Department of Biohealth Informatics, Indiana University School of Informatics and Computing, Indianapolis, IN, USA.
Medical Informatics Unit, Department of Medical Education, College of Medicine, King Saud University, Riyadh, Saudi Arabia.
J Biomed Semantics. 2022 Jun 11;13(1):17. doi: 10.1186/s13326-022-00272-6.
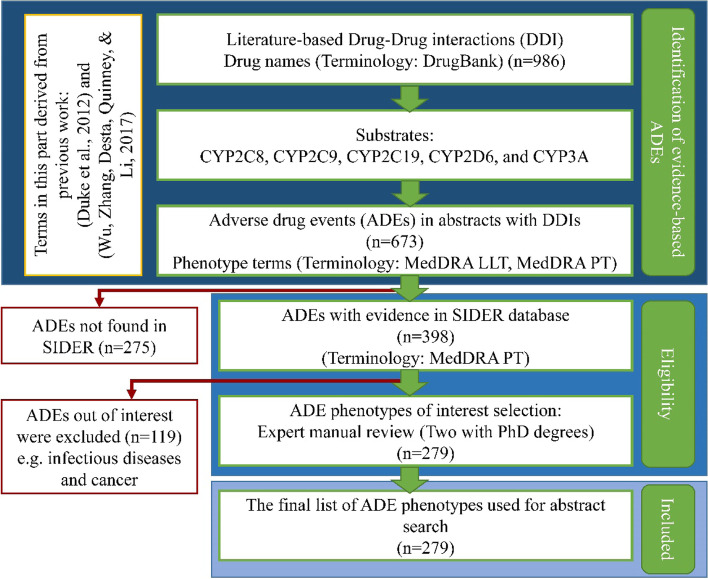
Adverse events induced by drug-drug interactions are a major concern in the United States. Current research is moving toward using electronic health record (EHR) data, including for adverse drug events discovery. One of the first steps in EHR-based studies is to define a phenotype for establishing a cohort of patients. However, phenotype definitions are not readily available for all phenotypes. One of the first steps of developing automated text mining tools is building a corpus. Therefore, this study aimed to develop annotation guidelines and a gold standard corpus to facilitate building future automated approaches for mining phenotype definitions contained in the literature. Furthermore, our aim is to improve the understanding of how these published phenotype definitions are presented in the literature and how we annotate them for future text mining tasks.
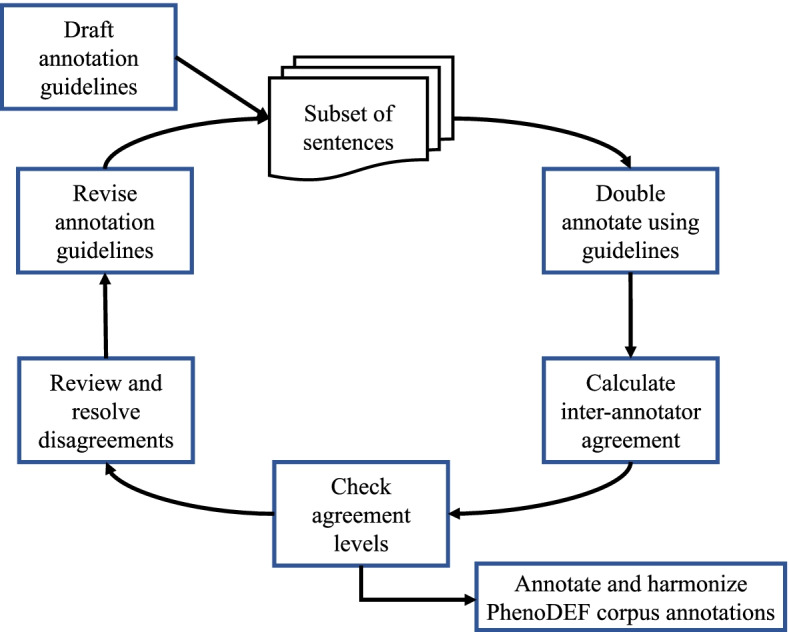
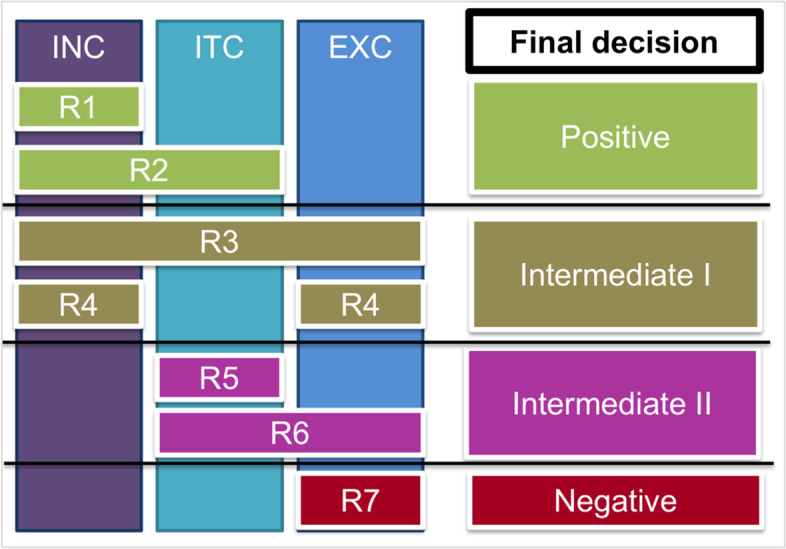
Two annotators manually annotated the corpus on a sentence-level for the presence of evidence for phenotype definitions. Three major categories (inclusion, intermediate, and exclusion) with a total of ten dimensions were proposed characterizing major contextual patterns and cues for presenting phenotype definitions in published literature. The developed annotation guidelines were used to annotate the corpus that contained 3971 sentences: 1923 out of 3971 (48.4%) for the inclusion category, 1851 out of 3971 (46.6%) for the intermediate category, and 2273 out of 3971 (57.2%) for exclusion category. The highest number of annotated sentences was 1449 out of 3971 (36.5%) for the "Biomedical & Procedure" dimension. The lowest number of annotated sentences was 49 out of 3971 (1.2%) for "The use of NLP". The overall percent inter-annotator agreement was 97.8%. Percent and Kappa statistics also showed high inter-annotator agreement across all dimensions.
The corpus and annotation guidelines can serve as a foundational informatics approach for annotating and mining phenotype definitions in literature, and can be used later for text mining applications.
药物相互作用引起的不良事件是美国的一个主要关注点。目前的研究正在转向使用电子健康记录(EHR)数据,包括用于发现不良药物事件。基于 EHR 的研究的第一步之一是为建立患者队列定义表型。然而,并非所有表型都有现成的表型定义。开发自动化文本挖掘工具的第一步之一是构建语料库。因此,本研究旨在开发注释指南和黄金标准语料库,以促进构建未来用于挖掘文献中表型定义的自动化方法。此外,我们的目标是提高对文献中发表的表型定义的呈现方式以及我们如何为未来的文本挖掘任务对其进行注释的理解。
两名注释员在句子级别上手动注释语料库,以确定是否存在表型定义的证据。提出了三个主要类别(包含、中间和排除),共有十个维度,用于描述在发表文献中呈现表型定义的主要上下文模式和提示。使用开发的注释指南对包含 3971 个句子的语料库进行注释:3971 个句子中的 1923 个(48.4%)为包含类别,3971 个句子中的 1851 个(46.6%)为中间类别,3971 个句子中的 2273 个(57.2%)为排除类别。注释的句子数最多的是“生物医学和程序”维度的 1449 个(36.5%)。注释的句子数最少的是“自然语言处理的使用”维度的 49 个(1.2%)。总体跨注释员一致性百分比为 97.8%。百分比和 Kappa 统计数据也显示了所有维度的跨注释员高度一致性。
语料库和注释指南可作为在文献中注释和挖掘表型定义的基础信息学方法,并可用于以后的文本挖掘应用。