Department of Medical Oncology, Dana-Farber Cancer Institute, Boston, MA, USA.
Cancer Program, Broad Institute of MIT and Harvard, Cambridge, MA, USA.
Genome Biol. 2022 Aug 26;23(1):180. doi: 10.1186/s13059-022-02751-6.
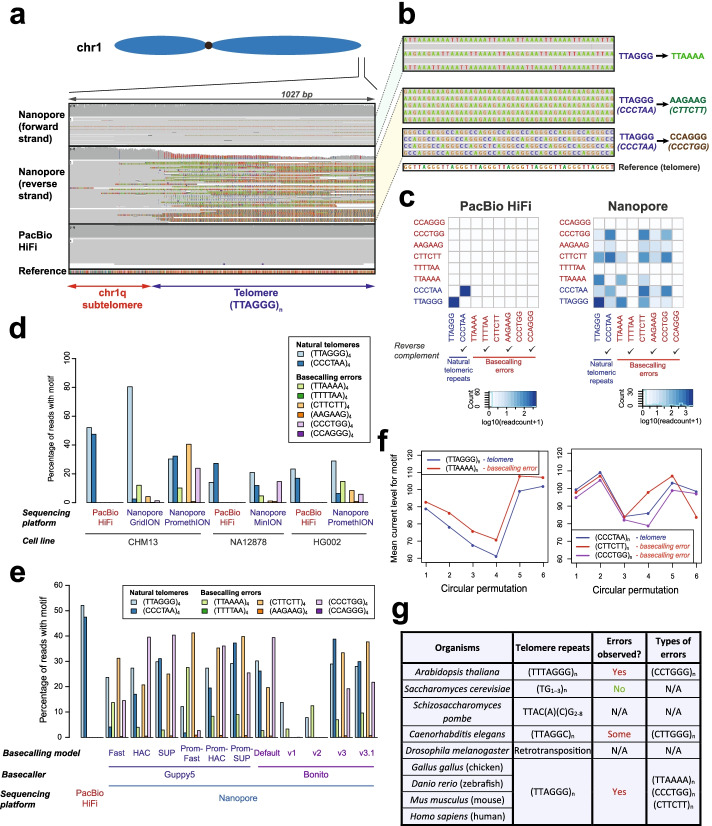
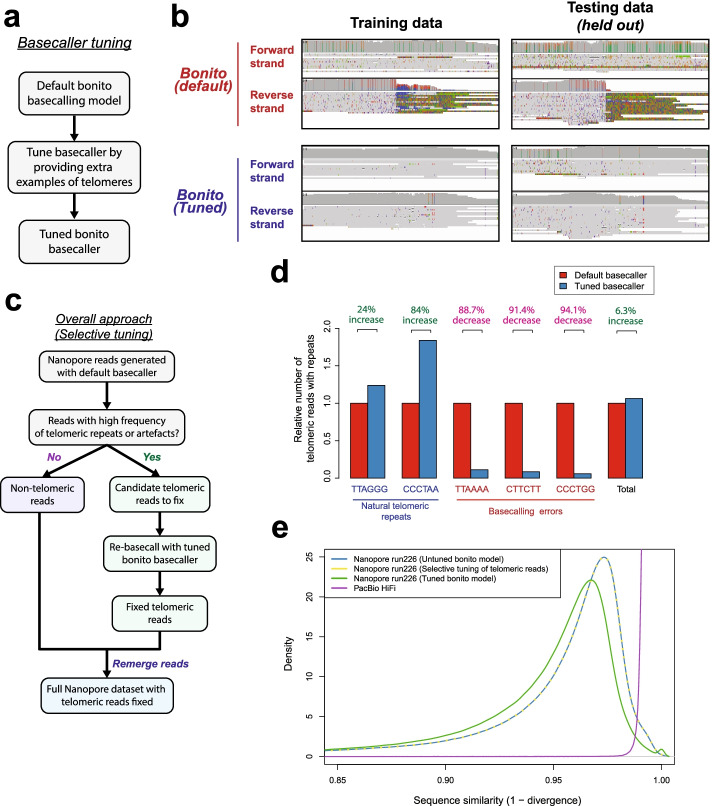
Nanopore long-read sequencing is an emerging approach for studying genomes, including long repetitive elements like telomeres. Here, we report extensive basecalling induced errors at telomere repeats across nanopore datasets, sequencing platforms, basecallers, and basecalling models. We find that telomeres in many organisms are frequently miscalled. We demonstrate that tuning of nanopore basecalling models leads to improved recovery and analysis of telomeric regions, with minimal negative impact on other genomic regions. We highlight the importance of verifying nanopore basecalls in long, repetitive, and poorly defined regions, and showcase how artefacts can be resolved by improvements in nanopore basecalling models.
纳米孔长读测序是一种新兴的研究基因组的方法,包括端粒等长重复元件。在这里,我们报告了在纳米孔数据集、测序平台、碱基调用器和碱基调用模型中,端粒重复序列的广泛碱基调用诱导错误。我们发现许多生物的端粒经常被误报。我们证明,纳米孔碱基调用模型的调整可以改善端粒区域的恢复和分析,而对其他基因组区域的负面影响最小。我们强调了在长、重复和定义不明确的区域中验证纳米孔碱基调用的重要性,并展示了如何通过改进纳米孔碱基调用模型来解决伪影问题。