Department of Biostatistics, Johns Hopkins Bloomberg School of Public Health, 615 N Wolfe St, Baltimore, MD 21205, USA.
Department of Computer Science, Johns Hopkins University, 3400 N Charles St, Baltimore, MD 21218, USA.
Biostatistics. 2023 Dec 15;25(1):188-202. doi: 10.1093/biostatistics/kxac035.
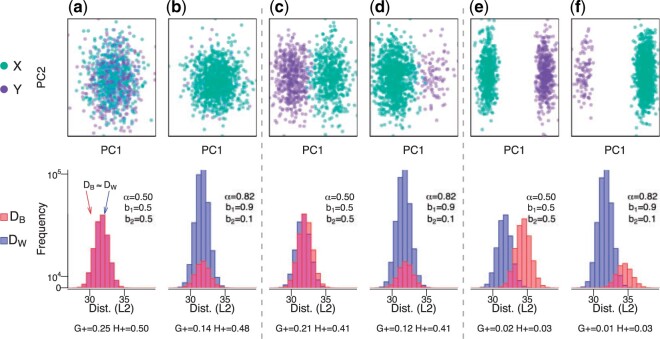
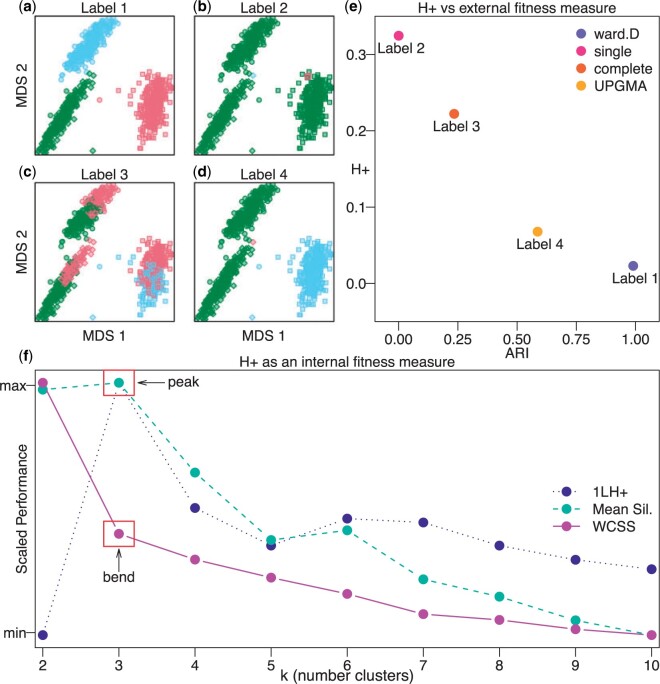
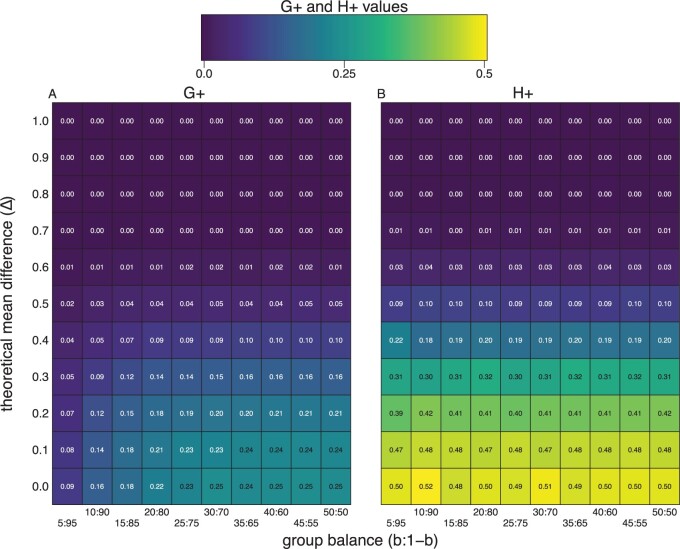
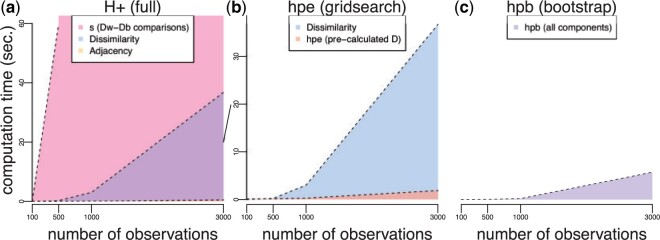
A standard unsupervised analysis is to cluster observations into discrete groups using a dissimilarity measure, such as Euclidean distance. If there does not exist a ground-truth label for each observation necessary for external validity metrics, then internal validity metrics, such as the tightness or separation of the clusters, are often used. However, the interpretation of these internal metrics can be problematic when using different dissimilarity measures as they have different magnitudes and ranges of values that they span. To address this problem, previous work introduced the "scale-agnostic" $G_{+}$ discordance metric; however, this internal metric is slow to calculate for large data. Furthermore, in the setting of unsupervised clustering with $k$ groups, we show that $G_{+}$ varies as a function of the proportion of observations assigned to each of the groups (or clusters), referred to as the group balance, which is an undesirable property. To address this problem, we propose a modification of $G_{+}$, referred to as $H_{+}$, and demonstrate that $H_{+}$ does not vary as a function of group balance using a simulation study and with public single-cell RNA-sequencing data. Finally, we provide scalable approaches to estimate $H_{+}$, which are available in the $\mathtt{fasthplus}$ R package.
一种标准的无监督分析方法是使用一种不相似性度量(如欧几里得距离)将观测值聚类到离散的组中。如果对于每个观测值都不存在用于外部有效性度量的ground-truth 标签,那么通常使用内部有效性度量,如聚类的紧密度或分离度。然而,当使用不同的不相似性度量时,这些内部度量的解释可能会出现问题,因为它们具有不同的量级和取值范围。为了解决这个问题,之前的工作引入了“与尺度无关的”$G_{+}$不和谐度量;然而,这个内部度量对于大数据集来说计算速度较慢。此外,在具有$k$个组的无监督聚类设置中,我们表明$G_{+}$随观测值分配到每个组(或聚类)的比例(即组平衡)而变化,这是一个不理想的特性。为了解决这个问题,我们提出了对$G_{+}$的修改,称为$H_{+}$,并通过模拟研究和公共单细胞 RNA 测序数据证明了$H_{+}$不随组平衡而变化。最后,我们提供了可扩展的方法来估计$H_{+}$,这些方法可在$\mathtt{fasthplus}$R 包中使用。