School of Computer, Nanjing University of Posts and Telecommunications, Nanjing 210023, China.
State Key Laboratory for Novel Software Technology, Nanjing University, Nanjing 210046, China.
Sensors (Basel). 2022 Dec 7;22(24):9584. doi: 10.3390/s22249584.
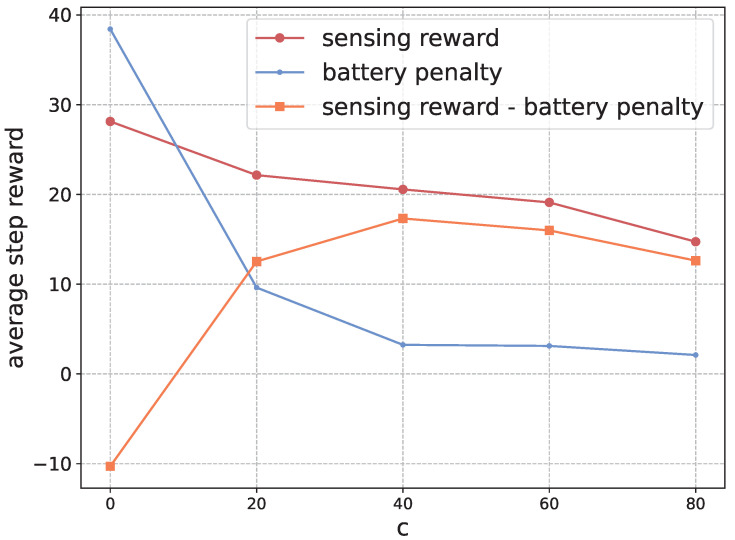
In a typical mobile-sensing scenario, multiple autonomous vehicles cooperatively navigate to maximize the spatial-temporal coverage of the environment. However, as each vehicle can only make decentralized navigation decisions based on limited local observations, it is still a critical challenge to coordinate the vehicles for cooperation in an open, dynamic environment. In this paper, we propose a novel framework that incorporates consensual communication in multi-agent reinforcement learning for cooperative mobile sensing. At each step, the vehicles first learn to communicate with each other, and then, based on the received messages from others, navigate. Through communication, the decentralized vehicles can share information to break through the dilemma of local observation. Moreover, we utilize mutual information as a regularizer to promote consensus among the vehicles. The mutual information can enforce positive correlation between the navigation policy and the communication message, and therefore implicitly coordinate the decentralized policies. The convergence of this regularized algorithm can be proved theoretically under certain mild assumptions. In the experiments, we show that our algorithm is scalable and can converge very fast during training phase. It also outperforms other baselines significantly in the execution phase. The results validate that consensual communication plays very important role in coordinating the behaviors of decentralized vehicles.
在典型的移动感知场景中,多个自主车辆协同导航以最大限度地覆盖环境的时空范围。然而,由于每辆车只能根据有限的局部观测做出分散的导航决策,因此在开放、动态的环境中协调车辆进行合作仍然是一个关键挑战。在本文中,我们提出了一种新的框架,将共识通信纳入多智能体强化学习中,用于协同移动感知。在每一步中,车辆首先学会相互通信,然后根据从其他车辆接收到的消息进行导航。通过通信,分散的车辆可以共享信息,突破局部观测的困境。此外,我们利用互信息作为正则化项来促进车辆之间的共识。互信息可以强制导航策略和通信消息之间的正相关关系,从而隐式地协调分散的策略。在某些温和假设下,可以从理论上证明这个正则化算法的收敛性。在实验中,我们表明我们的算法是可扩展的,并且在训练阶段可以非常快速地收敛。它在执行阶段也明显优于其他基线。结果验证了共识通信在协调分散车辆的行为方面起着非常重要的作用。