Chemical Engineering Department, Faculty of Engineering and Information Technology, The University of Melbourne, Melbourne, Australia; Water Research Australia, Melbourne Based Team, Melbourne, Australia.
Chemical Engineering Department, Faculty of Engineering and Information Technology, The University of Melbourne, Melbourne, Australia.
Sci Total Environ. 2023 Feb 1;858(Pt 1):159748. doi: 10.1016/j.scitotenv.2022.159748. Epub 2022 Oct 25.
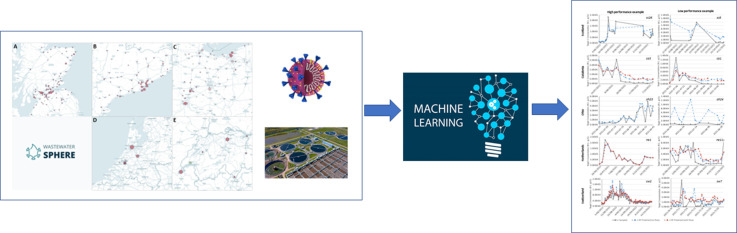
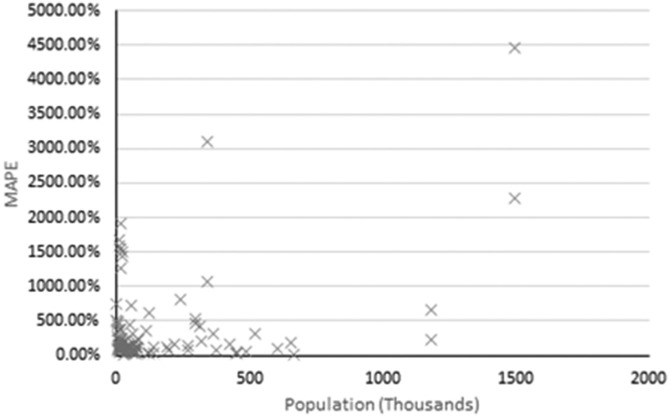
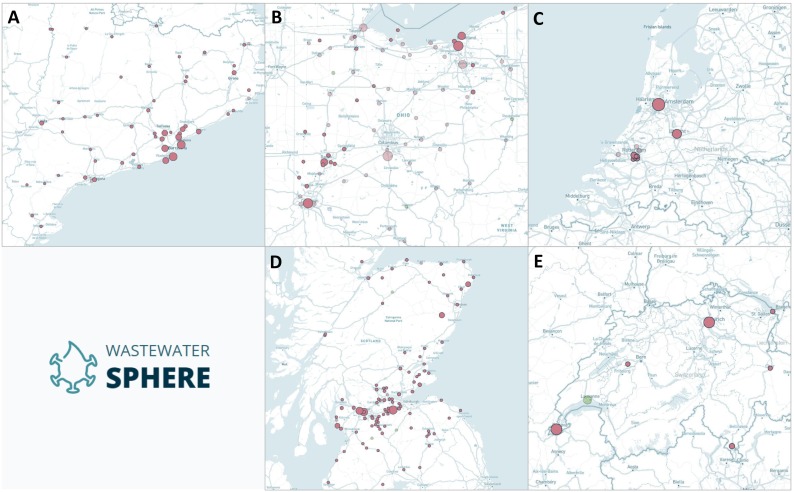
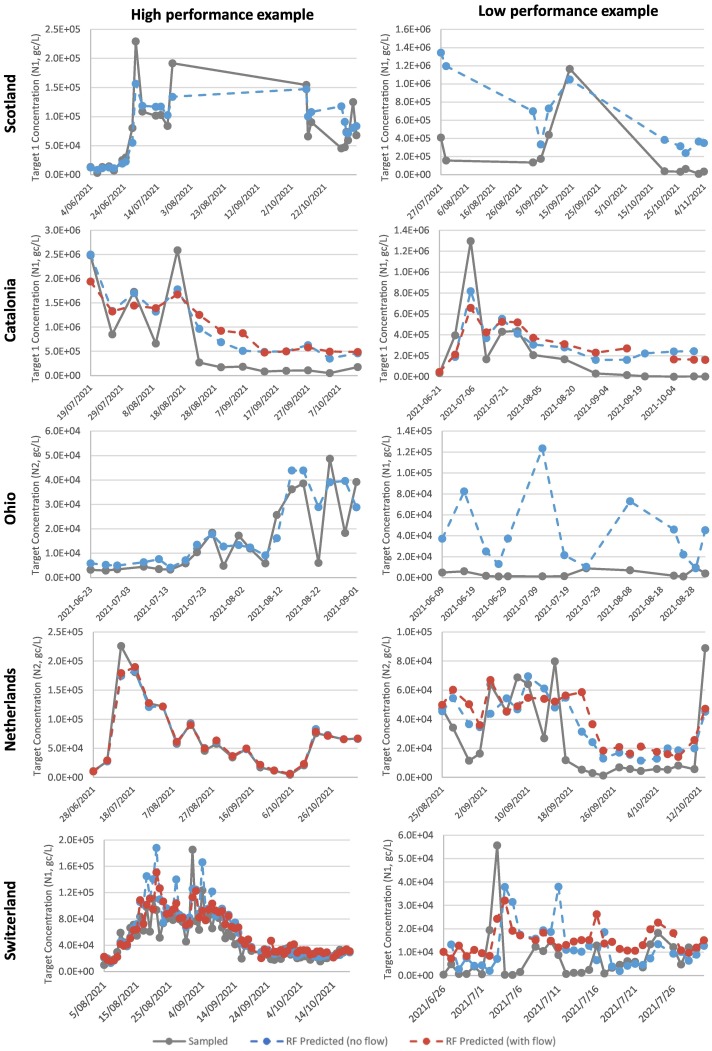
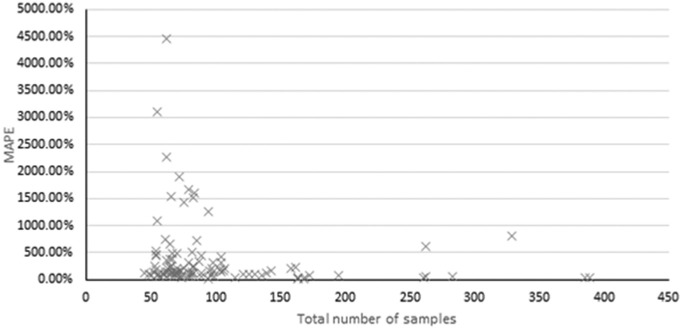
Wastewater-based epidemiology (WBE) has gained increasing attention as a complementary tool to conventional surveillance methods with potential for significant resource and labour savings when used for public health monitoring. Using WBE datasets to train machine learning algorithms and develop predictive models may also facilitate early warnings for the spread of outbreaks. The challenges associated with using machine learning for the analysis of WBE datasets and timeseries forecasting of COVID-19 were explored by running Random Forest (RF) algorithms on WBE datasets across 108 sites in five regions: Scotland, Catalonia, Ohio, the Netherlands, and Switzerland. This method uses measurements of SARS-CoV-2 RNA fragment concentration in samples taken at the inlets of wastewater treatment plants, providing insight into the prevalence of infection in upstream wastewater catchment populations. RF's forecasting performance at each site was quantitatively evaluated by determining mean absolute percentage error (MAPE) values, which was used to highlight challenges affecting future implementations of RF for WBE forecasting efforts. Performance was generally poor using WBE datasets from Catalonia, Scotland, and Ohio with 'reasonable' or better forecasts constituting 0 %, 5 %, and 0 % of these regions' forecasts, respectively. RF's performance was much stronger with WBE data from the Netherlands and Switzerland, which provided 55 % and 45 % 'reasonable' or better forecasts respectively. Sampling frequency and training set size were identified as key factors contributing to accuracy, while inclusion of too many unnecessary variables (or e.g., flow data) was identified as a contributing factor to poor performance. The contribution of catchment population on forecast accuracy was more ambiguous. This study determined that the factors governing RF's forecast performance are complicated and interrelated, which presents challenges for further work in this space. A sufficiently accurate further iteration of the tool discussed within this study would provide significant but varying value for public health departments for monitoring future, or ongoing outbreaks, assisting the implementation of on-time health response measures.
基于污水的流行病学(WBE)作为传统监测方法的补充工具,在用于公共卫生监测时具有显著的资源和劳动力节约潜力,因此越来越受到关注。使用 WBE 数据集训练机器学习算法并开发预测模型,也可以为疫情的传播提供早期预警。通过在苏格兰、加泰罗尼亚、俄亥俄州、荷兰和瑞士等 5 个地区的 108 个站点的 WBE 数据集中运行随机森林(RF)算法,探讨了使用机器学习分析 WBE 数据集和对 COVID-19 进行时间序列预测的挑战。该方法使用污水处理厂入口处采集的 SARS-CoV-2 RNA 片段浓度测量值,深入了解上游污水集水区人群的感染流行情况。通过确定平均绝对百分比误差(MAPE)值,对每个站点的 RF 预测性能进行定量评估,MAPE 值用于突出影响未来 RF 用于 WBE 预测工作实施的挑战。使用加泰罗尼亚、苏格兰和俄亥俄州的 WBE 数据集的性能通常较差,这些地区的“合理”或更好的预测分别占其预测的 0%、5%和 0%。使用荷兰和瑞士的 WBE 数据,RF 的性能要强得多,分别提供了 55%和 45%的“合理”或更好的预测。采样频率和训练集大小被确定为影响准确性的关键因素,而包含太多不必要的变量(例如流量数据)被确定为导致性能不佳的一个因素。集水区人口对预测准确性的贡献则更加模糊。本研究确定,RF 预测性能的控制因素复杂且相互关联,这为该领域的进一步工作带来了挑战。该研究中讨论的工具的进一步迭代,如果足够准确,将为公共卫生部门监测未来或正在进行的疫情提供重大但不同的价值,协助及时实施卫生应对措施。