Data Science Unit, Instituto de Investigación Sanitaria Hospital Universitario 12 de Octubre, Madrid, Spain.
ETSI Telecomunicación, Universidad Politécnica de Madrid, Madrid, Spain.
Methods Inf Med. 2022 Dec;61(S 02):e89-e102. doi: 10.1055/s-0042-1757763. Epub 2022 Oct 11.
During the COVID-19 pandemic, several methodologies were designed for obtaining electronic health record (EHR)-derived datasets for research. These processes are often based on black boxes, on which clinical researchers are unaware of how the data were recorded, extracted, and transformed. In order to solve this, it is essential that extract, transform, and load (ETL) processes are based on transparent, homogeneous, and formal methodologies, making them understandable, reproducible, and auditable.
This study aims to design and implement a methodology, according with FAIR Principles, for building ETL processes (focused on data extraction, selection, and transformation) for EHR reuse in a transparent and flexible manner, applicable to any clinical condition and health care organization.
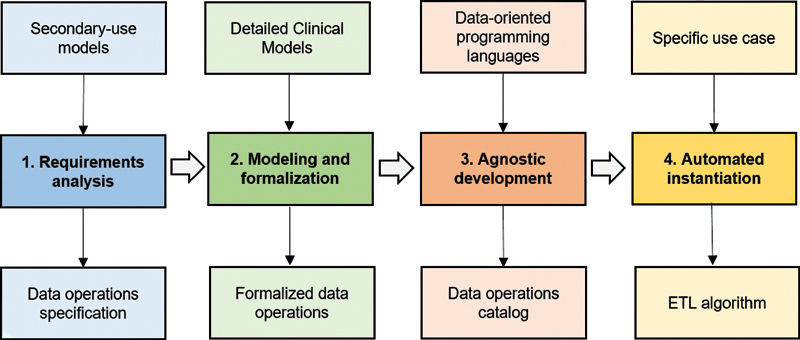
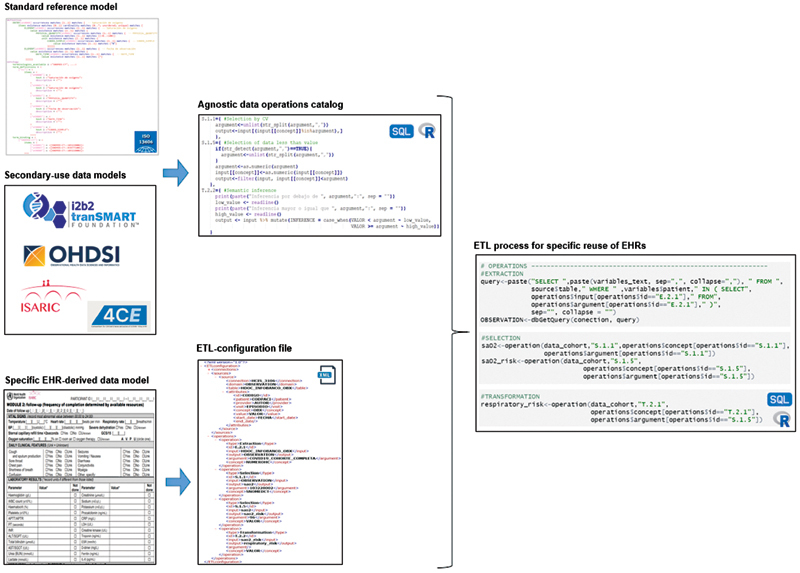
The proposed methodology comprises four stages: (1) analysis of secondary use models and identification of data operations, based on internationally used clinical repositories, case report forms, and aggregated datasets; (2) modeling and formalization of data operations, through the paradigm of the Detailed Clinical Models; (3) agnostic development of data operations, selecting SQL and R as programming languages; and (4) automation of the ETL instantiation, building a formal configuration file with XML.
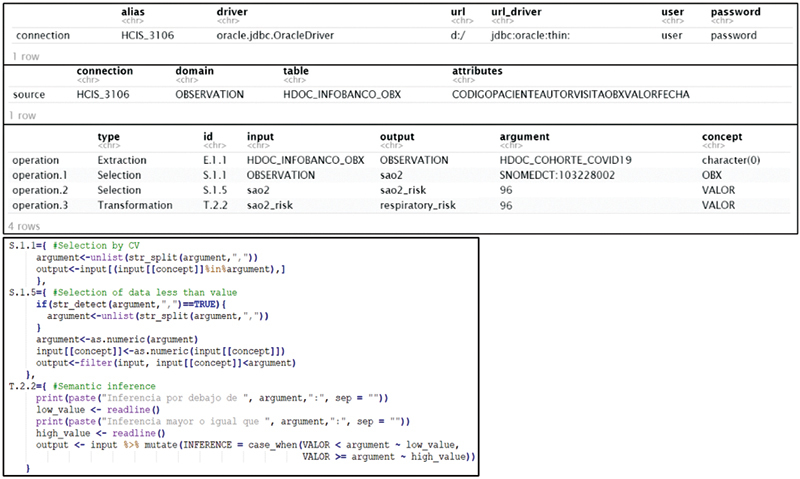
First, four international projects were analyzed to identify 17 operations, necessary to obtain datasets according to the specifications of these projects from the EHR. With this, each of the data operations was formalized, using the ISO 13606 reference model, specifying the valid data types as arguments, inputs and outputs, and their cardinality. Then, an agnostic catalog of data was developed through data-oriented programming languages previously selected. Finally, an automated ETL instantiation process was built from an ETL configuration file formally defined.
This study has provided a transparent and flexible solution to the difficulty of making the processes for obtaining EHR-derived data for secondary use understandable, auditable, and reproducible. Moreover, the abstraction carried out in this study means that any previous EHR reuse methodology can incorporate these results into them.
在 COVID-19 大流行期间,设计了几种方法来获取用于研究的电子健康记录 (EHR) 衍生数据集。这些过程通常基于黑盒,临床研究人员不知道数据是如何记录、提取和转换的。为了解决这个问题,至关重要的是提取、转换和加载 (ETL) 过程基于透明、同质和正式的方法,使其具有可理解性、可重复性和可审核性。
本研究旨在设计并实施一种符合 FAIR 原则的方法,以透明且灵活的方式构建 EHR 再利用的 ETL 流程(侧重于数据提取、选择和转换),适用于任何临床情况和医疗保健组织。
所提出的方法包括四个阶段:(1) 分析二次使用模型并根据国际上使用的临床知识库、病例报告表和聚合数据集识别数据操作;(2) 通过详细临床模型范例对数据操作进行建模和形式化;(3) 选择 SQL 和 R 作为编程语言进行数据操作的无偏见开发;以及 (4) 通过使用 XML 构建正式配置文件来实现 ETL 实例化的自动化。
首先,分析了四个国际项目,以确定根据这些项目从 EHR 中获取数据集所需的 17 个操作。通过这种方式,使用 ISO 13606 参考模型对每个数据操作进行了形式化,指定了有效的数据类型作为参数、输入和输出及其基数。然后,通过先前选择的数据导向编程语言开发了一个无偏数据目录。最后,从正式定义的 ETL 配置文件构建了自动化 ETL 实例化过程。
本研究为使二次使用 EHR 衍生数据的过程变得易于理解、审核和可重复提供了一种透明且灵活的解决方案。此外,本研究中的抽象意味着任何先前的 EHR 重用方法都可以将这些结果纳入其中。