Strain Surveillance and Emerging Variant Team, Centers for Disease Control and Prevention, Atlanta, GA, United States of America.
Broad Institute of MIT and Harvard, Cambridge, MA, United States of America.
PeerJ. 2022 Sep 5;10:e13821. doi: 10.7717/peerj.13821. eCollection 2022.
Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the cause of coronavirus disease 2019 (COVID-19), has spread globally and is being surveilled with an international genome sequencing effort. Surveillance consists of sample acquisition, library preparation, and whole genome sequencing. This has necessitated a classification scheme detailing Variants of Concern (VOC) and Variants of Interest (VOI), and the rapid expansion of bioinformatics tools for sequence analysis. These bioinformatic tools are means for major actionable results: maintaining quality assurance and checks, defining population structure, performing genomic epidemiology, and inferring lineage to allow reliable and actionable identification and classification. Additionally, the pandemic has required public health laboratories to reach high throughput proficiency in sequencing library preparation and downstream data analysis rapidly. However, both processes can be limited by a lack of a standardized sequence dataset.
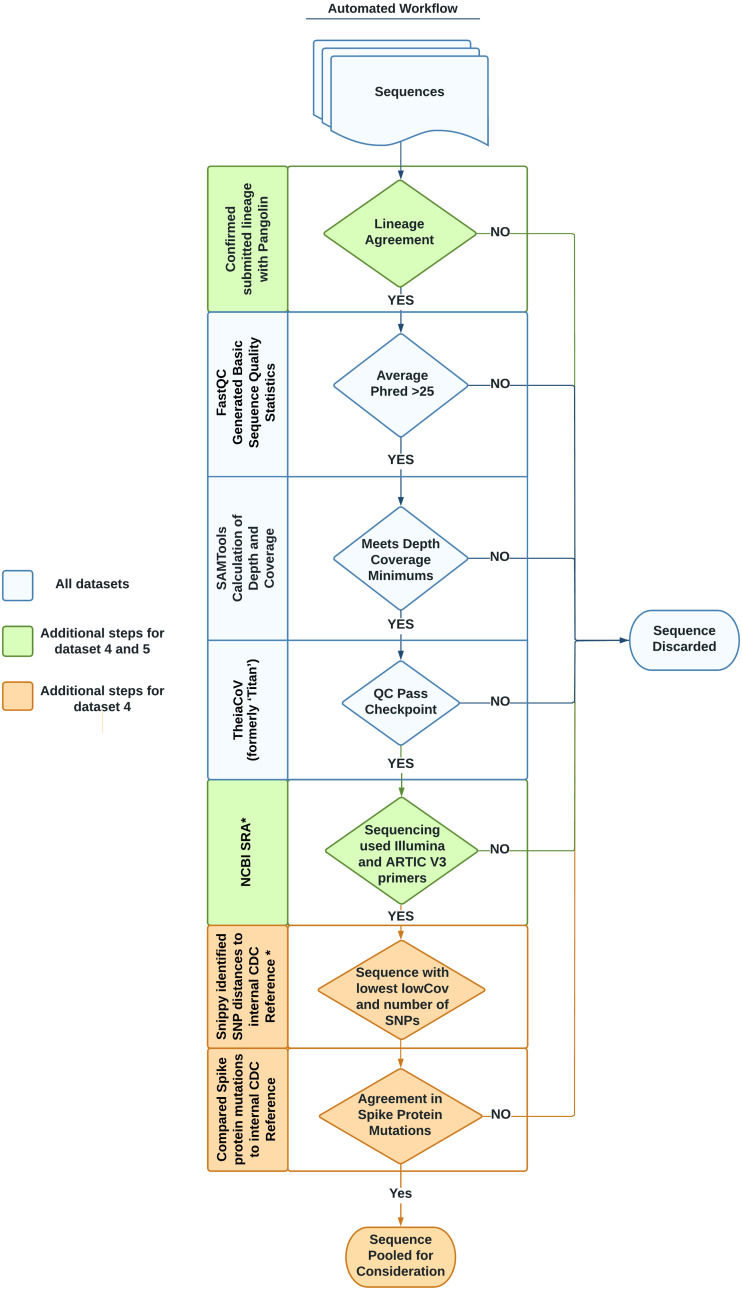
We identified six SARS-CoV-2 sequence datasets from recent publications, public databases and internal resources. In addition, we created a method to mine public databases to identify representative genomes for these datasets. Using this novel method, we identified several genomes as either VOI/VOC representatives or non-VOI/VOC representatives. To describe each dataset, we utilized a previously published datasets format, which describes accession information and whole dataset information. Additionally, a script from the same publication has been enhanced to download and verify all data from this study.
The benchmark datasets focus on the two most widely used sequencing platforms: long read sequencing data from the Oxford Nanopore Technologies platform and short read sequencing data from the Illumina platform. There are six datasets: three were derived from recent publications; two were derived from data mining public databases to answer common questions not covered by published datasets; one unique dataset representing common sequence failures was obtained by rigorously scrutinizing data that did not pass quality checks. The dataset summary table, data mining script and quality control (QC) values for all sequence data are publicly available on GitHub: https://github.com/CDCgov/datasets-sars-cov-2.
The datasets presented here were generated to help public health laboratories build sequencing and bioinformatics capacity, benchmark different workflows and pipelines, and calibrate QC thresholds to ensure sequencing quality. Together, improvements in these areas support accurate and timely outbreak investigation and surveillance, providing actionable data for pandemic management. Furthermore, these publicly available and standardized benchmark data will facilitate the development and adjudication of new pipelines.
严重急性呼吸系统综合症冠状病毒 2(SARS-CoV-2)是导致 2019 年冠状病毒病(COVID-19)的病原体,其已在全球范围内传播,并通过国际基因组测序工作进行监测。监测包括样本采集、文库制备和全基因组测序。这就需要制定详细的关注变异株(VOC)和感兴趣变异株(VOI)分类方案,并快速扩展用于序列分析的生物信息学工具。这些生物信息学工具是得出主要结果的手段:维持质量保证和检查、定义种群结构、进行基因组流行病学研究,并推断谱系,以实现可靠和可操作的识别和分类。此外,大流行要求公共卫生实验室迅速达到测序文库制备和下游数据分析的高通量水平。然而,这两个过程都可能因缺乏标准化的序列数据集而受到限制。
我们从最近的出版物、公共数据库和内部资源中确定了六个 SARS-CoV-2 序列数据集。此外,我们还创建了一种从公共数据库中挖掘代表基因组的方法,用于这些数据集。使用这种新方法,我们确定了一些基因组作为 VOI/VOC 代表或非 VOI/VOC 代表。为了描述每个数据集,我们使用了之前发表的数据集格式,该格式描述了访问信息和整个数据集信息。此外,还增强了同一出版物中的一个脚本,以从本研究中下载并验证所有数据。
基准数据集侧重于两个最常用的测序平台:来自牛津纳米孔技术平台的长读测序数据和来自 Illumina 平台的短读测序数据。有六个数据集:三个来自最近的出版物;两个来自于挖掘公共数据库以回答未涵盖在已发表数据集中的常见问题;一个独特的数据集代表了常见的序列失败,是通过严格审查未通过质量检查的数据获得的。数据集汇总表、数据挖掘脚本和所有序列数据的质量控制(QC)值都可在 GitHub 上公开获取:https://github.com/CDCgov/datasets-sars-cov-2。
这里呈现的数据集旨在帮助公共卫生实验室建立测序和生物信息学能力,基准不同的工作流程和管道,并校准 QC 阈值以确保测序质量。这些领域的改进共同支持准确和及时的暴发调查和监测,为大流行管理提供可操作的数据。此外,这些公开可用且标准化的基准数据将促进新管道的开发和裁决。