Lifschitz Sergio, Haeusler Edward H, Catanho Marcos, Miranda Antonio B de, Armas Elvismary Molina de, Heine Alexandre, Moreira Sergio G M P, Tristão Cristian
Departamento de Informática, Pontifícia Universidade Católica do Rio de Janeiro (PUC-Rio), Rio de Janeiro 22451-900, Brazil.
Lab. Genética Molecular de Microrganismos, Fundação Oswaldo Cruz (FIOCRUZ), Rio de Janeiro 21040-900, Brazil.
BioTech (Basel). 2022 Jul 30;11(3):31. doi: 10.3390/biotech11030031.
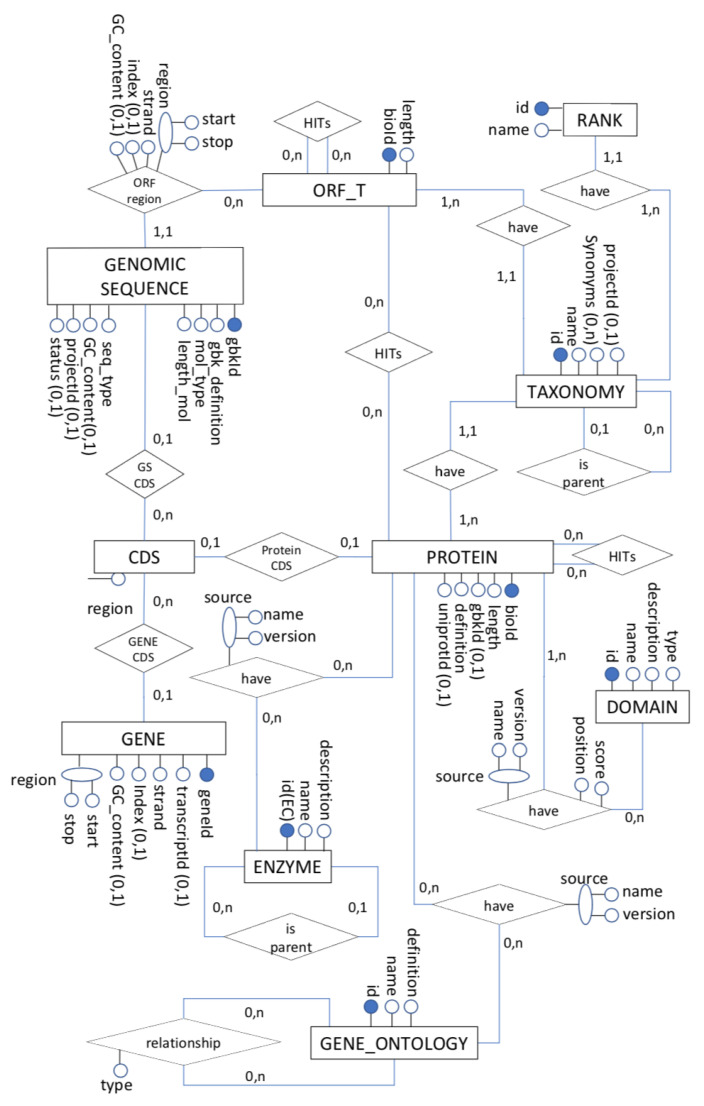
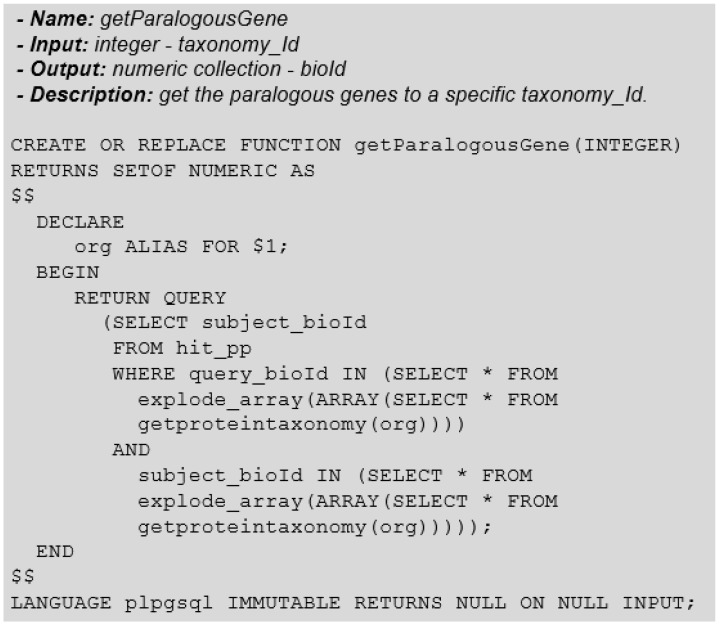
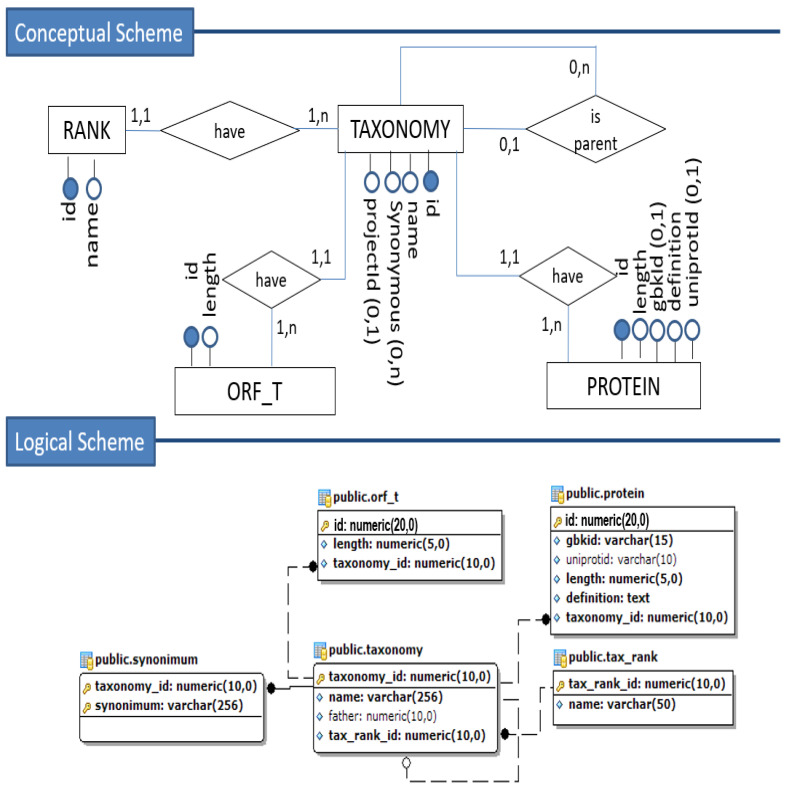
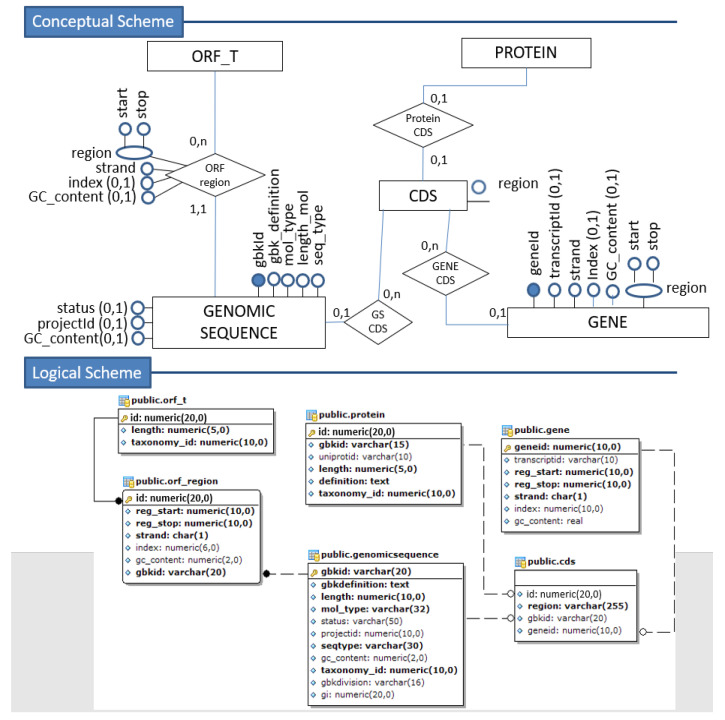
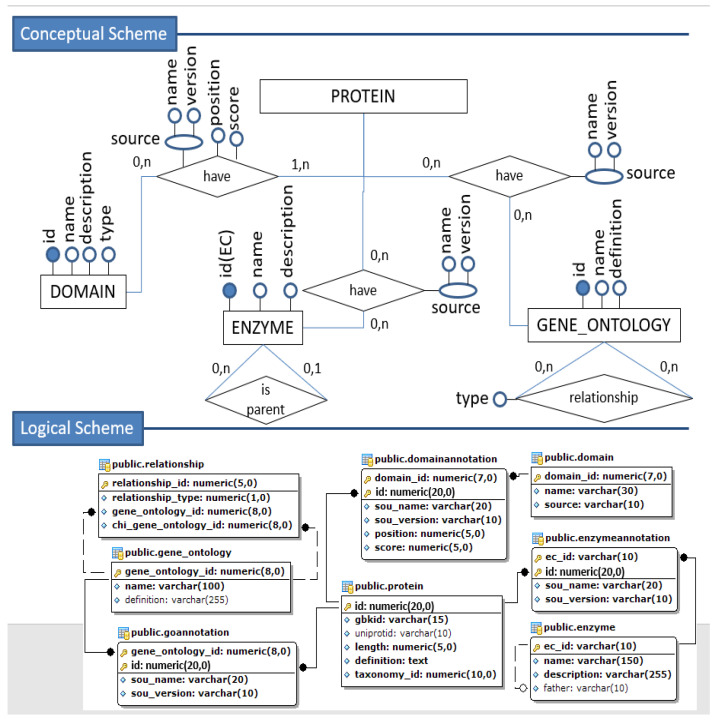
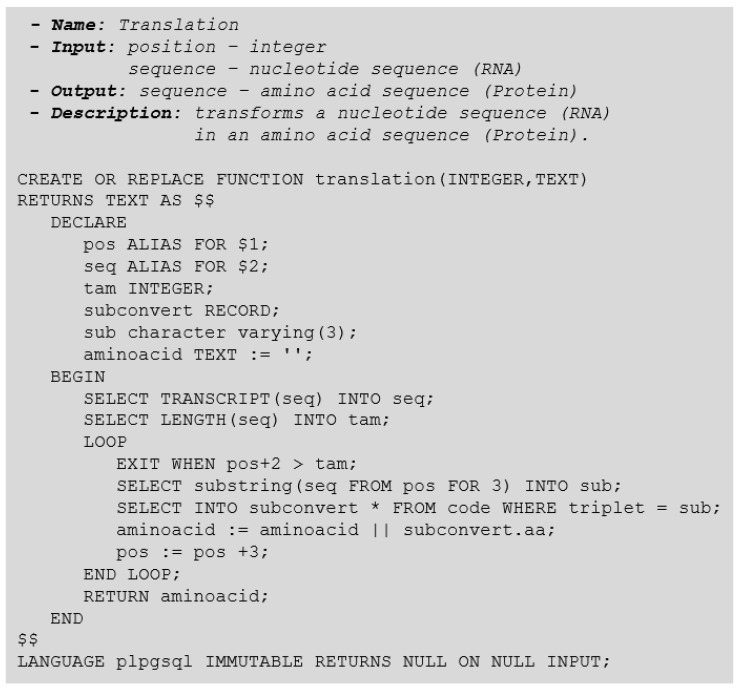
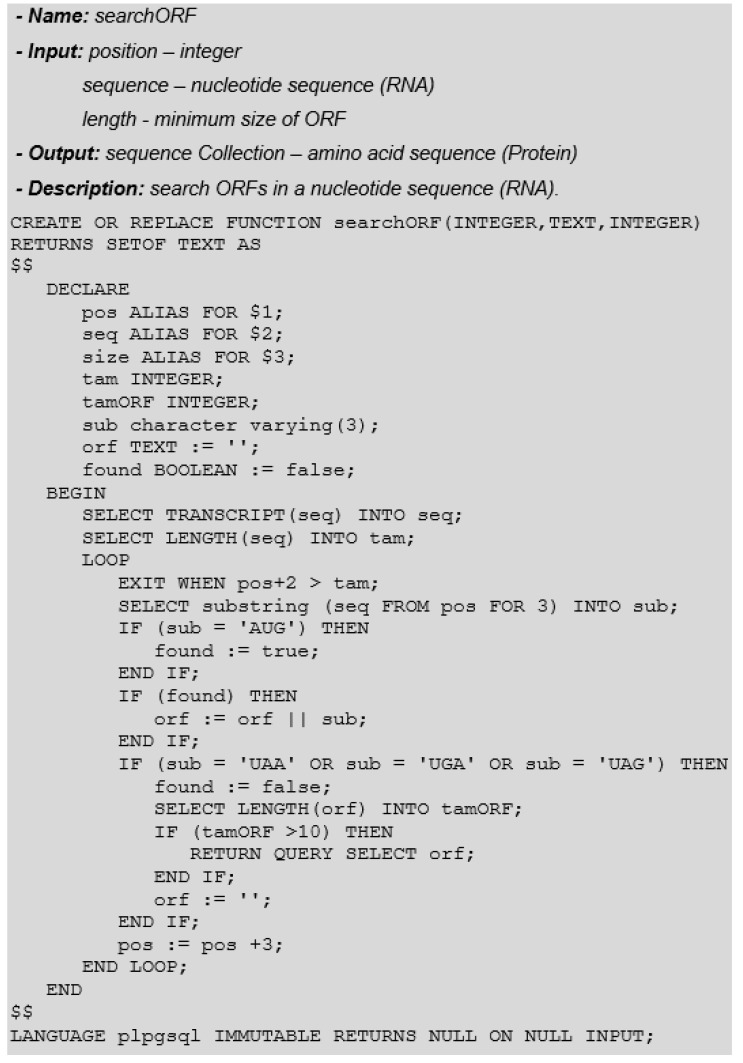
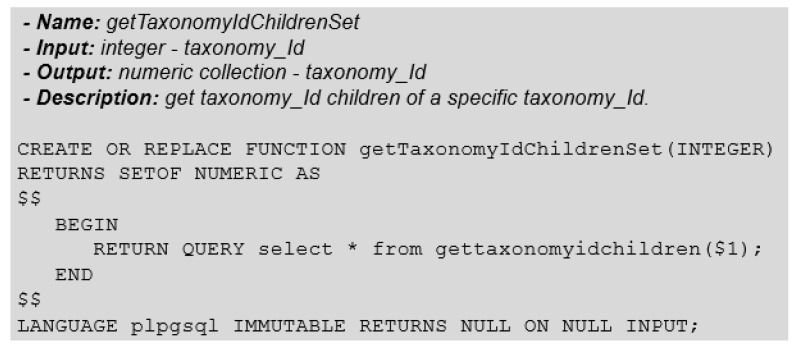
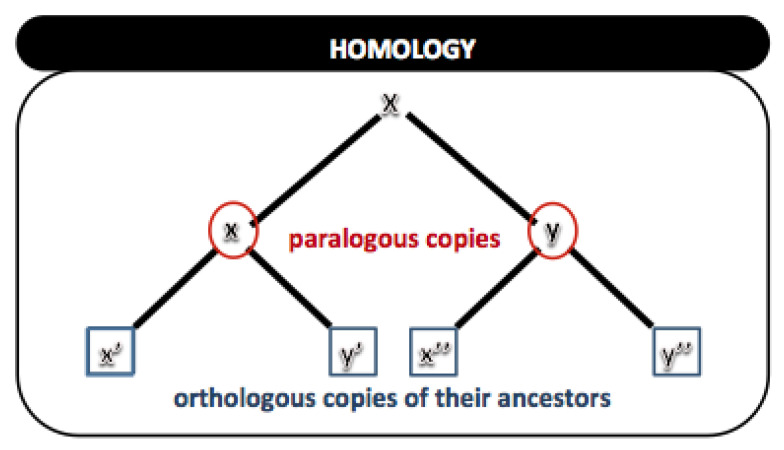
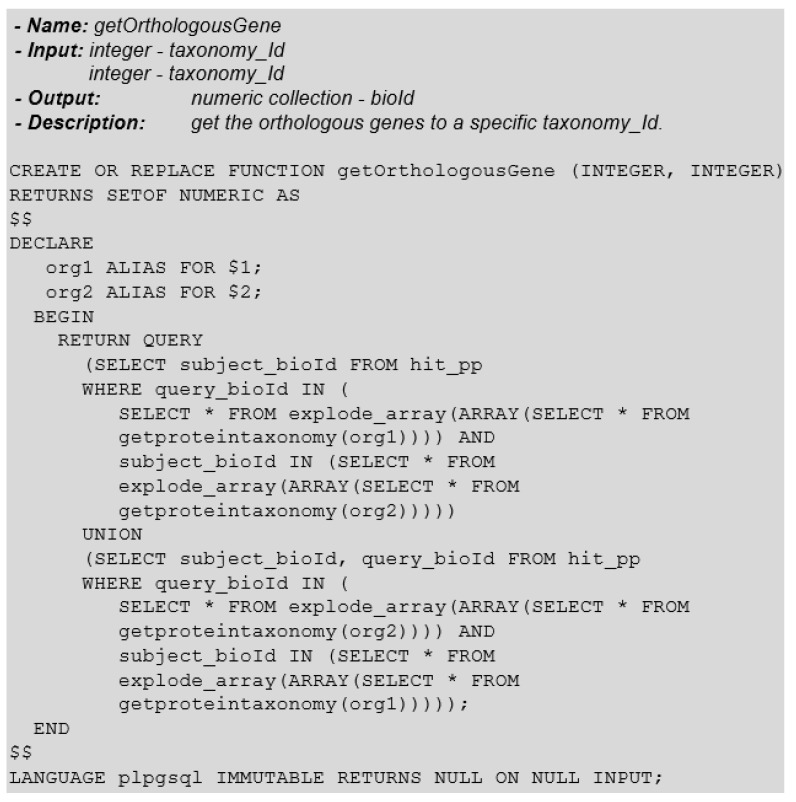
DNA sequencers output a large set of very long biological data strings that we should persist in databases rather than basic text file systems. Many different data models and database management systems (DBMS) may deal with both storage and efficiency issues regarding genomic datasets. Specifically, there is a need for handling strings with variable sizes while keeping their biological meaning. Relational database management systems (RDBMS) provide several data types that could be further explored for the genomics context. Besides, they enforce integrity, consistency, and enable good abstractions for more conventional data. We propose the relational text data type to represent and manipulate biological sequences and their derivatives. We present a logical schema for representing the core biological information, which may be inferred from a given biological conceptual data schema and the corresponding function manipulations. We implement and evaluate these stored functions into an actual RDBMS for both efficacy and efficiency. We show that it is possible to enforce basic and complex requirements for the genomic domain. We claim that the well-established relational text data type in RDBMS may appropriately handle the representation and persistency of biological sequences. We base our approach on the idea of domain-specific abstract data types that can store data with semantically defined functions while hiding those details from non-technical end-users.
DNA测序仪输出大量非常长的生物数据字符串,我们应该将其保存在数据库中,而不是基本的文本文件系统中。许多不同的数据模型和数据库管理系统(DBMS)可以处理有关基因组数据集的存储和效率问题。具体而言,需要处理大小可变的字符串,同时保留其生物学意义。关系数据库管理系统(RDBMS)提供了几种数据类型,可在基因组学背景下进一步探索。此外,它们可确保完整性、一致性,并为更传统的数据提供良好的抽象。我们提出使用关系文本数据类型来表示和处理生物序列及其衍生物。我们提出了一个用于表示核心生物信息的逻辑模式,该模式可从给定的生物概念数据模式和相应的函数操作中推断出来。我们将这些存储函数实现并评估到实际的RDBMS中,以确保有效性和效率。我们表明,对基因组领域执行基本和复杂的要求是可能的。我们声称,RDBMS中成熟的关系文本数据类型可以适当地处理生物序列的表示和持久性。我们的方法基于特定领域抽象数据类型的思想,该类型可以存储具有语义定义函数的数据,同时向非技术终端用户隐藏这些细节。