Zietz Michael, Himmelstein Daniel S, Kloster Kyle, Williams Christopher, Nagle Michael W, Greene Casey S
Department of Physics & Astronomy, University of Pennsylvania, Philadelphia, Pennsylvania, United States of America; Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania, Philadelphia, Pennsylvania, United States of America.
Department of Systems Pharmacology and Translational Therapeutics, University of Pennsylvania, Philadelphia, Pennsylvania, United States of America.
bioRxiv. 2023 Jan 6:2023.01.05.522939. doi: 10.1101/2023.01.05.522939.
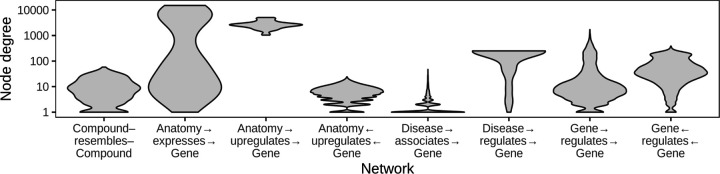
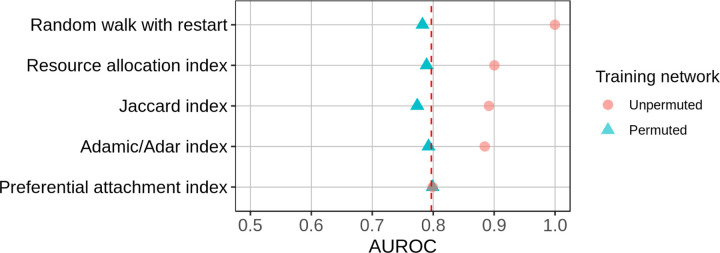
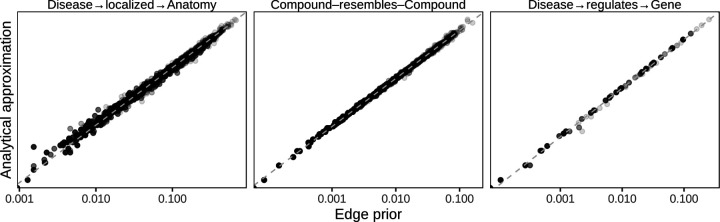
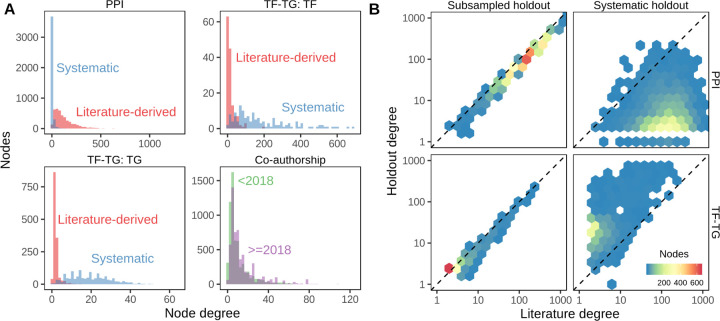
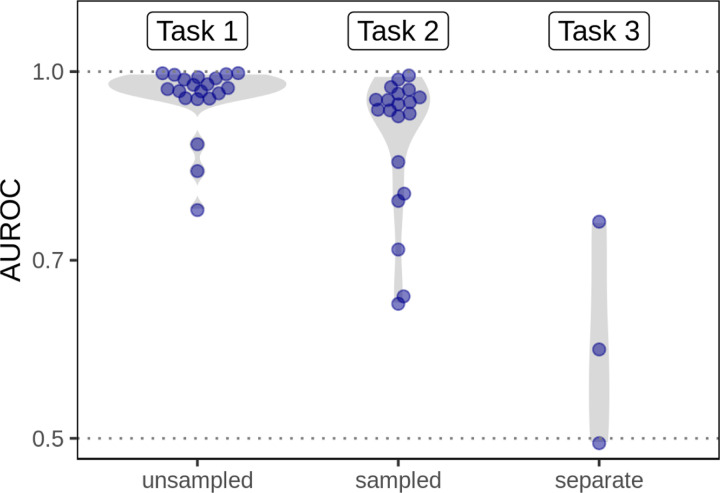
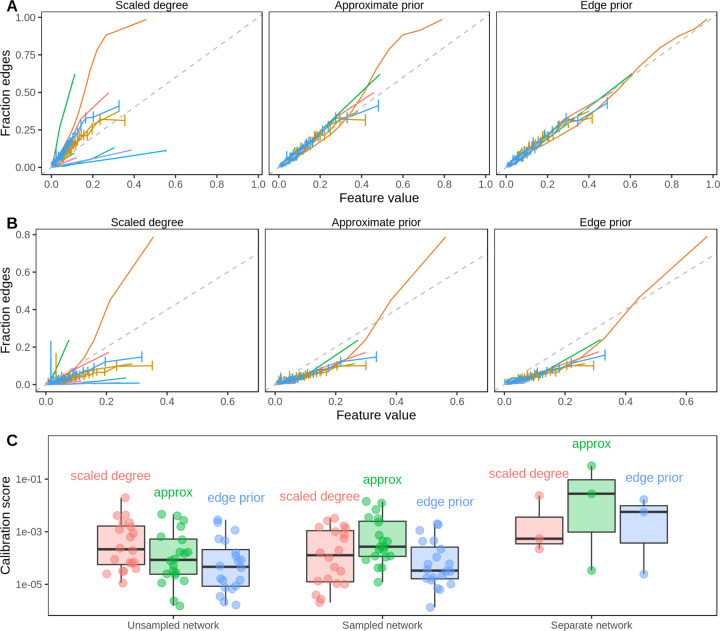
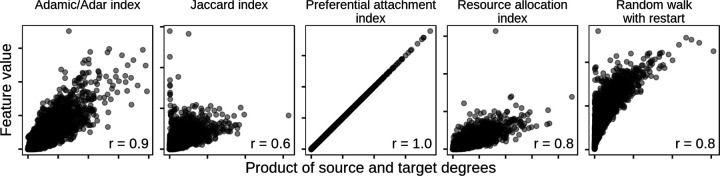
Important tasks in biomedical discovery such as predicting gene functions, gene-disease associations, and drug repurposing opportunities are often framed as network edge prediction. The number of edges connecting to a node, termed degree, can vary greatly across nodes in real biomedical networks, and the distribution of degrees varies between networks. If degree strongly influences edge prediction, then imbalance or bias in the distribution of degrees could lead to nonspecific or misleading predictions. We introduce a network permutation framework to quantify the effects of node degree on edge prediction. Our framework decomposes performance into the proportions attributable to degree and the network's specific connections. We discover that performance attributable to factors other than degree is often only a small portion of overall performance. Degree's predictive performance diminishes when the networks used for training and testing-despite measuring the same biological relationships-were generated using distinct techniques and hence have large differences in degree distribution. We introduce the permutation-derived edge prior as the probability that an edge exists based only on degree. The edge prior shows excellent discrimination and calibration for 20 biomedical networks (16 bipartite, 3 undirected, 1 directed), with AUROCs frequently exceeding 0.85. Researchers seeking to predict new or missing edges in biological networks should use the edge prior as a baseline to identify the fraction of performance that is nonspecific because of degree. We released our methods as an open-source Python package (https://github.com/hetio/xswap/).
生物医学发现中的重要任务,如预测基因功能、基因与疾病的关联以及药物重新利用的机会,通常被构建为网络边预测问题。连接到一个节点的边的数量,即度,在实际生物医学网络中的不同节点之间可能有很大差异,并且度的分布在不同网络之间也有所不同。如果度对边预测有强烈影响,那么度分布的不平衡或偏差可能导致非特异性或误导性的预测。我们引入了一个网络排列框架来量化节点度对边预测的影响。我们的框架将性能分解为可归因于度的比例和网络的特定连接。我们发现,可归因于度以外因素的性能通常仅占整体性能的一小部分。当用于训练和测试的网络——尽管测量的是相同的生物学关系——是使用不同技术生成的,因此度分布有很大差异时,度的预测性能会下降。我们引入了排列衍生的边先验,即仅基于度存在边的概率。边先验对20个生物医学网络(16个二分图、3个无向图、1个有向图)显示出出色的区分能力和校准能力,曲线下面积(AUROC)经常超过0.85。试图预测生物网络中新的或缺失边的研究人员应使用边先验作为基线,以确定由于度而导致的非特异性性能部分。我们将我们的方法作为一个开源Python包发布(https://github.com/hetio/xswap/)。