Department of Nephrology, Tokyo Women's Medical University, 8-1 Kawada-Cho, Shinjuku-Ku, Tokyo, 162-8666, Japan.
Clinical Research Division for Polycystic Kidney Disease, Department of Nephrology, Tokyo Women's Medical University, Tokyo, 162-8666, Japan.
Sci Rep. 2022 Nov 9;12(1):19155. doi: 10.1038/s41598-022-23882-7.
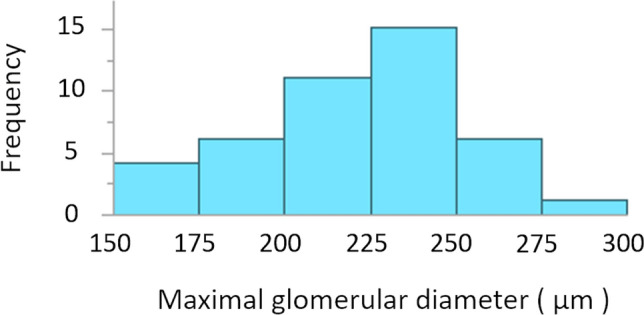
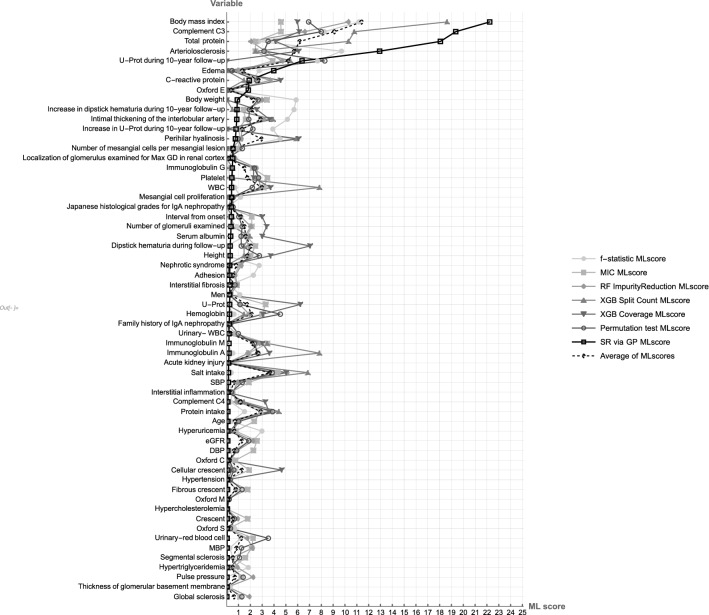
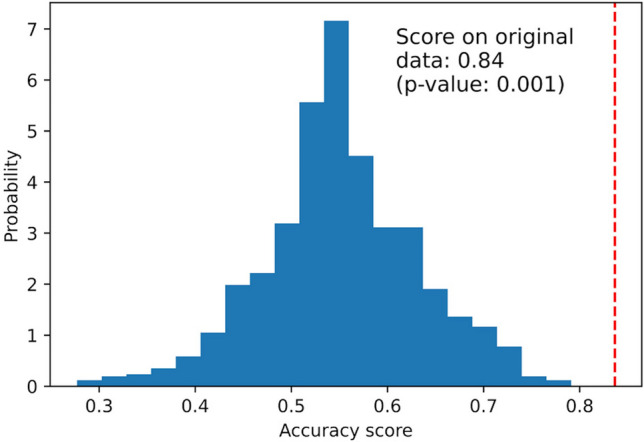
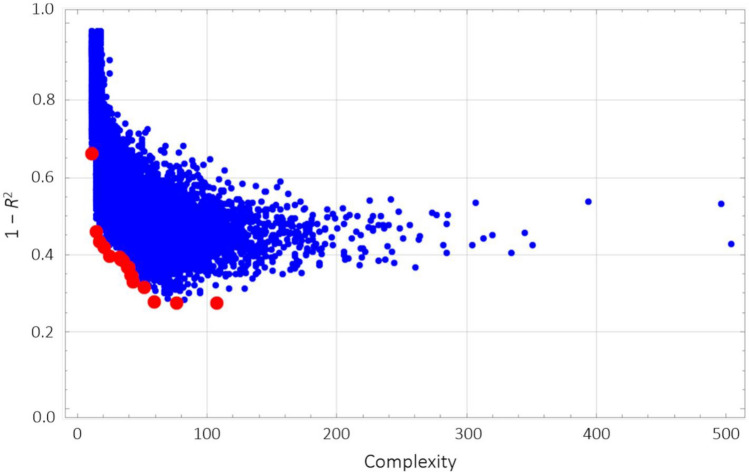
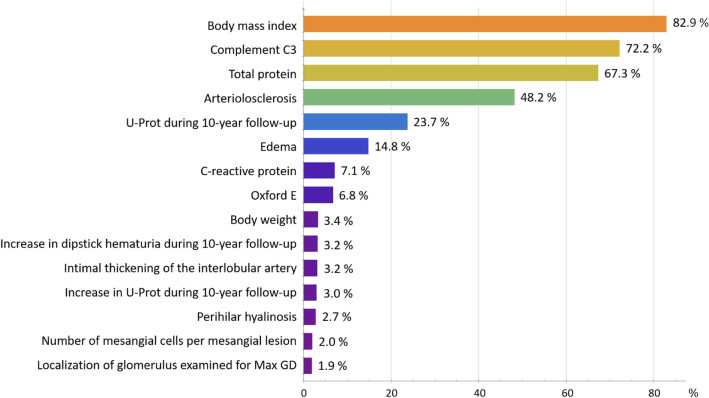
A practical research method integrating data-driven machine learning with conventional model-driven statistics is sought after in medicine. Although glomerular hypertrophy (or a large renal corpuscle) on renal biopsy has pathophysiological implications, it is often misdiagnosed as adaptive/compensatory hypertrophy. Using a generative machine learning method, we aimed to explore the factors associated with a maximal glomerular diameter of ≥ 242.3 μm. Using the frequency-of-usage variable ranking in generative models, we defined the machine learning scores with symbolic regression via genetic programming (SR via GP). We compared important variables selected by SR with those selected by a point-biserial correlation coefficient using multivariable logistic and linear regressions to validate discriminatory ability, goodness-of-fit, and collinearity. Body mass index, complement component C3, serum total protein, arteriolosclerosis, C-reactive protein, and the Oxford E1 score were ranked among the top 10 variables with high machine learning scores using SR via GP, while the estimated glomerular filtration rate was ranked 46 among the 60 variables. In multivariable analyses, the R value was higher (0.61 vs. 0.45), and the corrected Akaike Information Criterion value was lower (402.7 vs. 417.2) with variables selected with SR than those selected with point-biserial r. There were two variables with variance inflation factors higher than 5 in those using point-biserial r and none in SR. Data-driven machine learning models may be useful in identifying significant and insignificant correlated factors. Our method may be generalized to other medical research due to the procedural simplicity of using top-ranked variables selected by machine learning.
在医学领域,人们追求一种将数据驱动的机器学习与传统的模型驱动统计学相结合的实用研究方法。虽然肾活检中的肾小球肥大(或大肾单位)具有病理生理学意义,但它常被误诊为适应性/代偿性肥大。我们使用生成式机器学习方法,旨在探讨与肾小球直径最大值≥242.3μm相关的因素。使用生成式模型中的使用频率变量排序,我们通过遗传编程(SR via GP)进行符号回归定义机器学习分数。我们通过多变量逻辑回归和线性回归比较了 SR 选择的重要变量与两点双变量相关系数选择的重要变量,以验证判别能力、拟合优度和共线性。体质量指数、补体成分 C3、血清总蛋白、小动脉硬化、C 反应蛋白和牛津 E1 评分在使用 SR via GP 的机器学习分数较高的前 10 个变量中排名较高,而估算肾小球滤过率在 60 个变量中排名第 46。在多变量分析中,SR 选择的变量的 R 值较高(0.61 对 0.45),校正后的赤池信息量准则值较低(402.7 对 417.2)。与两点双变量 r 选择的变量相比,SR 选择的变量中有两个变量的方差膨胀因子高于 5,而在 SR 中则没有。数据驱动的机器学习模型可能有助于识别重要和不重要的相关因素。由于使用机器学习选择的排名靠前的变量的程序简单,我们的方法可能会推广到其他医学研究中。