Kristiansen Thomas Birk, Kristensen Kent, Uffelmann Jakob, Brandslund Ivan
Ishøjcentrets Læger, Ishøj, Denmark.
Institute of Law, University of Southern Denmark, Odense, Denmark.
Front Digit Health. 2022 Jul 22;4:862095. doi: 10.3389/fdgth.2022.862095. eCollection 2022.
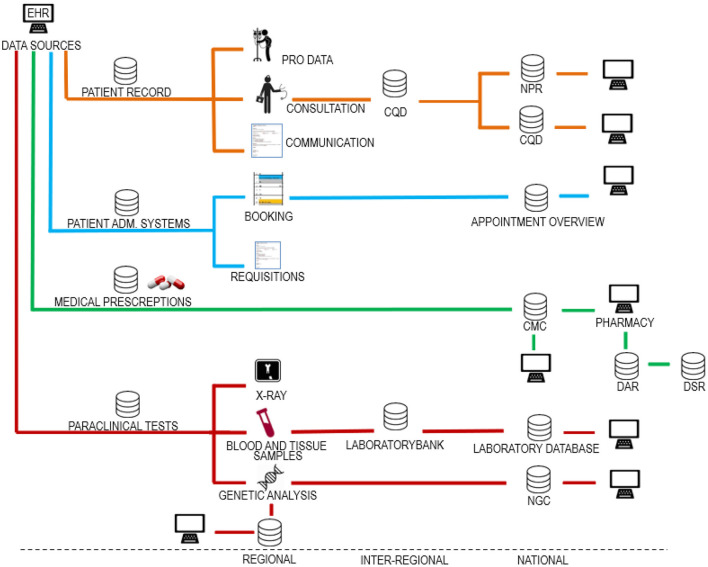
This paper reviews dilemmas and implications of erroneous data for clinical implementation of AI. It is well-known that if erroneous and biased data are used to train AI, there is a risk of systematic error. However, even perfectly trained AI applications can produce faulty outputs if fed with erroneous inputs. To counter such problems, we suggest 3 steps: (1) AI should focus on data of the highest quality, in essence paraclinical data and digital images, (2) patients should be granted simple access to the input data that feed the AI, and granted a right to request changes to erroneous data, and (3) automated high-throughput methods for error-correction should be implemented in domains with faulty data when possible. Also, we conclude that erroneous data is a reality even for highly reputable Danish data sources, and thus, legal framework for the correction of errors is universally needed.
本文回顾了错误数据在人工智能临床应用中所带来的困境及影响。众所周知,如果使用错误和有偏差的数据来训练人工智能,就存在系统误差的风险。然而,即使是训练得非常完美的人工智能应用程序,如果输入错误的数据,也可能产生错误的输出。为应对此类问题,我们建议采取三个步骤:(1)人工智能应专注于最高质量的数据,本质上是辅助临床数据和数字图像;(2)应给予患者简单的途径来获取输入到人工智能中的数据,并赋予他们请求更改错误数据的权利;(3)在可能存在错误数据的领域,应尽可能采用自动化的高通量纠错方法。此外,我们得出结论,即使对于声誉极高的丹麦数据源来说,错误数据也是现实存在的,因此,普遍需要用于纠正错误的法律框架。