The Ohio State University College of Medicine, 370 W 9th Ave, Columbus, OH 43210, USA.
Department of Biomedical Informatics, The Ohio State University, 1800 Cannon Dr, Columbus, OH 43210, USA.
J Biomed Inform. 2021 Jun;118:103788. doi: 10.1016/j.jbi.2021.103788. Epub 2021 Apr 20.
Clustering analyses in clinical contexts hold promise to improve the understanding of patient phenotype and disease course in chronic and acute clinical medicine. However, work remains to ensure that solutions are rigorous, valid, and reproducible. In this paper, we evaluate best practices for dissimilarity matrix calculation and clustering on mixed-type, clinical data.
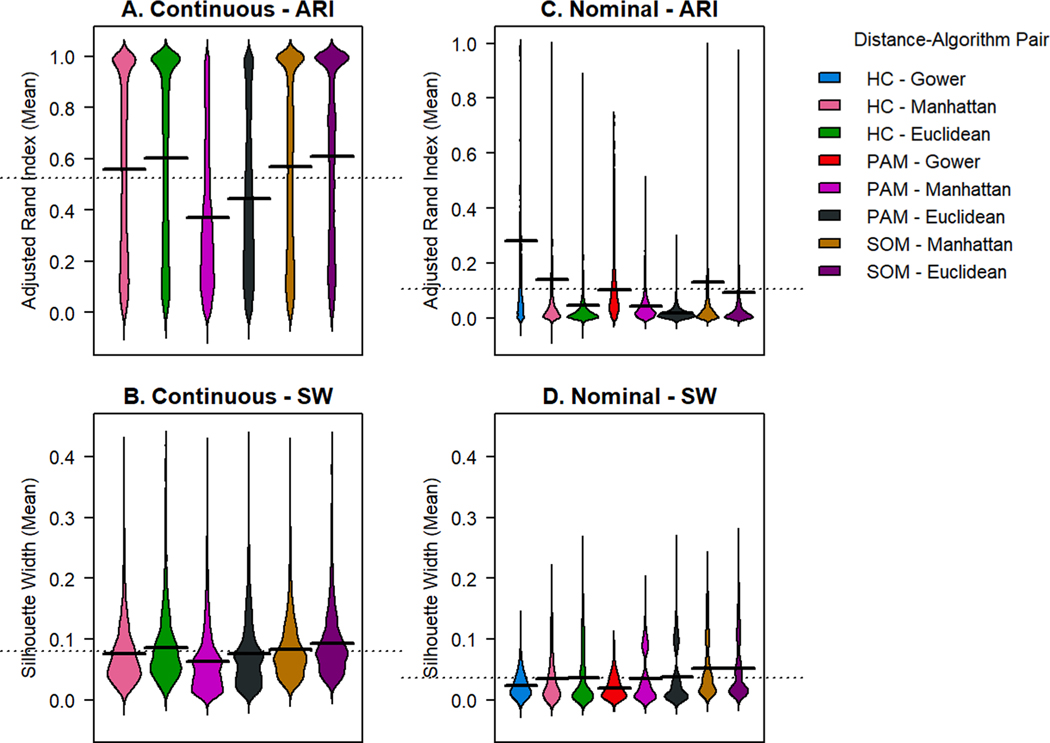
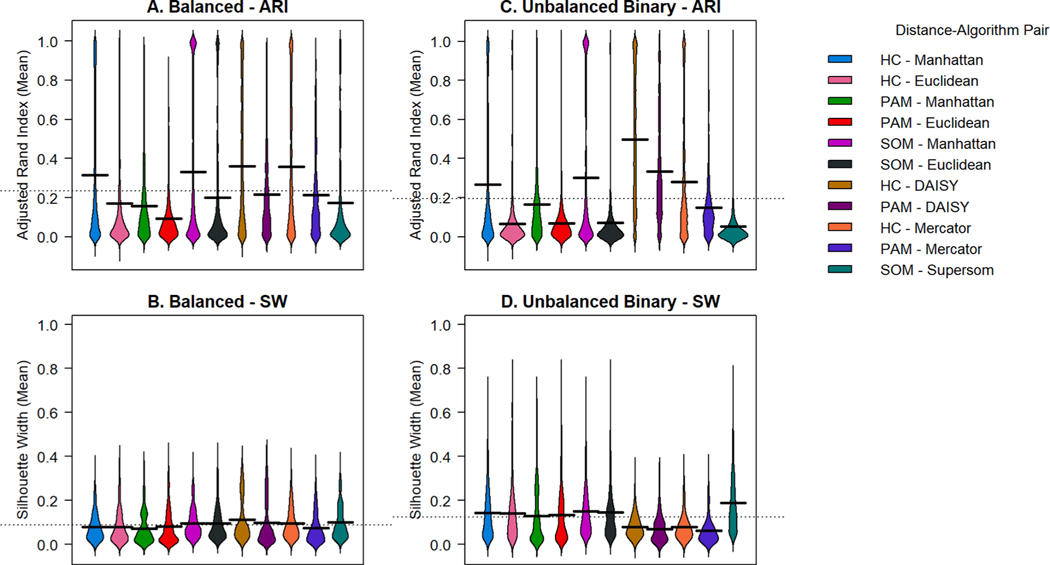
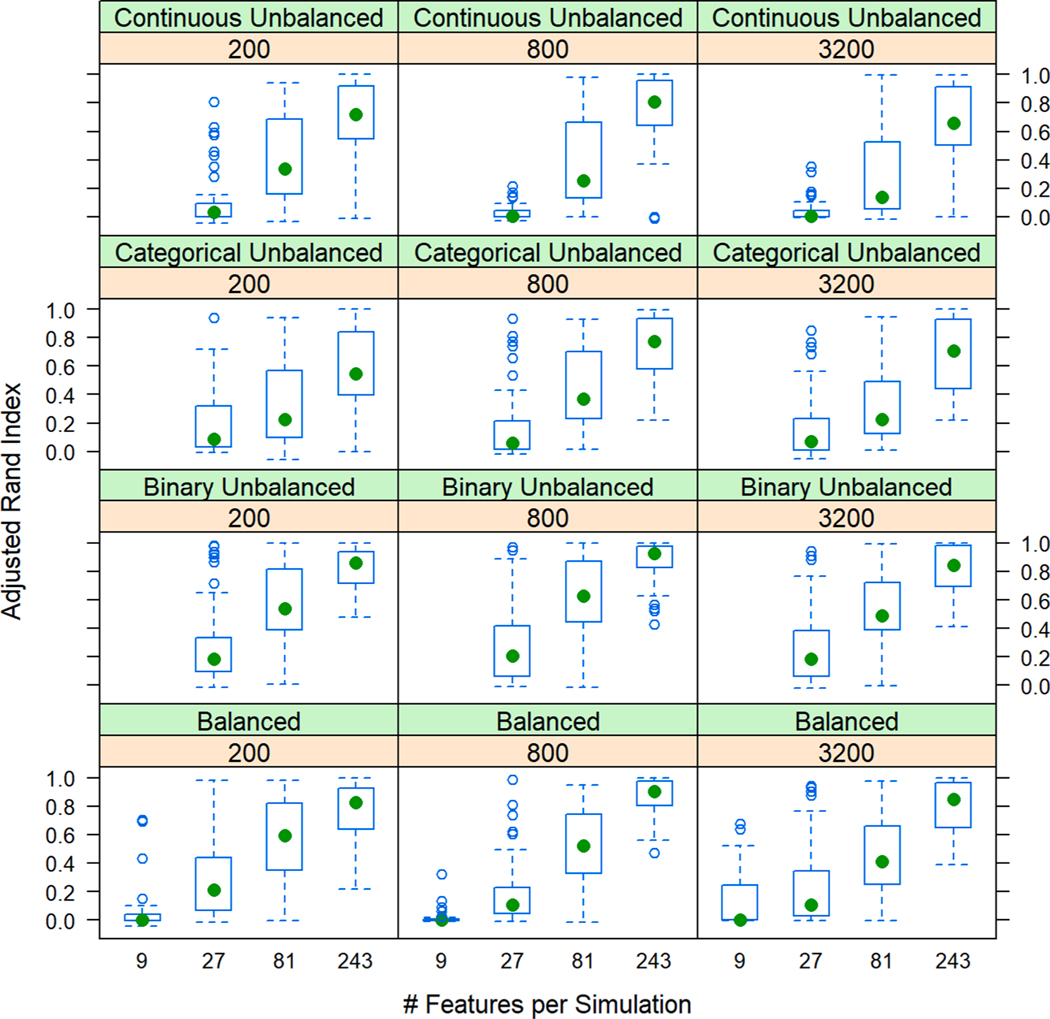
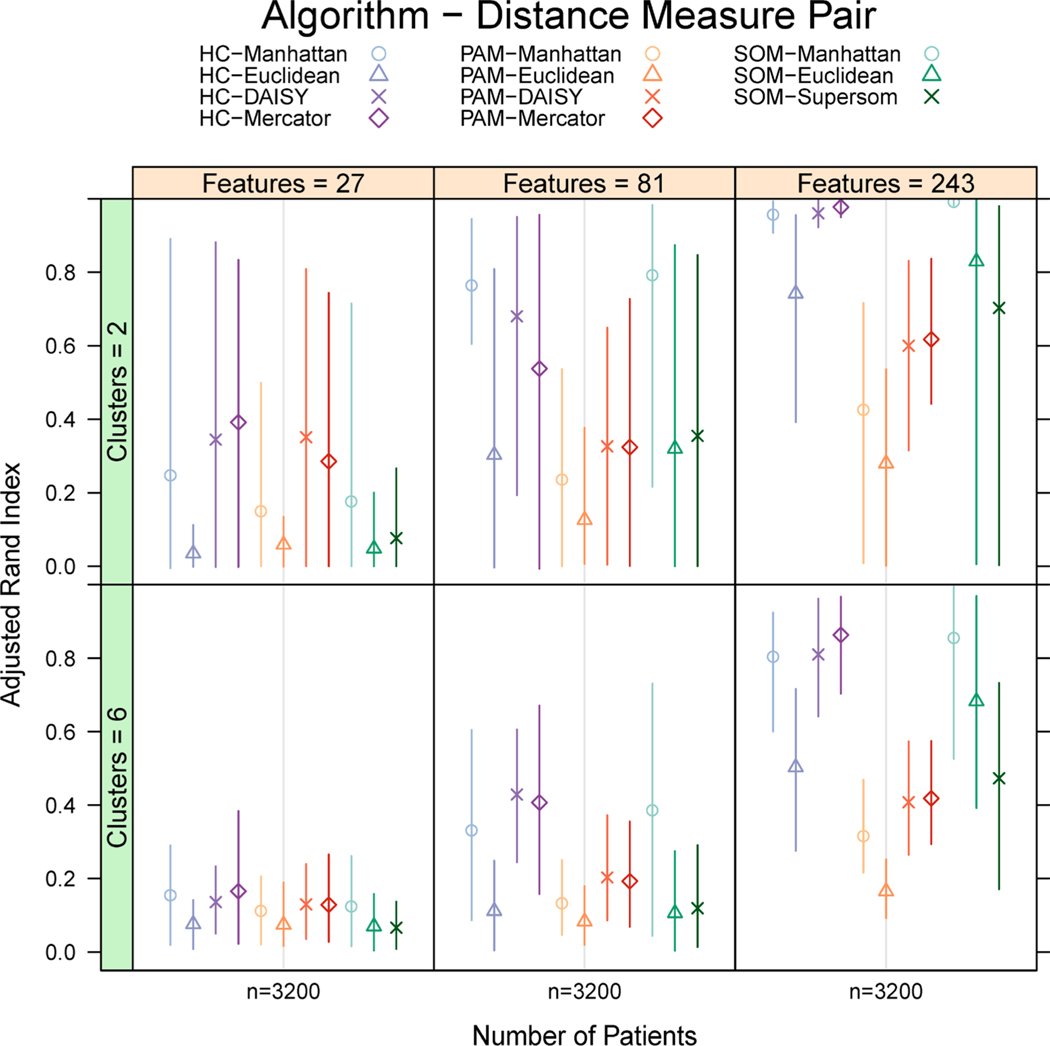
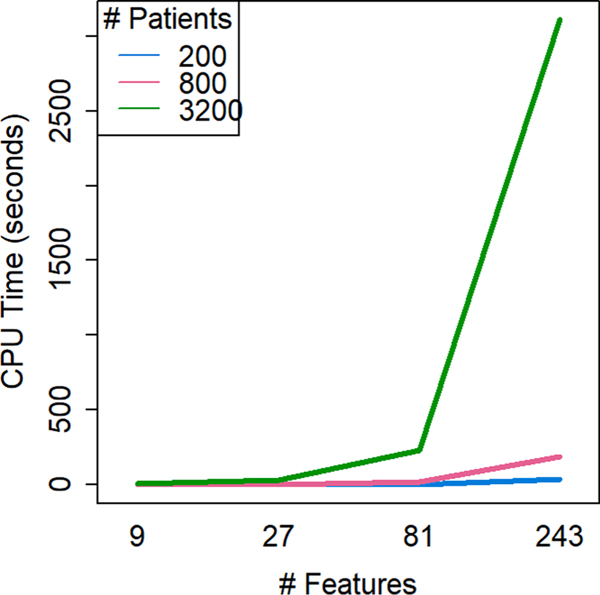
We simulate clinical data to represent problems in clinical trials, cohort studies, and EHR data, including single-type datasets (binary, continuous, categorical) and 4 data mixtures. We test 5 single distance metrics (Jaccard, Hamming, Gower, Manhattan, Euclidean) and 3 mixed distance metrics (DAISY, Supersom, and Mercator) with 3 clustering algorithms (hierarchical (HC), k-medoids, self-organizing maps (SOM)). We quantitatively and visually validate by Adjusted Rand Index (ARI) and silhouette width (SW). We applied our best methods to two real-world data sets: (1) 21 features collected on 247 patients with chronic lymphocytic leukemia, and (2) 40 features collected on 6000 patients admitted to an intensive care unit.
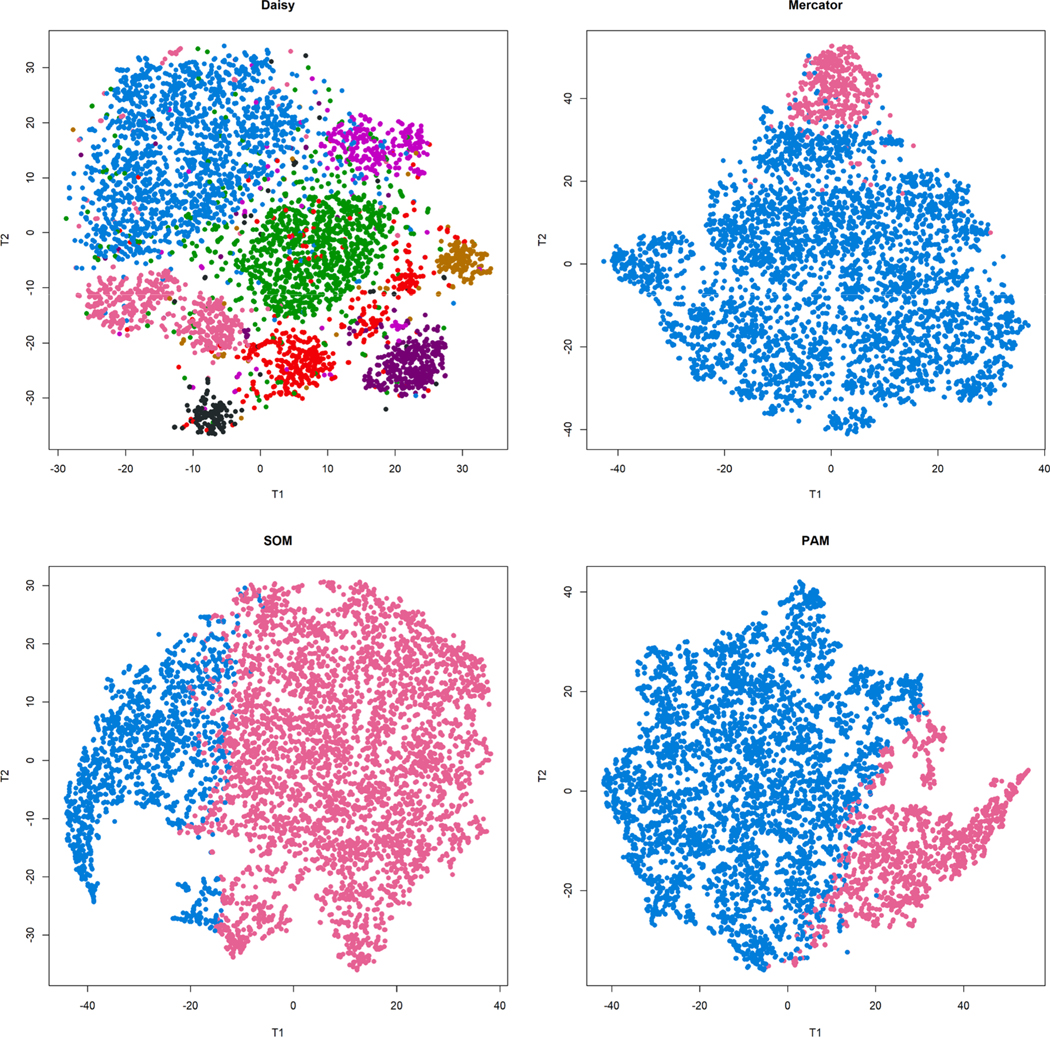
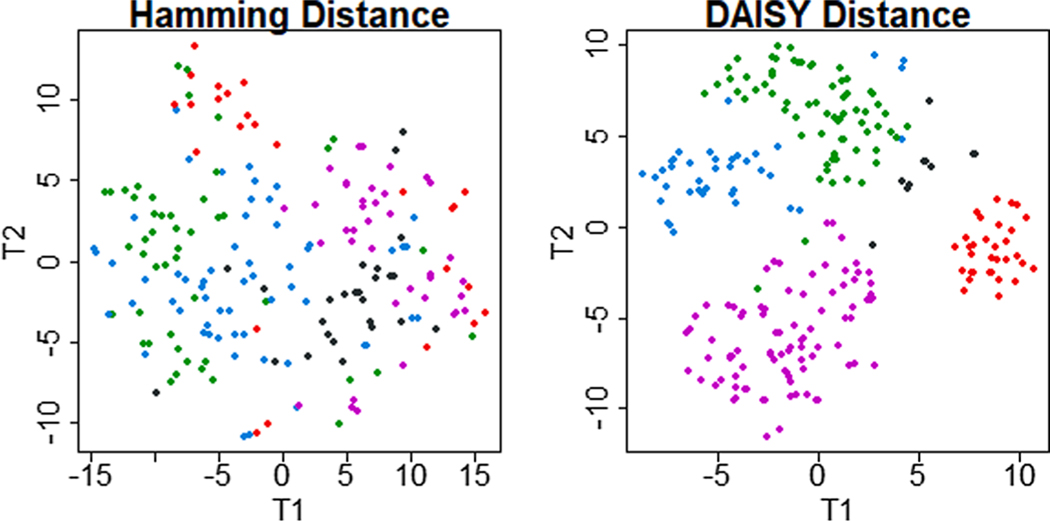
HC outperformed k-medoids and SOM by ARI across data types. DAISY produced the highest mean ARI for mixed data types for all mixtures except unbalanced mixtures dominated by continuous data. Compared to other methods, DAISY with HC uncovered superior, separable clusters in both real-world data sets.
Selecting an appropriate mixed-type metric allows the investigator to obtain optimal separation of patient clusters and get maximum use of their data. Superior metrics for mixed-type data handle multiple data types using multiple, type-focused distances. Better subclassification of disease opens avenues for targeted treatments, precision medicine, clinical decision support, and improved patient outcomes.
在临床环境中进行聚类分析有望改善对慢性和急性临床医学中患者表型和疾病过程的理解。然而,仍需要努力确保解决方案具有严格性、有效性和可重复性。在本文中,我们评估了针对混合类型临床数据的相似性矩阵计算和聚类的最佳实践。
我们模拟临床数据以代表临床试验、队列研究和电子健康记录 (EHR) 数据中的问题,包括单类型数据集(二进制、连续、分类)和 4 种数据混合物。我们测试了 5 种单一距离度量(Jaccard、Hamming、Gower、曼哈顿、欧几里得)和 3 种混合距离度量(DAISY、Supersom 和 Mercator)与 3 种聚类算法(层次聚类 (HC)、k-均值聚类、自组织映射 (SOM))。我们通过调整兰德指数 (ARI) 和轮廓宽度 (SW) 进行定量和可视化验证。我们将最佳方法应用于两个真实世界数据集:(1)在 247 名慢性淋巴细胞白血病患者中收集的 21 个特征,以及(2)在 6000 名入住重症监护病房的患者中收集的 40 个特征。
HC 在所有数据类型上的 ARI 均优于 k-均值聚类和 SOM。对于除连续数据为主的不平衡混合物外的所有混合物,DAISY 产生的混合数据类型的平均 ARI 最高。与其他方法相比,DAISY 与 HC 一起在两个真实世界的数据集均能发现更优、可分离的聚类。
选择适当的混合类型度量可以使研究人员获得患者聚类的最佳分离效果,并最大程度地利用其数据。用于混合类型数据的优越度量使用多种、针对类型的距离来处理多种数据类型。更好的疾病细分可以为靶向治疗、精准医学、临床决策支持和改善患者预后开辟途径。