Yasir Muhammad, Karim Asad Mustafa, Malik Sumera Kausar, Bajaffer Amal A, Azhar Esam I
Special Infectious Agents Unit, King Fahd Medical Research Center, King Abdulaziz University, Jeddah 21589, Saudi Arabia.
Department of Medical Laboratory Sciences, Faculty of Applied Medical Sciences, King Abdulaziz University, Jeddah 21589, Saudi Arabia.
Saudi J Biol Sci. 2022 May;29(5):3687-3693. doi: 10.1016/j.sjbs.2022.02.047. Epub 2022 Mar 4.
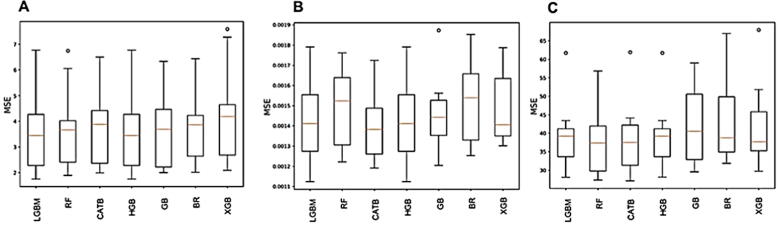
The lowest concentration of an antimicrobial agent that can inhibit the visible growth of a microorganism after overnight incubation is called as minimum inhibitory concentration (MIC) and the drug prescriptions are made on the basis of MIC data to ensure successful treatment outcomes. Therefore, reliable antimicrobial susceptibility data is crucial, and it will help clinicians about which drug to prescribe. Although few prediction studies based on strategies have been conducted, however, no single machine learning (ML) modelling has been carried out to predict MICs in . In this study, we propose a ML based approach that can predict MICs of a specific antibiotic using unitigs sequences data. We retrieved genomes from European Nucleotide Archive and NCBI and analysed them combined with their respective MIC data for cefixime, ciprofloxacin, and azithromycin and then we constructed unitigs by using de Brujin graphs. We built and compared 35 different ML regression models to predict MICs. Our results demonstrate that RandomForest and CATBoost models showed best performance in predicting MICs of the three antibiotics. The coefficient of determination, R, (a statistical measure of how well the regression predictions approximate the real data points) for cefixime, ciprofloxacin, and azithromycin was 0.75787, 0.77241, and 0.79009 respectively using RandomForest. For CATBoost model, the R value was 0.74570, 0.77393, and 0.79317 for cefixime, ciprofloxacin, and azithromycin respectively. Lastly, using feature importance, we explore the important genomic regions identified by the models for predicting MICs. The major mutations which are responsible for resistance against these three antibiotics were chosen by ML models as a top feature in case of each antibiotics. CATBoost, DecisionTree, GradientBoosting, and RandomForest regression models chose the same unitigs which are responsible for resistance. This unitigs-based strategy for developing models for MIC prediction, clinical diagnostics, and surveillance can be applicable for other critical bacterial pathogens.
抗菌剂在过夜培养后能够抑制微生物可见生长的最低浓度被称为最低抑菌浓度(MIC),并且药物处方是基于MIC数据制定的,以确保治疗取得成功。因此,可靠的抗菌药敏数据至关重要,它将帮助临床医生确定开哪种药。尽管已经进行了一些基于策略的预测研究,然而,尚未开展任何单一的机器学习(ML)建模来预测MIC。在本研究中,我们提出了一种基于ML的方法,该方法可以使用重叠群序列数据预测特定抗生素的MIC。我们从欧洲核苷酸档案库和NCBI检索了基因组,并结合它们各自针对头孢克肟、环丙沙星和阿奇霉素的MIC数据进行分析,然后我们使用德布鲁因图构建了重叠群。我们构建并比较了35种不同的ML回归模型来预测MIC。我们的结果表明,随机森林和CATBoost模型在预测这三种抗生素的MIC方面表现最佳。使用随机森林时,头孢克肟、环丙沙星和阿奇霉素的决定系数R(衡量回归预测与实际数据点拟合程度的统计量)分别为0.75787、0.77241和0.79009。对于CATBoost模型,头孢克肟、环丙沙星和阿奇霉素的R值分别为0.74570、0.77393和0.79317。最后,利用特征重要性,我们探索了模型识别出的用于预测MIC的重要基因组区域。对于每种抗生素,ML模型选择了导致对这三种抗生素耐药的主要突变作为顶级特征。CATBoost、决策树、梯度提升和随机森林回归模型选择了相同的负责耐药性的重叠群。这种基于重叠群的策略用于开发MIC预测、临床诊断和监测模型,可应用于其他关键的细菌病原体。