Back Andrew D, Wiles Janet
School of Information Technology and Electrical Engineering, The University of Queensland, Brisbane, QLD 4072, Australia.
Entropy (Basel). 2022 Jun 22;24(7):859. doi: 10.3390/e24070859.
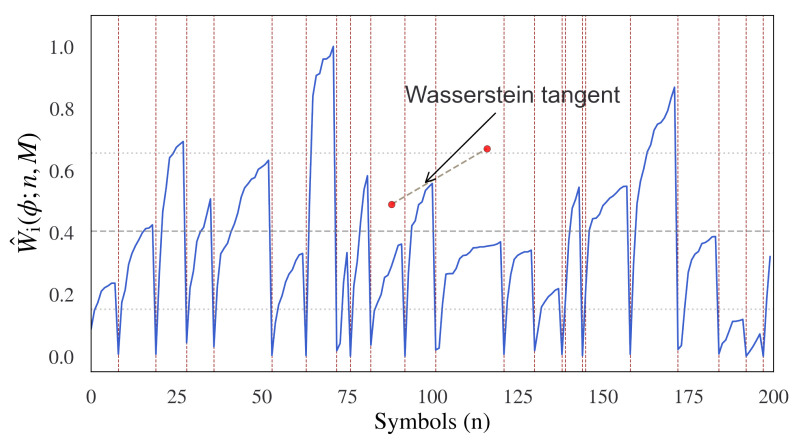
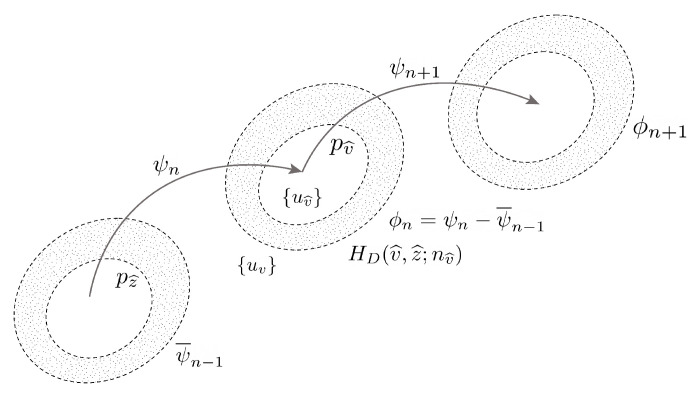
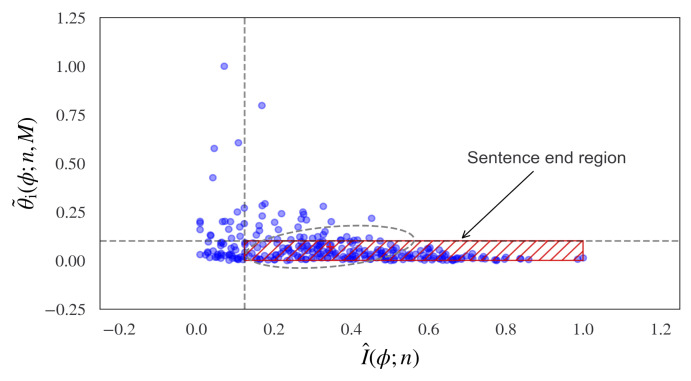
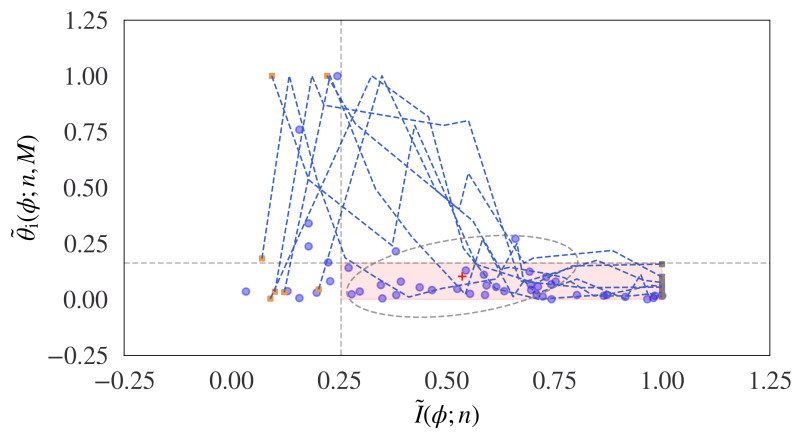
Estimating sentence-like units and sentence boundaries in human language is an important task in the context of natural language understanding. While this topic has been considered using a range of techniques, including rule-based approaches and supervised and unsupervised algorithms, a common aspect of these methods is that they inherently rely on a priori knowledge of human language in one form or another. Recently we have been exploring synthetic languages based on the concept of modeling behaviors using emergent languages. These synthetic languages are characterized by a small alphabet and limited vocabulary and grammatical structure. A particular challenge for synthetic languages is that there is generally no a priori language model available, which limits the use of many natural language processing methods. In this paper, we are interested in exploring how it may be possible to discover natural 'chunks' in synthetic language sequences in terms of sentence-like units. The problem is how to do this with no linguistic or semantic language model. Our approach is to consider the problem from the perspective of information theory. We extend the basis of information geometry and propose a new concept, which we term information topology, to model the incremental flow of information in natural sequences. We introduce an information topology view of the incremental information and incremental tangent angle of the Wasserstein-1 distance of the probabilistic symbolic language input. It is not suggested as a fully viable alternative for sentence boundary detection per se but provides a new conceptual method for estimating the structure and natural limits of information flow in language sequences but without any semantic knowledge. We consider relevant existing performance metrics such as the F-measure and indicate limitations, leading to the introduction of a new information-theoretic global performance based on modeled distributions. Although the methodology is not proposed for human language sentence detection, we provide some examples using human language corpora where potentially useful results are shown. The proposed model shows potential advantages for overcoming difficulties due to the disambiguation of complex language and potential improvements for human language methods.
在自然语言理解的背景下,估计人类语言中类似句子的单元和句子边界是一项重要任务。虽然已经使用了一系列技术来考虑这个主题,包括基于规则的方法以及监督和无监督算法,但这些方法的一个共同方面是它们本质上以某种形式依赖于人类语言的先验知识。最近,我们一直在探索基于使用涌现语言对行为进行建模的概念的合成语言。这些合成语言的特点是字母表小、词汇量有限且语法结构受限。合成语言面临的一个特殊挑战是通常没有可用的先验语言模型,这限制了许多自然语言处理方法的使用。在本文中,我们感兴趣的是探索如何有可能从类似句子的单元的角度在合成语言序列中发现自然的“块”。问题在于如何在没有语言或语义语言模型的情况下做到这一点。我们的方法是从信息论的角度考虑这个问题。我们扩展了信息几何的基础,并提出了一个新的概念,我们称之为信息拓扑,以对自然序列中的信息增量流动进行建模。我们引入了概率符号语言输入的Wasserstein-1距离的增量信息和增量切线角的信息拓扑视图。它本身并不是作为句子边界检测的完全可行替代方案提出的,而是提供了一种新的概念方法,用于估计语言序列中信息流的结构和自然限制,而无需任何语义知识。我们考虑了相关的现有性能指标,如F值,并指出了局限性,从而引入了基于建模分布的新的信息论全局性能指标。虽然该方法不是为人类语言句子检测提出的,但我们提供了一些使用人类语言语料库的示例,展示了可能有用的结果。所提出的模型显示出在克服复杂语言歧义带来的困难方面的潜在优势,以及对人类语言方法的潜在改进。