Tong Chau, Margolin Drew, Chunara Rumi, Niederdeppe Jeff, Taylor Teairah, Dunbar Natalie, King Andy J
Department of Communication, Cornell University, Ithaca, NY, United States.
Department of Biostatistics, School of Global Public Health, New York University, New York, NY, United States.
JMIR Med Inform. 2022 Aug 30;10(8):e37862. doi: 10.2196/37862.
Common methods for extracting content in health communication research typically involve using a set of well-established queries, often names of medical procedures or diseases, that are often technical or rarely used in the public discussion of health topics. Although these methods produce high recall (ie, retrieve highly relevant content), they tend to overlook health messages that feature colloquial language and layperson vocabularies on social media. Given how such messages could contain misinformation or obscure content that circumvents official medical concepts, correctly identifying (and analyzing) them is crucial to the study of user-generated health content on social media platforms.
Health communication scholars would benefit from a retrieval process that goes beyond the use of standard terminologies as search queries. Motivated by this, this study aims to put forward a search term identification method to improve the retrieval of user-generated health content on social media. We focused on cancer screening tests as a subject and YouTube as a platform case study.
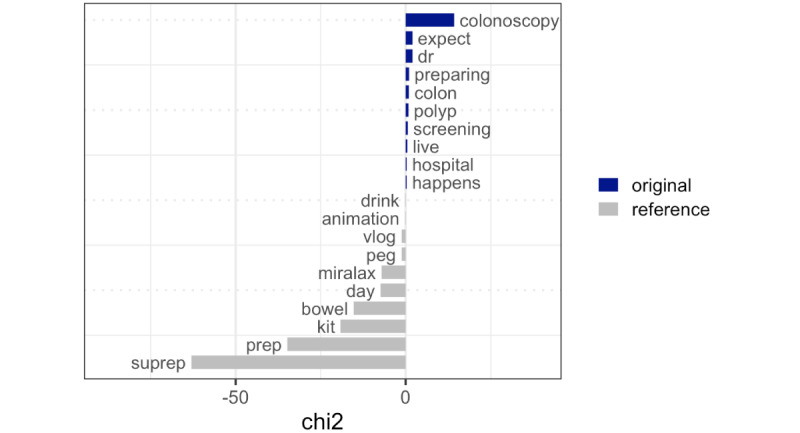
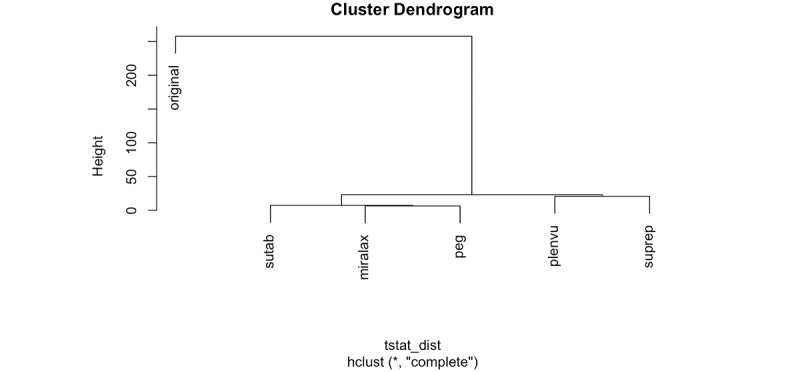
We retrieved YouTube videos using cancer screening procedures (colonoscopy, fecal occult blood test, mammogram, and pap test) as seed queries. We then trained word embedding models using text features from these videos to identify the nearest neighbor terms that are semantically similar to cancer screening tests in colloquial language. Retrieving more YouTube videos from the top neighbor terms, we coded a sample of 150 random videos from each term for relevance. We then used text mining to examine the new content retrieved from these videos and network analysis to inspect the relations between the newly retrieved videos and videos from the seed queries.
The top terms with semantic similarities to cancer screening tests were identified via word embedding models. Text mining analysis showed that the 5 nearest neighbor terms retrieved content that was novel and contextually diverse, beyond the content retrieved from cancer screening concepts alone. Results from network analysis showed that the newly retrieved videos had at least one total degree of connection (sum of indegree and outdegree) with seed videos according to YouTube relatedness measures.
We demonstrated a retrieval technique to improve recall and minimize precision loss, which can be extended to various health topics on YouTube, a popular video-sharing social media platform. We discussed how health communication scholars can apply the technique to inspect the performance of the retrieval strategy before investing human coding resources and outlined suggestions on how such a technique can be extended to other health contexts.
健康传播研究中提取内容的常用方法通常涉及使用一组既定的查询词,这些词往往是医疗程序或疾病的名称,通常较为专业,在公众对健康话题的讨论中很少使用。尽管这些方法具有高召回率(即检索出高度相关的内容),但它们往往会忽略社交媒体上以口语化语言和外行词汇为特征的健康信息。鉴于此类信息可能包含错误信息或规避官方医学概念的模糊内容,正确识别(并分析)它们对于研究社交媒体平台上用户生成的健康内容至关重要。
健康传播学者将从超越使用标准术语作为搜索查询的检索过程中受益。受此启发,本研究旨在提出一种搜索词识别方法,以改进社交媒体上用户生成的健康内容的检索。我们将癌症筛查测试作为主题,以YouTube作为平台案例研究。
我们使用癌症筛查程序(结肠镜检查、粪便潜血试验、乳房X线摄影和巴氏试验)作为种子查询来检索YouTube视频。然后,我们使用这些视频的文本特征训练词嵌入模型,以识别在口语化语言中与癌症筛查测试语义相似的最近邻词。从顶级邻词中检索更多YouTube视频,我们对每个词的150个随机视频样本进行相关性编码。然后,我们使用文本挖掘来检查从这些视频中检索到的新内容,并使用网络分析来检查新检索到的视频与种子查询视频之间的关系。
通过词嵌入模型确定了与癌症筛查测试语义相似的顶级词汇。文本挖掘分析表明,5个最近邻词检索到的内容新颖且上下文多样,超出了仅从癌症筛查概念检索到的内容。网络分析结果表明,根据YouTube相关性度量,新检索到的视频与种子视频至少有一个总连接度(入度和出度之和)。
我们展示了一种检索技术,可提高召回率并最大限度地减少精确率损失,该技术可扩展到流行视频分享社交媒体平台YouTube上的各种健康话题。我们讨论了健康传播学者如何在投入人力编码资源之前应用该技术来检查检索策略的性能,并概述了如何将该技术扩展到其他健康背景的建议。