Hahn Waldemar, Schütte Katharina, Schultz Kristian, Wolkenhauer Olaf, Sedlmayr Martin, Schuler Ulrich, Eichler Martin, Bej Saptarshi, Wolfien Markus
Institute for Medical Informatics and Biometry, Faculty of Medicine Carl Gustav Carus, Technische Universität Dresden, Fetscherstraße 74, 01307 Dresden, Germany.
University Palliative Center, University Hospital Carl Gustav Carus, Technische Universität Dresden, Fetscherstraße 74, 01307 Dresden, Germany.
J Pers Med. 2022 Aug 4;12(8):1278. doi: 10.3390/jpm12081278.
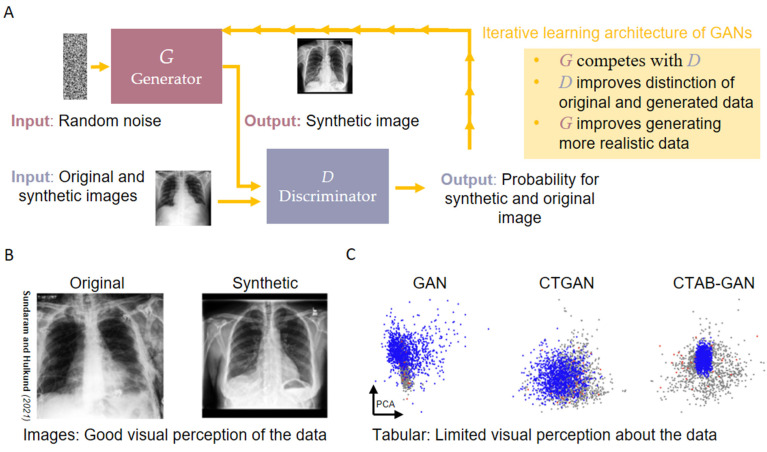
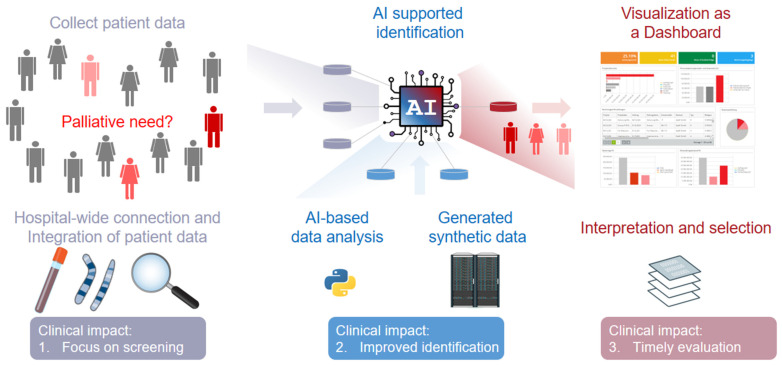
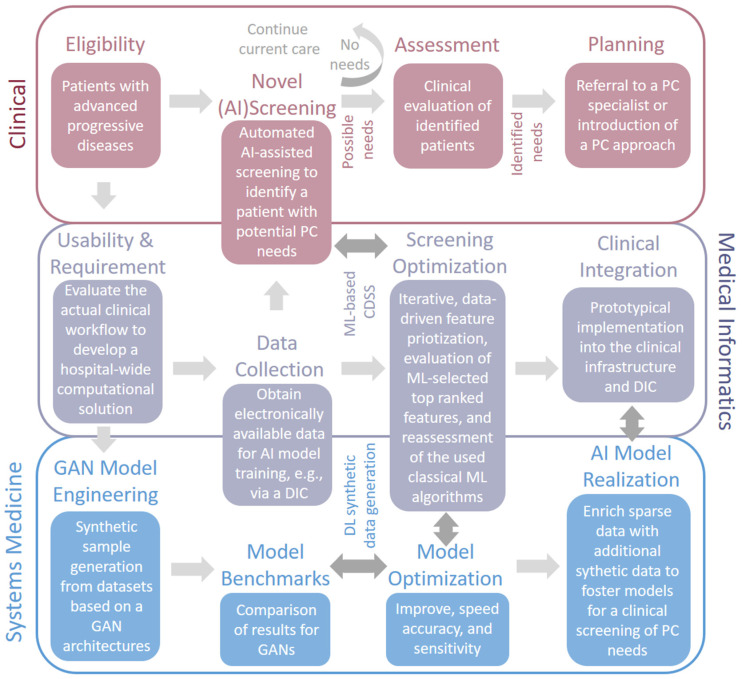
AI model development for synthetic data generation to improve Machine Learning (ML) methodologies is an integral part of research in Computer Science and is currently being transferred to related medical fields, such as Systems Medicine and Medical Informatics. In general, the idea of personalized decision-making support based on patient data has driven the motivation of researchers in the medical domain for more than a decade, but the overall sparsity and scarcity of data are still major limitations. This is in contrast to currently applied technology that allows us to generate and analyze patient data in diverse forms, such as tabular data on health records, medical images, genomics data, or even audio and video. One solution arising to overcome these data limitations in relation to medical records is the synthetic generation of tabular data based on real world data. Consequently, ML-assisted decision-support can be interpreted more conveniently, using more relevant patient data at hand. At a methodological level, several state-of-the-art ML algorithms generate and derive decisions from such data. However, there remain key issues that hinder a broad practical implementation in real-life clinical settings. In this review, we will give for the first time insights towards current perspectives and potential impacts of using synthetic data generation in palliative care screening because it is a challenging prime example of highly individualized, sparsely available patient information. Taken together, the reader will obtain initial starting points and suitable solutions relevant for generating and using synthetic data for ML-based screenings in palliative care and beyond.
用于生成合成数据以改进机器学习(ML)方法的人工智能模型开发是计算机科学研究的一个组成部分,目前正被应用于相关医学领域,如系统医学和医学信息学。总体而言,基于患者数据的个性化决策支持理念已经驱动医学领域的研究人员长达十多年,但数据的整体稀疏性和稀缺性仍然是主要限制因素。这与当前应用的技术形成对比,当前技术使我们能够生成和分析各种形式的患者数据,如健康记录中的表格数据、医学图像、基因组数据,甚至音频和视频。为克服与医疗记录相关的数据限制而出现的一种解决方案是基于真实世界数据合成生成表格数据。因此,利用手头更多相关的患者数据,可以更方便地解释ML辅助决策支持。在方法层面,几种先进的ML算法从这些数据中生成并得出决策。然而,仍然存在一些关键问题阻碍其在现实临床环境中的广泛实际应用。在本综述中,我们将首次深入探讨在姑息治疗筛查中使用合成数据生成的当前观点和潜在影响,因为这是一个极具挑战性的典型例子,涉及高度个性化、难以获取的患者信息。综上所述,读者将获得与在姑息治疗及其他领域基于ML的筛查中生成和使用合成数据相关的初步起点和合适解决方案。