据集进行整合,可以识别出具有预后信息的患者亚组,并揭示临床变量之间意想不到的相互作用。这种机器学习的应用代表了一种强大的方法,可用于描绘疾病发病机制和潜在的治疗干预措施。