Medical and Imaging Informatics, Department of Radiological Sciences, David Geffen School of Medicine at University California, Los Angeles.
Clinical Research Division, Fred Hutchinson Cancer Center, Seattle, Washington.
JAMA Netw Open. 2022 Nov 1;5(11):e2242343. doi: 10.1001/jamanetworkopen.2022.42343.
With a shortfall in fellowship-trained breast radiologists, mammography screening programs are looking toward artificial intelligence (AI) to increase efficiency and diagnostic accuracy. External validation studies provide an initial assessment of how promising AI algorithms perform in different practice settings.
To externally validate an ensemble deep-learning model using data from a high-volume, distributed screening program of an academic health system with a diverse patient population.
DESIGN, SETTING, AND PARTICIPANTS: In this diagnostic study, an ensemble learning method, which reweights outputs of the 11 highest-performing individual AI models from the Digital Mammography Dialogue on Reverse Engineering Assessment and Methods (DREAM) Mammography Challenge, was used to predict the cancer status of an individual using a standard set of screening mammography images. This study was conducted using retrospective patient data collected between 2010 and 2020 from women aged 40 years and older who underwent a routine breast screening examination and participated in the Athena Breast Health Network at the University of California, Los Angeles (UCLA).
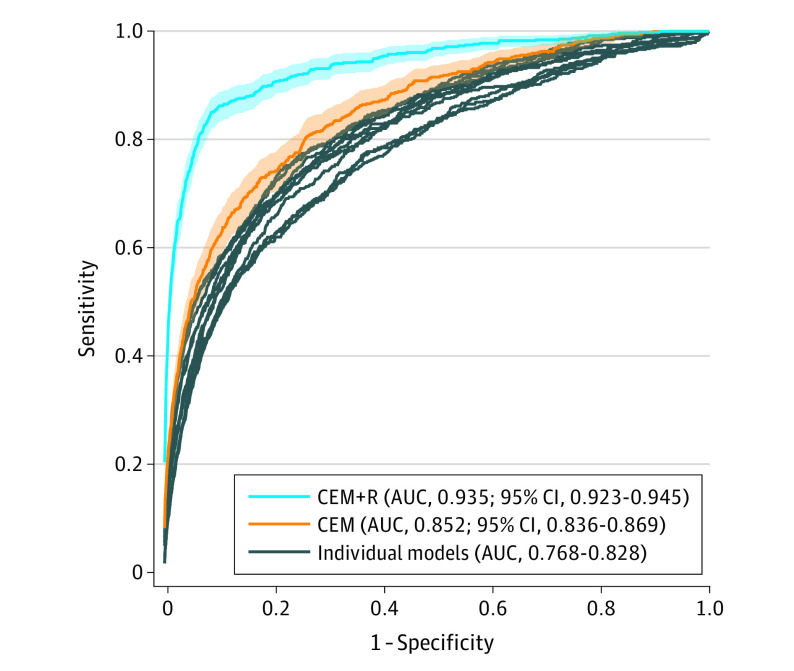
Performance of the challenge ensemble method (CEM) and the CEM combined with radiologist assessment (CEM+R) were compared with diagnosed ductal carcinoma in situ and invasive cancers within a year of the screening examination using performance metrics, such as sensitivity, specificity, and area under the receiver operating characteristic curve (AUROC).
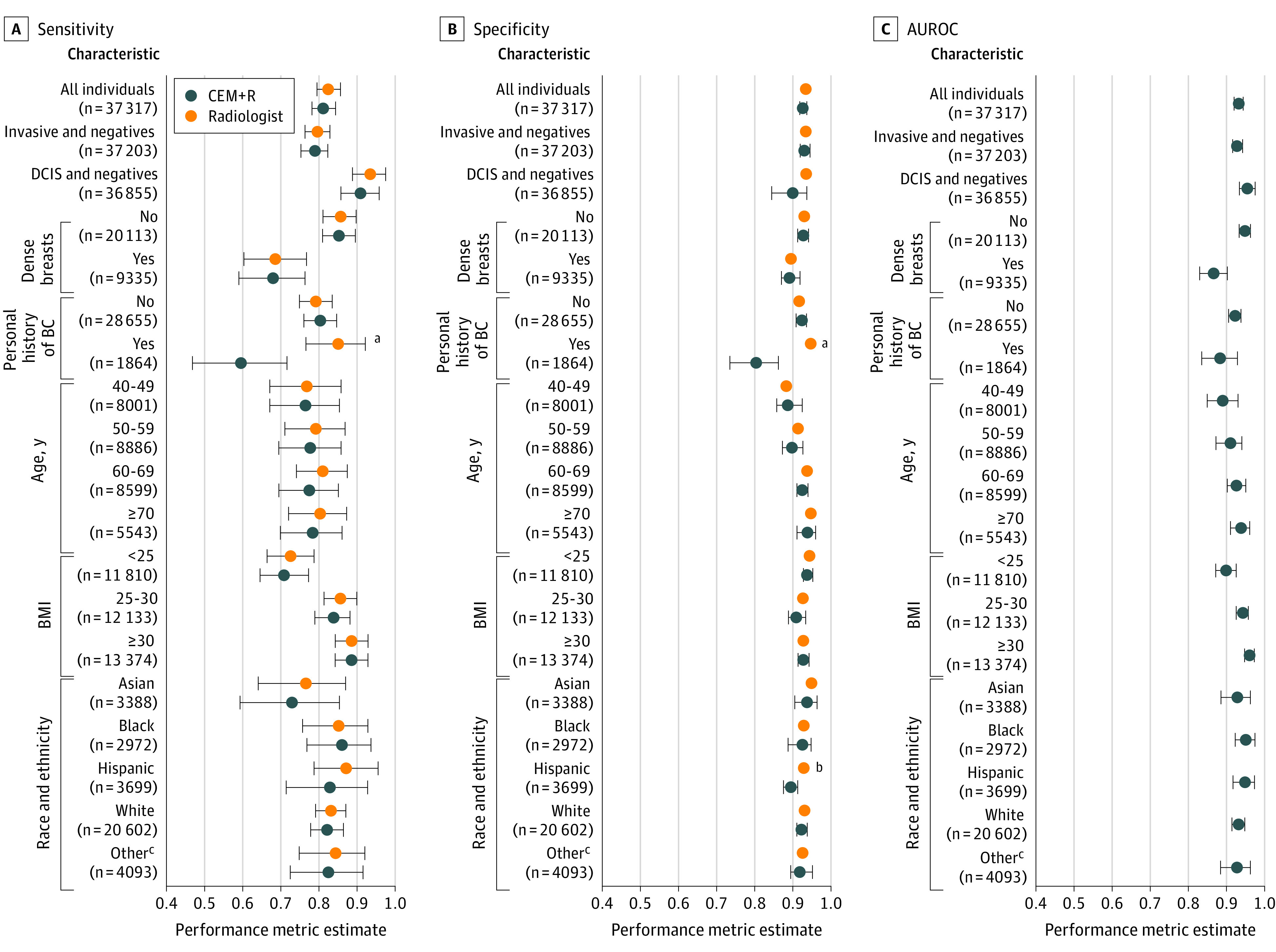
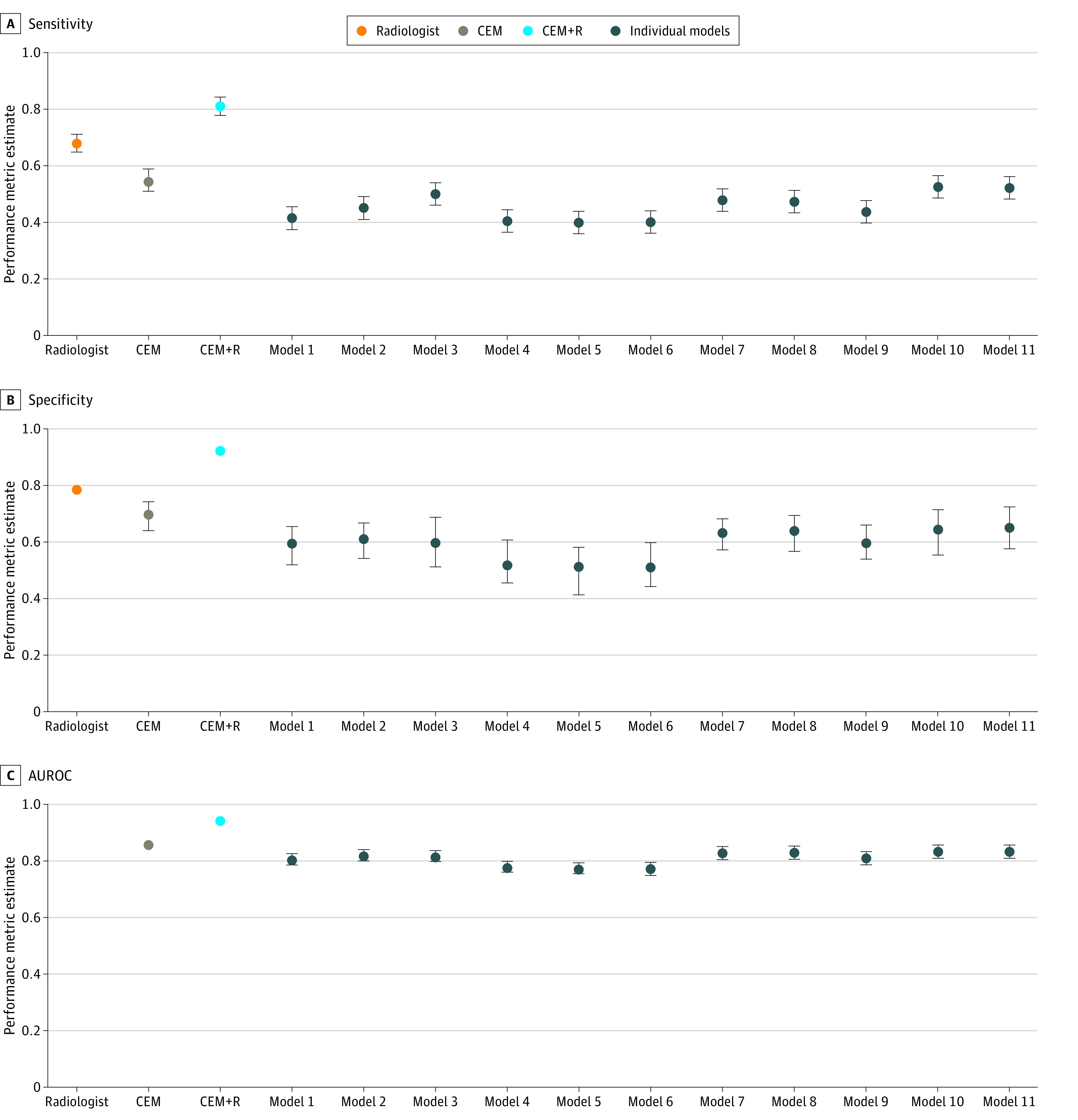
Evaluated on 37 317 examinations from 26 817 women (mean [SD] age, 58.4 [11.5] years), individual model AUROC estimates ranged from 0.77 (95% CI, 0.75-0.79) to 0.83 (95% CI, 0.81-0.85). The CEM model achieved an AUROC of 0.85 (95% CI, 0.84-0.87) in the UCLA cohort, lower than the performance achieved in the Kaiser Permanente Washington (AUROC, 0.90) and Karolinska Institute (AUROC, 0.92) cohorts. The CEM+R model achieved a sensitivity (0.813 [95% CI, 0.781-0.843] vs 0.826 [95% CI, 0.795-0.856]; P = .20) and specificity (0.925 [95% CI, 0.916-0.934] vs 0.930 [95% CI, 0.929-0.932]; P = .18) similar to the radiologist performance. The CEM+R model had significantly lower sensitivity (0.596 [95% CI, 0.466-0.717] vs 0.850 [95% CI, 0.766-0.923]; P < .001) and specificity (0.803 [95% CI, 0.734-0.861] vs 0.945 [95% CI, 0.936-0.954]; P < .001) than the radiologist in women with a prior history of breast cancer and Hispanic women (0.894 [95% CI, 0.873-0.910] vs 0.926 [95% CI, 0.919-0.933]; P = .004).
This study found that the high performance of an ensemble deep-learning model for automated screening mammography interpretation did not generalize to a more diverse screening cohort, suggesting that the model experienced underspecification. This study suggests the need for model transparency and fine-tuning of AI models for specific target populations prior to their clinical adoption.
重要性:随着接受过 fellowship培训的乳腺放射科医生的短缺,乳房 X 光筛查项目正在寻求人工智能(AI)来提高效率和诊断准确性。外部验证研究初步评估了有前途的 AI 算法在不同实践环境中的表现。
目的:使用来自学术健康系统的高容量分布式筛查计划的患者人群的多样性数据,对使用深度学习模型的集成进行外部验证。
设计、设置和参与者:在这项诊断研究中,使用了一种集成学习方法,该方法重新加权了 Digital Mammography Dialogue on Reverse Engineering Assessment and Methods(DREAM)乳房 X 光挑战赛中 11 个表现最佳的 AI 模型的输出,以使用标准的筛查乳房 X 光图像来预测个体的癌症状态。这项研究使用了回顾性患者数据,这些数据是在 2010 年至 2020 年期间从 40 岁及以上接受常规乳房筛查检查并参加加州大学洛杉矶分校(UCLA)雅典娜乳房健康网络的女性中收集的。
主要结果和措施:使用性能指标(如敏感性、特异性和接收者操作特征曲线下的面积(AUROC))比较了挑战集成方法(CEM)和 CEM 与放射科医生评估相结合(CEM+R)的性能,与一年内筛查检查的导管原位癌和浸润性癌的诊断结果进行比较。
结果:在 26817 名女性的 37317 次检查中评估(平均[SD]年龄,58.4[11.5]岁),个体模型 AUROC 估计值范围为 0.77(95%CI,0.75-0.79)至 0.83(95%CI,0.81-0.85)。在 UCLA 队列中,CEM 模型的 AUROC 为 0.85(95%CI,0.84-0.87),低于 Kaiser Permanente Washington(AUROC,0.90)和 Karolinska Institute(AUROC,0.92)队列的性能。CEM+R 模型的敏感性(0.813[95%CI,0.781-0.843]vs 0.826[95%CI,0.795-0.856];P=0.20)和特异性(0.925[95%CI,0.916-0.934]vs 0.930[95%CI,0.929-0.932];P=0.18)与放射科医生的表现相似。CEM+R 模型的敏感性(0.596[95%CI,0.466-0.717]vs 0.850[95%CI,0.766-0.923];P<0.001)和特异性(0.803[95%CI,0.734-0.861]vs 0.945[95%CI,0.936-0.954];P<0.001)明显低于有乳腺癌病史和西班牙裔女性的放射科医生(0.894[95%CI,0.873-0.910]vs 0.926[95%CI,0.919-0.933];P=0.004)。
结论和相关性:本研究发现,用于自动筛查乳房 X 光解释的深度学习模型的高性能并未推广到更多样化的筛查队列,这表明该模型存在欠规范。本研究表明,在将 AI 模型临床应用之前,需要对其进行模型透明度和针对特定目标人群的微调。