Research Fellow, Department of Statistics, University of Warwick, Coventry, CV4 7AL, UK.
Research Fellow, Institute of Applied Health Research, University of Birmingham, B15 2TT, UK.
J Clin Epidemiol. 2022 Dec;152:164-175. doi: 10.1016/j.jclinepi.2022.10.011. Epub 2022 Oct 11.
To investigate the reproducibility and validity of latent class analysis (LCA) and hierarchical cluster analysis (HCA), multiple correspondence analysis followed by k-means (MCA-kmeans) and k-means (kmeans) for multimorbidity clustering.
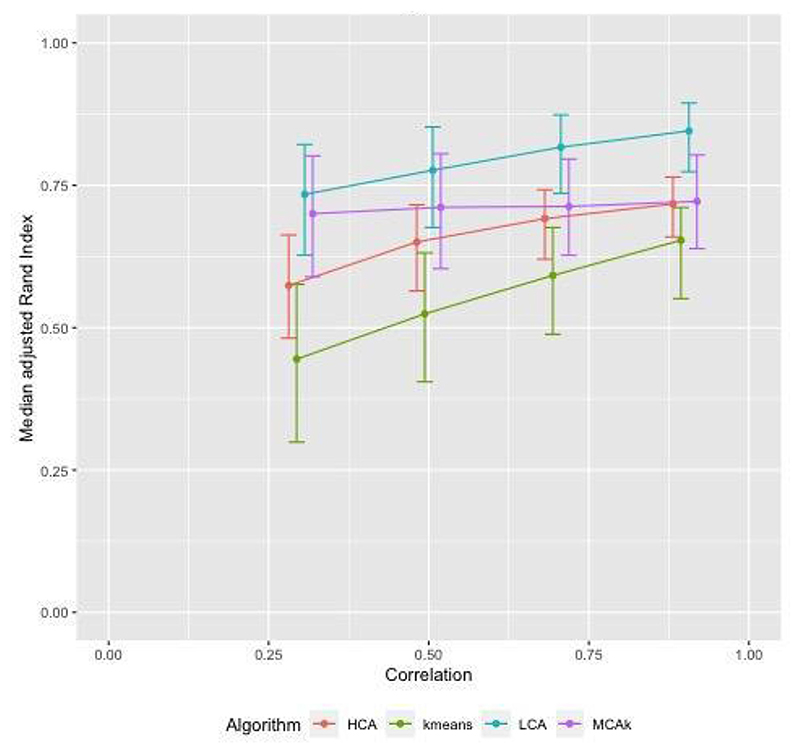
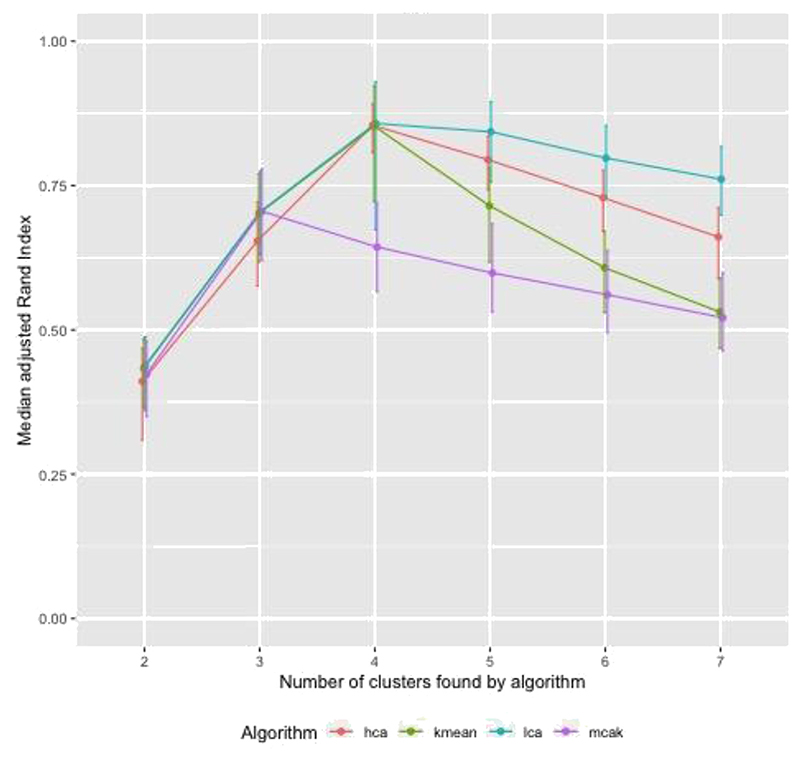
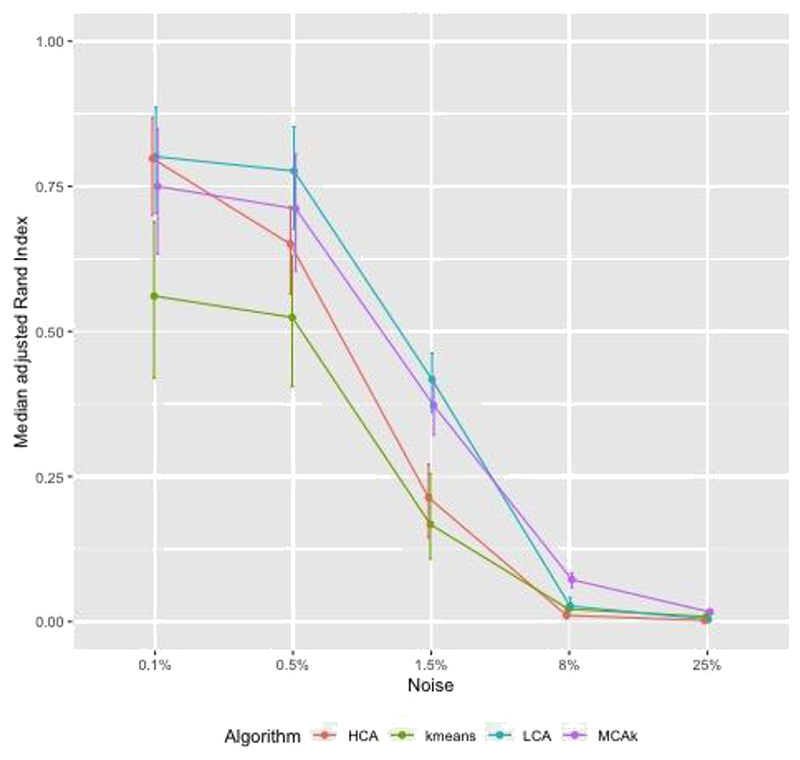
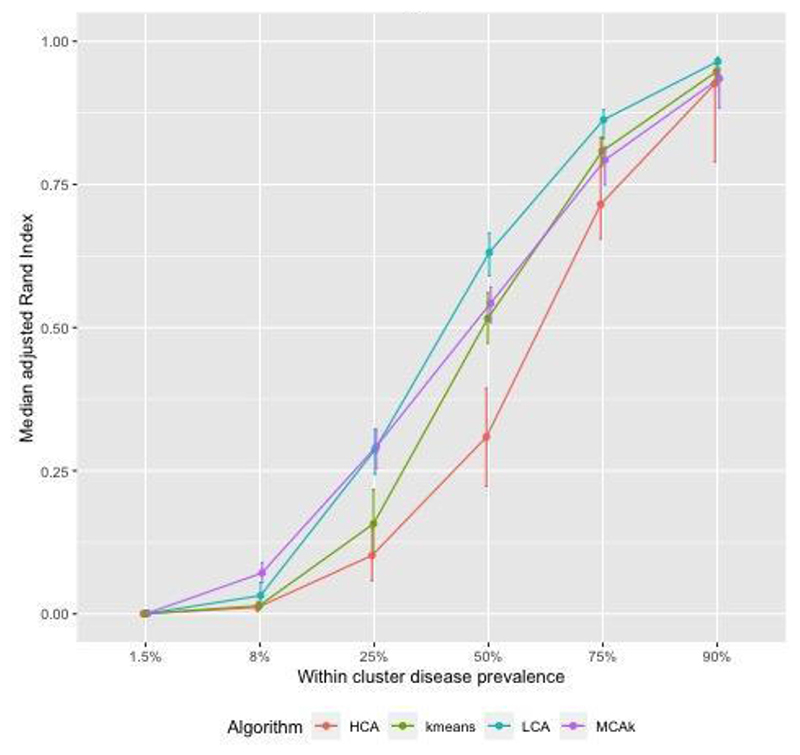
We first investigated clustering algorithms in simulated datasets with 26 diseases of varying prevalence in predetermined clusters, comparing the derived clusters to known clusters using the adjusted Rand Index (aRI). We then them investigated the medical records of male patients, aged 65 to 84 years from 50 UK general practices, with 49 long-term health conditions. We compared within cluster morbidity profiles using the Pearson correlation coefficient and assessed cluster stability using in 400 bootstrap samples.
In the simulated datasets, the closest agreement (largest aRI) to known clusters was with LCA and then MCA-kmeans algorithms. In the medical records dataset, all four algorithms identified one cluster of 20-25% of the dataset with about 82% of the same patients across all four algorithms. LCA and MCA-kmeans both found a second cluster of 7% of the dataset. Other clusters were found by only one algorithm. LCA and MCA-kmeans clustering gave the most similar partitioning (aRI 0.54).
LCA achieved higher aRI than other clustering algorithms.
本研究旨在探究潜在类别分析(LCA)和层次聚类分析(HCA)、多重对应分析后 K 均值(MCA-kmeans)和 K 均值(kmeans)在多病态聚类中的可重复性和有效性。
我们首先在模拟数据集上调查聚类算法,该数据集包含 26 种不同流行程度的疾病,通过调整 Rand 指数(aRI)将得出的聚类与已知聚类进行比较。然后,我们研究了来自 50 家英国普通诊所的 65 至 84 岁男性患者的病历,这些患者有 49 种长期健康状况。我们使用 Pearson 相关系数比较聚类内的发病情况,并使用 400 个 bootstrap 样本评估聚类稳定性。
在模拟数据集上,与已知聚类最接近的(最大 aRI)是 LCA 和 MCA-kmeans 算法。在病历数据集上,所有四种算法都识别出一个包含 20-25%数据集的聚类,其中约 82%的患者在所有四种算法中都相同。LCA 和 MCA-kmeans 都发现了第二个包含 7%数据集的聚类。其他聚类仅由一种算法发现。LCA 和 MCA-kmeans 聚类的划分最相似(aRI 为 0.54)。
LCA 比其他聚类算法获得了更高的 aRI。