National Center for Biotechnology Information (NCBI), National Library of Medicine (NLM), National Institutes of Health (NIH), Bethesda, MD 20894, USA.
University of Delaware, Newark, DE 19716, USA.
Brief Bioinform. 2022 Sep 20;23(5). doi: 10.1093/bib/bbac282.
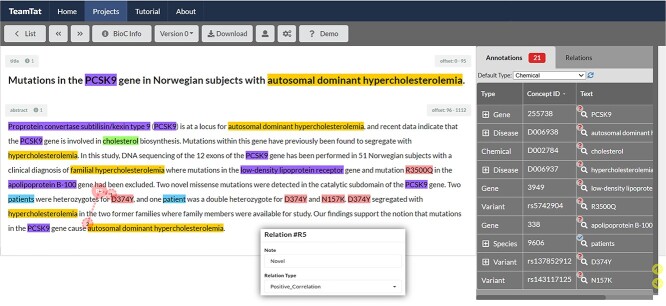
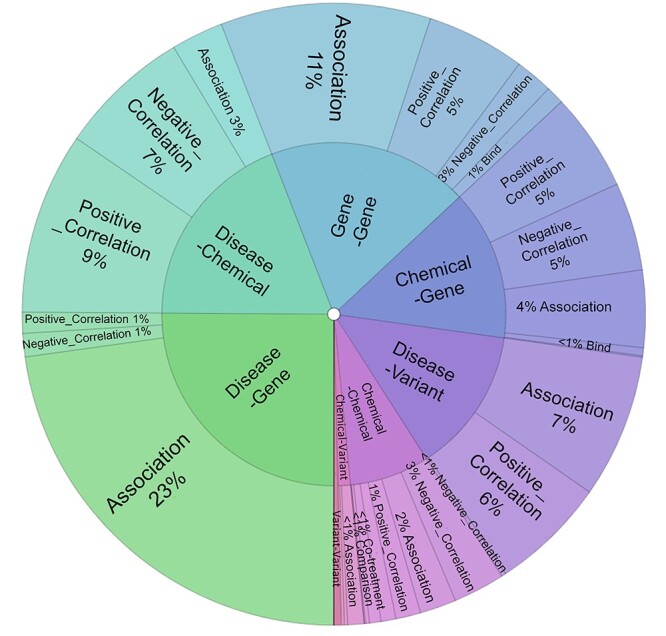
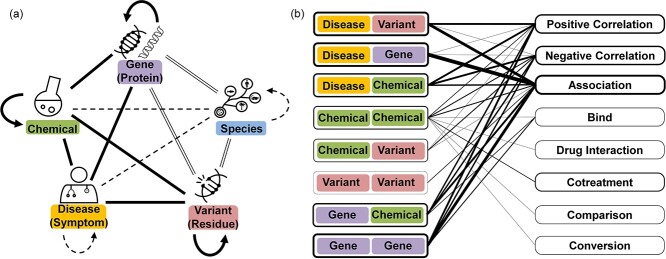
Automated relation extraction (RE) from biomedical literature is critical for many downstream text mining applications in both research and real-world settings. However, most existing benchmarking datasets for biomedical RE only focus on relations of a single type (e.g. protein-protein interactions) at the sentence level, greatly limiting the development of RE systems in biomedicine. In this work, we first review commonly used named entity recognition (NER) and RE datasets. Then, we present a first-of-its-kind biomedical relation extraction dataset (BioRED) with multiple entity types (e.g. gene/protein, disease, chemical) and relation pairs (e.g. gene-disease; chemical-chemical) at the document level, on a set of 600 PubMed abstracts. Furthermore, we label each relation as describing either a novel finding or previously known background knowledge, enabling automated algorithms to differentiate between novel and background information. We assess the utility of BioRED by benchmarking several existing state-of-the-art methods, including Bidirectional Encoder Representations from Transformers (BERT)-based models, on the NER and RE tasks. Our results show that while existing approaches can reach high performance on the NER task (F-score of 89.3%), there is much room for improvement for the RE task, especially when extracting novel relations (F-score of 47.7%). Our experiments also demonstrate that such a rich dataset can successfully facilitate the development of more accurate, efficient and robust RE systems for biomedicine. Availability: The BioRED dataset and annotation guidelines are freely available at https://ftp.ncbi.nlm.nih.gov/pub/lu/BioRED/.
从生物医学文献中自动提取关系(RE)对于研究和实际环境中的许多下游文本挖掘应用都至关重要。然而,大多数现有的生物医学 RE 基准数据集仅关注句子级别的单一类型的关系(例如蛋白质-蛋白质相互作用),极大地限制了生物医学中 RE 系统的发展。在这项工作中,我们首先回顾了常用的命名实体识别(NER)和 RE 数据集。然后,我们提出了一种首创的生物医学关系提取数据集(BioRED),该数据集具有多种实体类型(例如基因/蛋白质、疾病、化学物质)和关系对(例如基因-疾病;化学-化学),涵盖了 600 篇 PubMed 摘要。此外,我们将每个关系标记为描述新发现或先前已知的背景知识,使自动算法能够区分新信息和背景信息。我们通过在 NER 和 RE 任务上对几种现有的最先进方法(包括基于 Transformer 的双向编码器表示(BERT)的模型)进行基准测试,评估了 BioRED 的效用。我们的结果表明,虽然现有的方法在 NER 任务上可以达到很高的性能(F1 得分为 89.3%),但在 RE 任务上仍有很大的改进空间,特别是在提取新关系时(F1 得分为 47.7%)。我们的实验还表明,这样一个丰富的数据集可以成功地促进更准确、高效和鲁棒的生物医学 RE 系统的开发。
BioRED 数据集和注释指南可在 https://ftp.ncbi.nlm.nih.gov/pub/lu/BioRED/ 上免费获取。