Department of Computer Science, Illinois Institute of Technology, Chicago, IL, United States of America.
Department of Social Sciences, Illinois Institute of Technology, Chicago, IL, United States of America.
PLoS One. 2022 Jul 21;17(7):e0271714. doi: 10.1371/journal.pone.0271714. eCollection 2022.
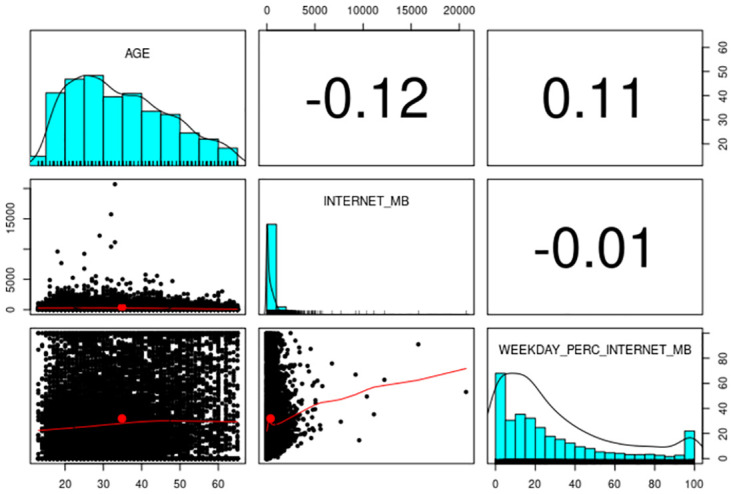
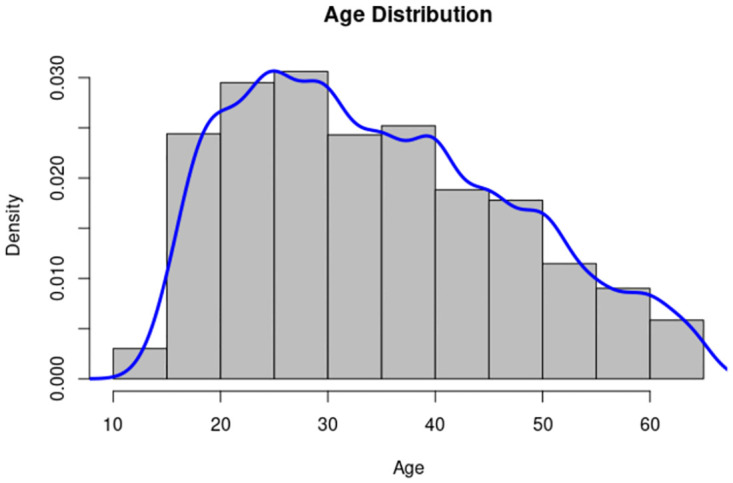
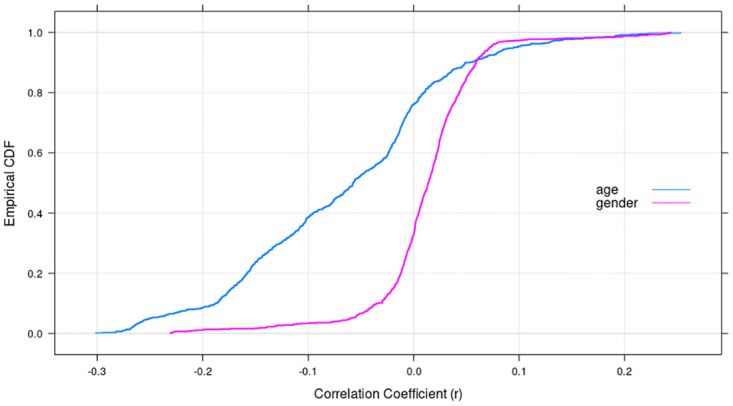
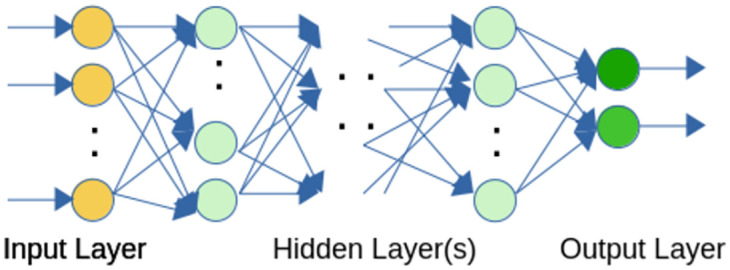
The systematic monitoring of private communications through the use of information technology pervades the digital age. One result of this is the potential availability of vast amount of data tracking the characteristics of mobile network users. Such data is becoming increasingly accessible for commercial use, while the accessibility of such data raises questions about the degree to which personal information can be protected. Existing regulations may require the removal of personally-identifiable information (PII) from datasets before they can be processed, but research now suggests that powerful machine learning classification methods are capable of targeting individuals for personalized marketing purposes, even in the absence of PII. This study aims to demonstrate how machine learning methods can be deployed to extract demographic characteristics. Specifically, we investigate whether key demographics-gender and age-of mobile users can be accurately identified by third parties using deep learning techniques based solely on observations of the user's interactions within the network. Using an anonymized dataset from a Latin American country, we show the relative ease by which PII in terms of the age and gender demographics can be inferred; specifically, our neural networks model generates an estimate for gender with an accuracy rate of 67%, outperforming decision tree, random forest, and gradient boosting models by a significant margin. Neural networks achieve an even higher accuracy rate of 78% in predicting the subscriber age. These results suggest the need for a more robust regulatory framework governing the collection of personal data to safeguard users from predatory practices motivated by fraudulent intentions, prejudices, or consumer manipulation. We discuss in particular how advances in machine learning have chiseled away a number of General Data Protection Regulation (GDPR) articles designed to protect consumers from the imminent threat of privacy violations.
通过信息技术对私人通信进行系统监控在数字时代已经无处不在。其结果之一是,跟踪移动网络用户特征的大量数据越来越容易获取。这些数据越来越容易被商业利用,而这些数据的可获取性引发了人们对于个人信息可以在多大程度上得到保护的疑问。现有法规可能要求在对数据集进行处理之前,将个人身份信息(PII)从数据集中删除,但研究表明,即使没有 PII,强大的机器学习分类方法也能够针对个人进行个性化营销。本研究旨在展示机器学习方法如何被用于提取人口统计学特征。具体来说,我们调查了第三方是否可以仅通过观察用户在网络中的交互,使用基于深度学习的技术准确识别移动用户的性别和年龄等关键人口统计信息。我们使用来自拉丁美洲国家的匿名数据集,展示了通过观察用户在网络中的交互来推断 PII(即年龄和性别人口统计信息)的相对容易程度;具体来说,我们的神经网络模型生成的性别估计准确率为 67%,比决策树、随机森林和梯度提升模型的准确率有显著提高。神经网络在预测用户年龄方面的准确率甚至更高,达到了 78%。这些结果表明,需要更强大的监管框架来规范个人数据的收集,以保护用户免受欺诈意图、偏见或消费者操纵等动机的掠夺性做法的侵害。我们特别讨论了机器学习的进步如何削弱了一些旨在保护消费者免受隐私侵犯威胁的通用数据保护条例(GDPR)条款。