Laboratoire de Physique de l'Ecole Normale Supérieure, PSL & CNRS UMR8063, Sorbonne Université, Université de Paris, Paris, France.
School of Molecular Sciences and Center for Molecular Design and Biomimetics, The Biodesign Institute, Arizona State University, Tempe, Arizona, United States of America.
PLoS Comput Biol. 2022 Sep 29;18(9):e1010561. doi: 10.1371/journal.pcbi.1010561. eCollection 2022 Sep.
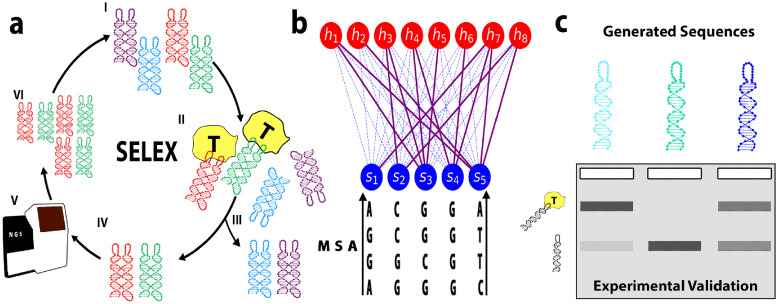
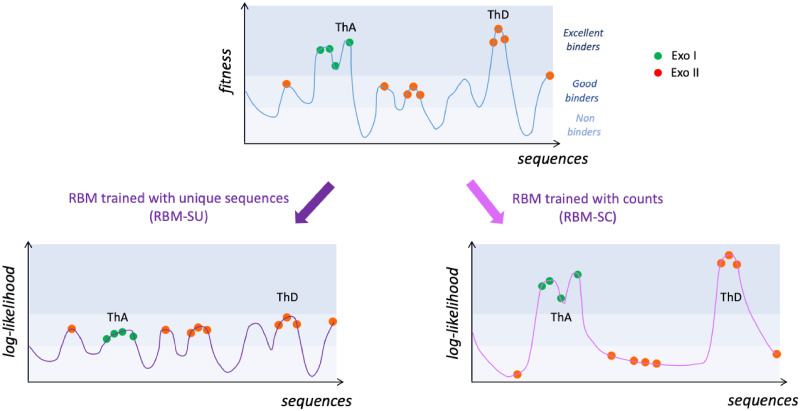
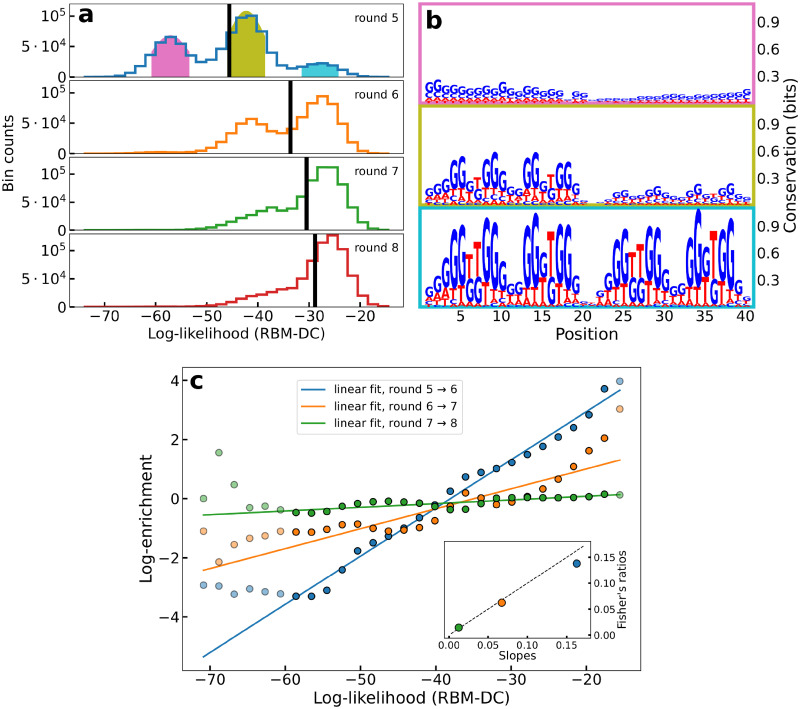
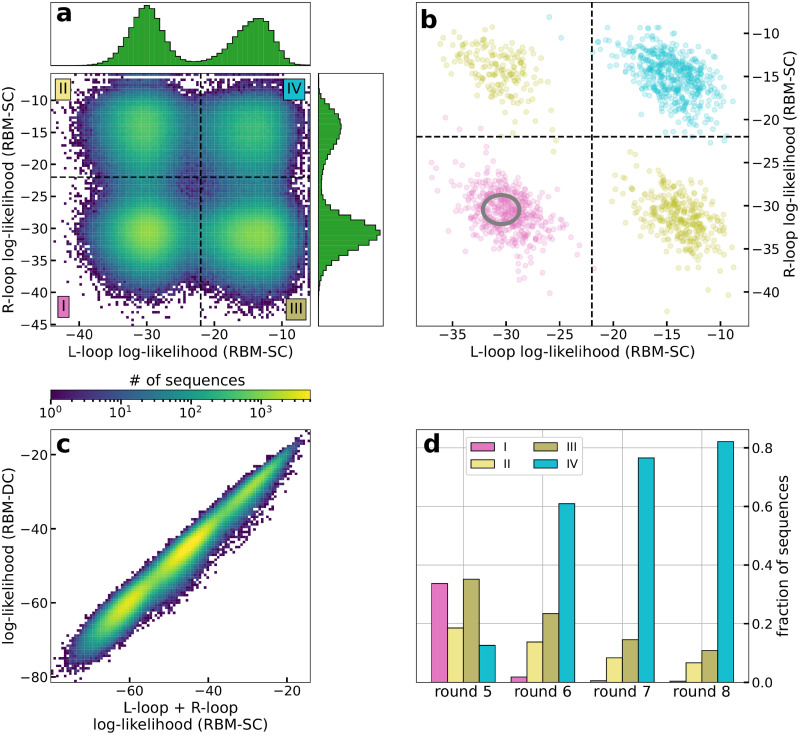
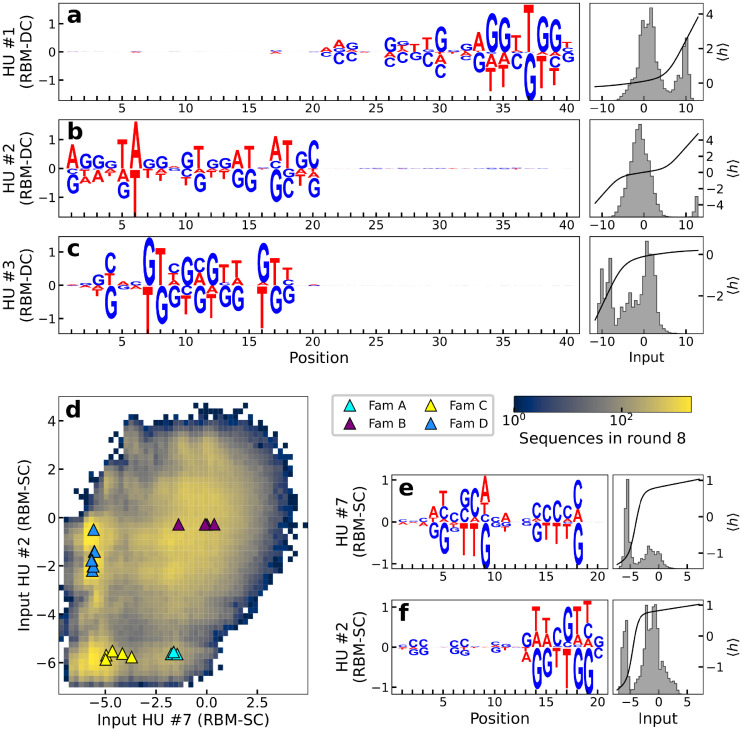
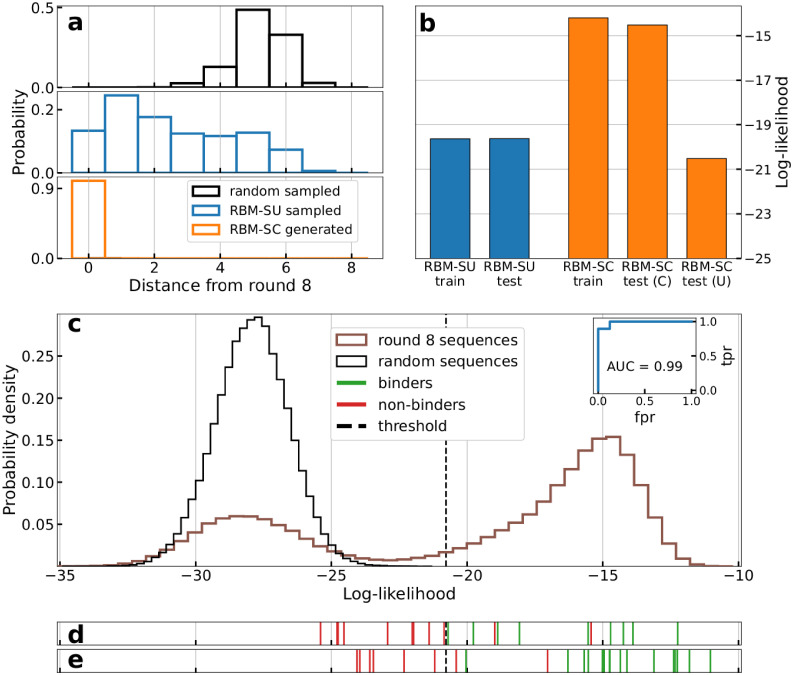
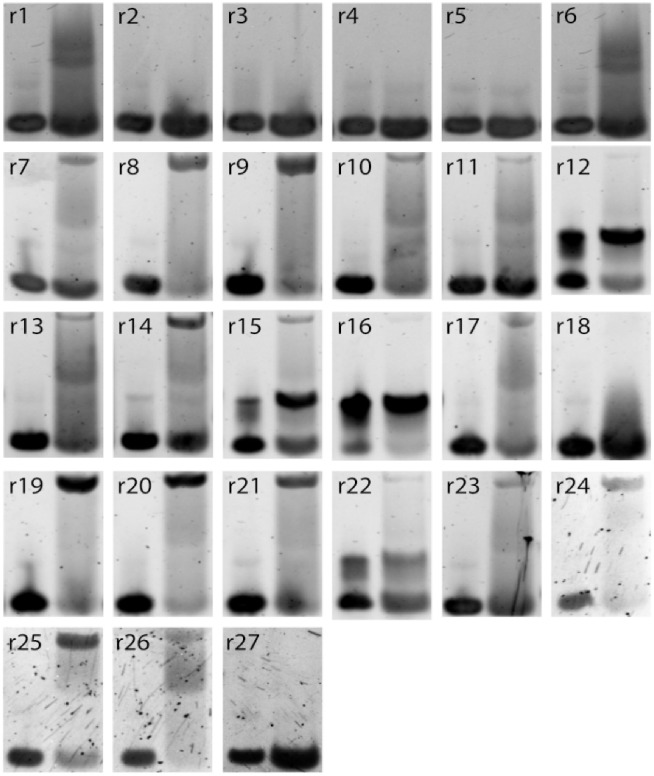
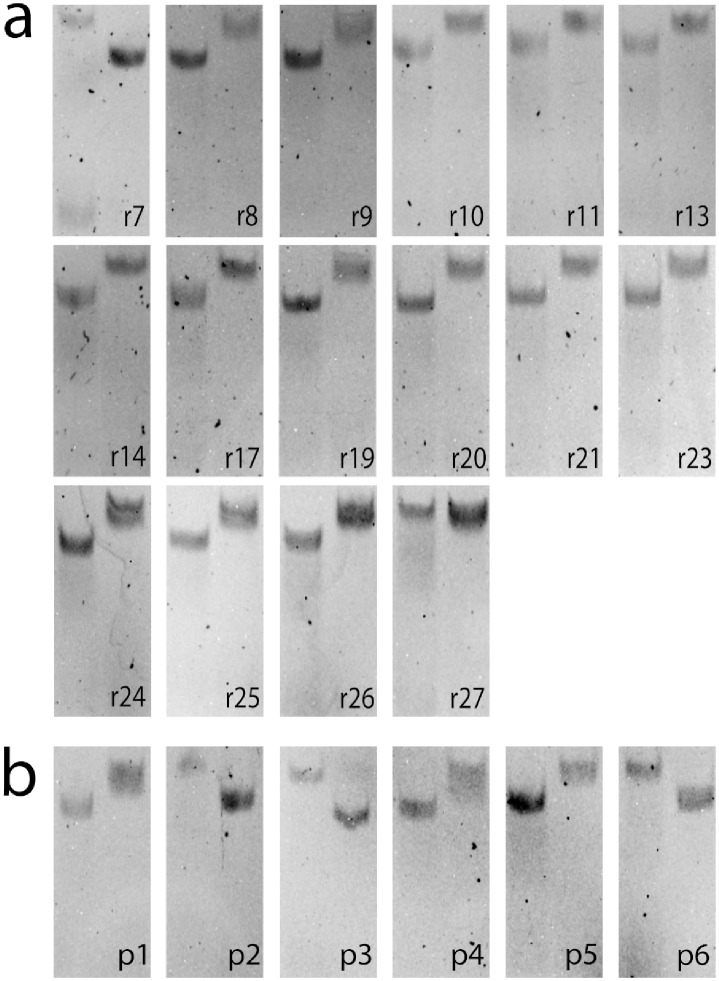
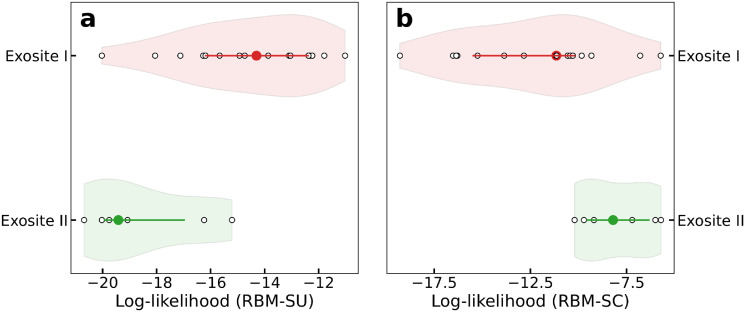
Selection protocols such as SELEX, where molecules are selected over multiple rounds for their ability to bind to a target of interest, are popular methods for obtaining binders for diagnostic and therapeutic purposes. We show that Restricted Boltzmann Machines (RBMs), an unsupervised two-layer neural network architecture, can successfully be trained on sequence ensembles from single rounds of SELEX experiments for thrombin aptamers. RBMs assign scores to sequences that can be directly related to their fitnesses estimated through experimental enrichment ratios. Hence, RBMs trained from sequence data at a given round can be used to predict the effects of selection at later rounds. Moreover, the parameters of the trained RBMs are interpretable and identify functional features contributing most to sequence fitness. To exploit the generative capabilities of RBMs, we introduce two different training protocols: one taking into account sequence counts, capable of identifying the few best binders, and another based on unique sequences only, generating more diverse binders. We then use RBMs model to generate novel aptamers with putative disruptive mutations or good binding properties, and validate the generated sequences with gel shift assay experiments. Finally, we compare the RBM's performance with different supervised learning approaches that include random forests and several deep neural network architectures.
选择方案,如 SELEX,其中分子在多个轮次中被选择,以评估它们与感兴趣的靶标的结合能力,是获得用于诊断和治疗目的的配体的流行方法。我们表明,受限玻尔兹曼机(RBM),一种无监督的两层神经网络架构,可以成功地对来自 SELEX 实验单轮的序列集合进行训练,以获得凝血酶适体。RBM 为序列分配分数,这些分数可以直接与其通过实验富集比估计的适应性相关。因此,从给定轮次的序列数据中训练的 RBM 可以用于预测后续轮次的选择效果。此外,训练后的 RBM 参数是可解释的,并确定对序列适应性贡献最大的功能特征。为了利用 RBM 的生成能力,我们引入了两种不同的训练方案:一种考虑序列计数,能够识别出少数最佳配体,另一种仅基于独特序列,生成更多样化的配体。然后,我们使用 RBM 模型生成具有潜在破坏性突变或良好结合特性的新适体,并通过凝胶迁移实验验证生成的序列。最后,我们将 RBM 的性能与包括随机森林和几种深度神经网络架构在内的不同监督学习方法进行了比较。