Wellcome Sanger Institute, Wellcome Genome Campus, Hinxton, CB10 1SA, UK.
The Gurdon Institute, University of Cambridge, Tennis Court Road, Cambridge, CB2 1QN, UK.
BMC Bioinformatics. 2022 Dec 12;23(1):536. doi: 10.1186/s12859-022-05085-z.
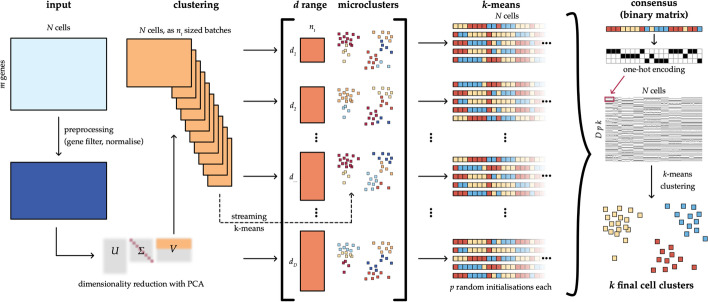
Today it is possible to profile the transcriptome of individual cells, and a key step in the analysis of these datasets is unsupervised clustering. For very large datasets, efficient algorithms are required to ensure that analyses can be conducted with reasonable time and memory requirements.
Here, we present a highly efficient k-means based approach, and we demonstrate that it scales favorably with the number of cells with regards to time and memory.
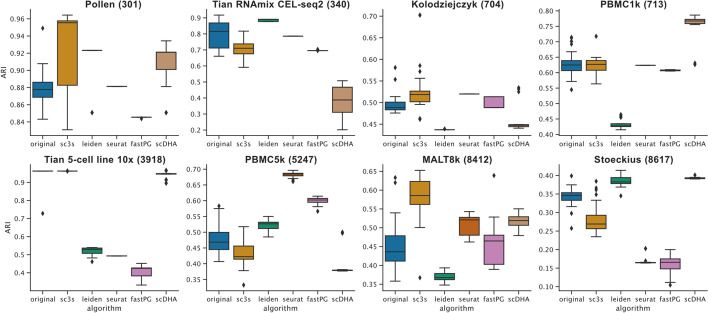
We have demonstrated that our streaming k-means clustering algorithm gives state-of-the-art performance while resource requirements scale favorably for up to 2 million cells.
如今,人们可以对单个细胞的转录组进行分析,而分析这些数据集的关键步骤是无监督聚类。对于非常大的数据集,需要使用高效的算法来确保分析可以在合理的时间和内存要求下进行。
在这里,我们提出了一种基于高效 k-均值的方法,并证明它在时间和内存方面都能很好地扩展到细胞数量。
我们已经证明,我们的流式 k-均值聚类算法在资源需求方面表现出色,最多可扩展到 200 万个细胞。