Division of Biomedical Informatics, Seoul National University Biomedical Informatics (SNUBI), Seoul National University College of Medicine, Seoul 110799, Korea.
Department of Otolaryngology, Thyroid/Head & Neck Cancer Center, The Dongnam Institute of Radiological & Medical Sciences (DIRAMS), Busan 46033, Korea.
Sensors (Basel). 2022 Aug 24;22(17):6387. doi: 10.3390/s22176387.
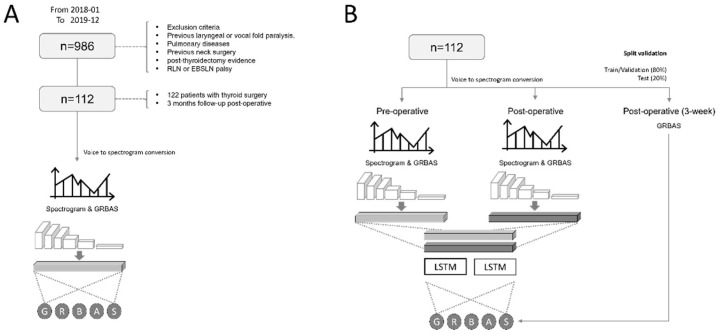
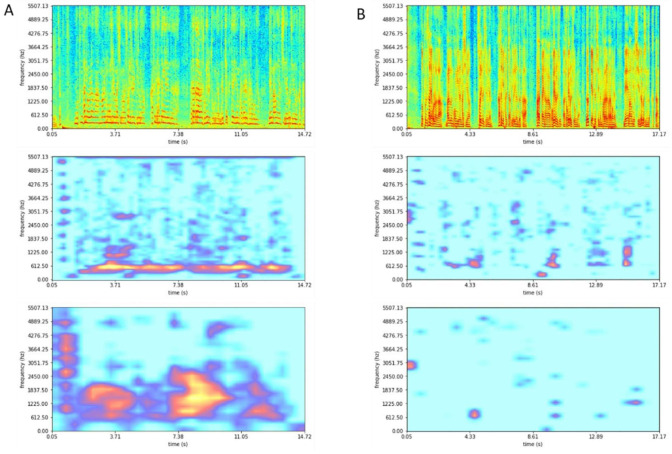
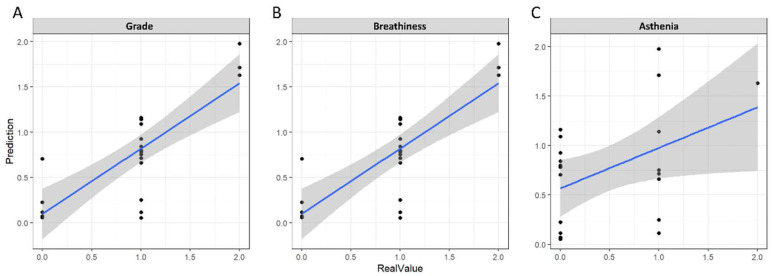
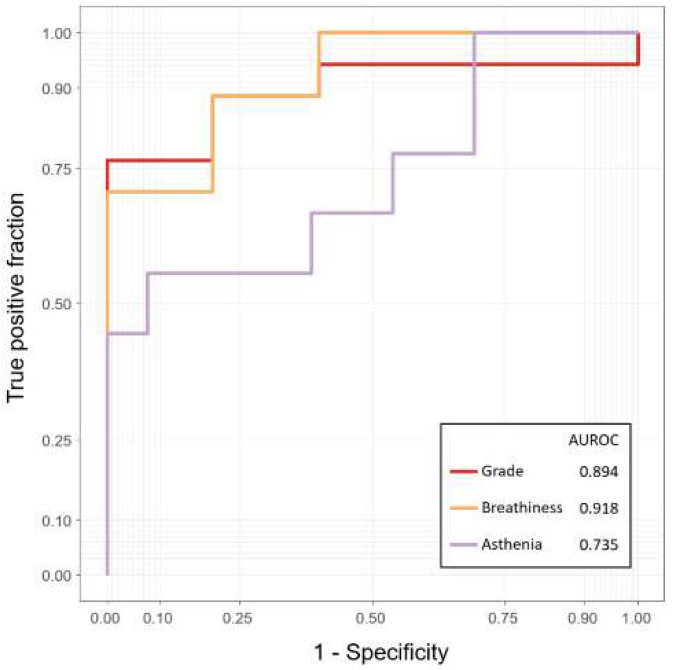
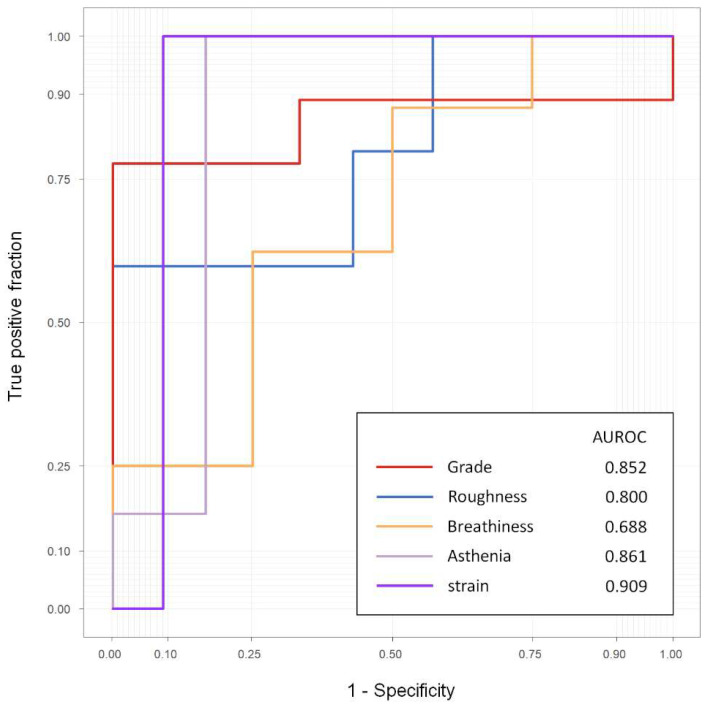
Despite the lack of findings in laryngeal endoscopy, it is common for patients to undergo vocal problems after thyroid surgery. This study aimed to predict the recovery of the patient's voice after 3 months from preoperative and postoperative voice spectrograms. We retrospectively collected voice and the GRBAS score from 114 patients undergoing surgery with thyroid cancer. The data for each patient were taken from three points in time: preoperative, and 2 weeks and 3 months postoperative. Using the pretrained model to predict GRBAS as the backbone, the preoperative and 2-weeks-postoperative voice spectrogram were trained for the EfficientNet architecture deep-learning model with long short-term memory (LSTM) to predict the voice at 3 months postoperation. The correlation analysis of the predicted results for the grade, breathiness, and asthenia scores were 0.741, 0.766, and 0.433, respectively. Based on the scaled prediction results, the area under the receiver operating characteristic curve for the binarized grade, breathiness, and asthenia were 0.894, 0.918, and 0.735, respectively. In the follow-up test results for 12 patients after 6 months, the average of the AUC values for the five scores was 0.822. This study showed the feasibility of predicting vocal recovery after 3 months using the spectrogram. We expect this model could be used to relieve patients' psychological anxiety and encourage them to actively participate in speech rehabilitation.
尽管喉镜检查未发现异常,但甲状腺手术后患者常出现嗓音问题。本研究旨在通过术前和术后嗓音频谱图预测患者术后 3 个月的嗓音恢复情况。我们回顾性地收集了 114 例甲状腺癌手术患者的嗓音和 GRBAS 评分数据。每位患者的数据均来自三个时间点:术前、术后 2 周和术后 3 个月。使用预先训练的模型预测 GRBAS 作为骨干,将术前和术后 2 周的嗓音频谱图输入到具有长短期记忆(LSTM)的 EfficientNet 架构深度学习模型中,以预测术后 3 个月的嗓音。预测等级、粗糙声和无力声得分的相关性分析分别为 0.741、0.766 和 0.433。基于比例预测结果,二进制等级、粗糙声和无力声的受试者工作特征曲线下面积分别为 0.894、0.918 和 0.735。在 12 例患者术后 6 个月的随访测试结果中,五个评分的 AUC 值平均值为 0.822。本研究表明,使用频谱图预测术后 3 个月的嗓音恢复情况是可行的。我们期望该模型能够用于减轻患者的心理焦虑,并鼓励他们积极参与言语康复。