College of Computer and Information Science, Southwest University, Chongqing, 400715, China.
Sci Rep. 2022 Sep 1;12(1):14820. doi: 10.1038/s41598-022-18986-z.
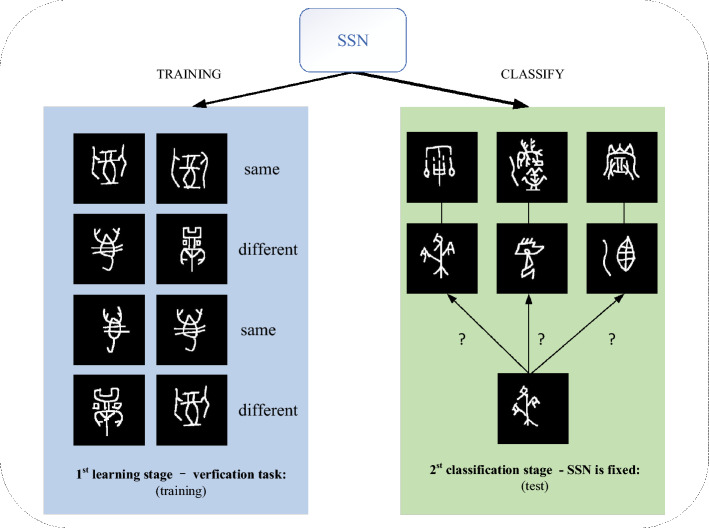
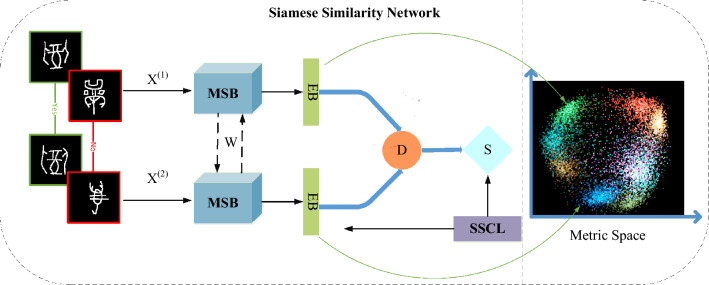
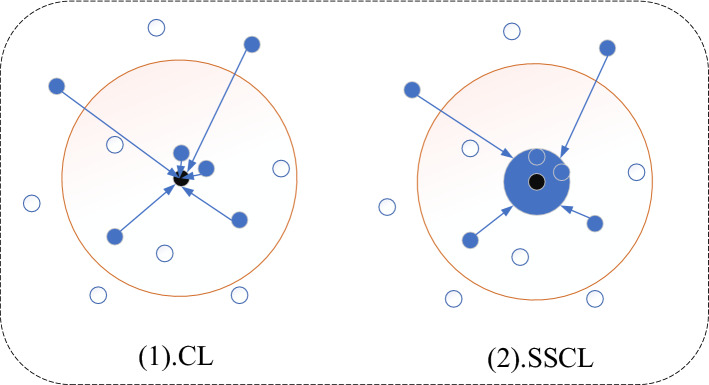
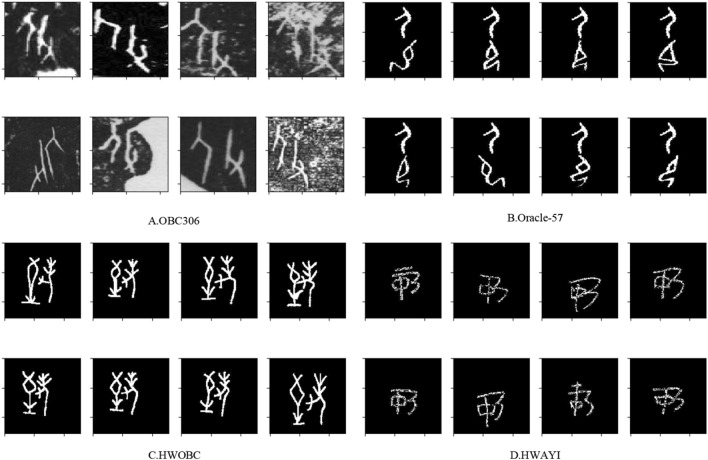
Ancient character recognition is not only important for the study and understanding of ancient history but also has a profound impact on the inheritance and development of national culture. In order to reduce the study of difficult professional knowledge of ancient characters, and meanwhile overcome the lack of data, class imbalance, diversification of glyphs, and open set recognition problems in ancient characters, we propose a Siamese similarity network based on a similarity learning method to directly learn input similarity and then apply the trained model to establish one shot classification task for recognition. Multi-scale fusion backbone structure and embedded structure are proposed in the network to improve the model's ability to extract features. We also propose the soft similarity contrast loss function for the first time, which ensures the optimization of similar images with higher similarity and different classes of images with greater differences while reducing the over-optimization of back-propagation leading to model overfitting. Specially, we propose a cumulative class prototype based on our network to solve the deviation problem of the mean class prototype and obtain a good class representation. Since new ancient characters can still be found in reality, our model has the ability to reject unknown categories while identifying new ones. A large number of experiments show that our proposed method has achieved high-efficiency discriminative performance and obtained the best performance over the methods of traditional deep learning and other classic one-shot learning.
古文字识别不仅对古代历史的研究和理解具有重要意义,而且对民族文化的传承和发展也具有深远的影响。为了降低古文字研究的难度专业知识,同时克服数据不足、类不平衡、字形多样化和开放集识别问题,我们提出了一种基于相似性学习方法的暹罗相似性网络,直接学习输入相似性,然后应用训练好的模型来建立用于识别的一次性分类任务。该网络提出了多尺度融合骨干结构和嵌入式结构,以提高模型的特征提取能力。我们还首次提出了软相似性对比损失函数,该函数在保证对相似图像进行更高相似度优化和不同类图像进行更大差异优化的同时,减少了反向传播的过度优化,从而避免了模型过拟合。特别是,我们提出了一种基于我们网络的累积类原型,以解决均值类原型的偏差问题,并获得良好的类表示。由于在现实中仍然可以发现新的古文字,因此我们的模型在识别新文字的同时还具有拒绝未知类别的能力。大量实验表明,我们提出的方法在高效区分性能方面取得了优异的成绩,超过了传统深度学习方法和其他经典一次性学习方法的性能。