Know-Center, 8010, Graz, Austria.
Division of Neuroradiology, Vascular and Interventional Radiology, Department of Radiology, Medical University Graz, 8036, Graz, Austria.
Sci Rep. 2023 Feb 9;13(1):2353. doi: 10.1038/s41598-023-29323-3.
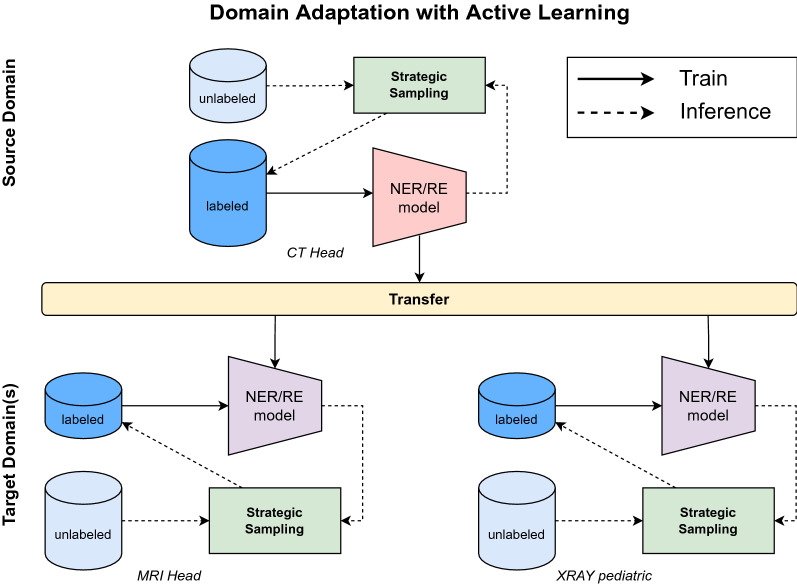
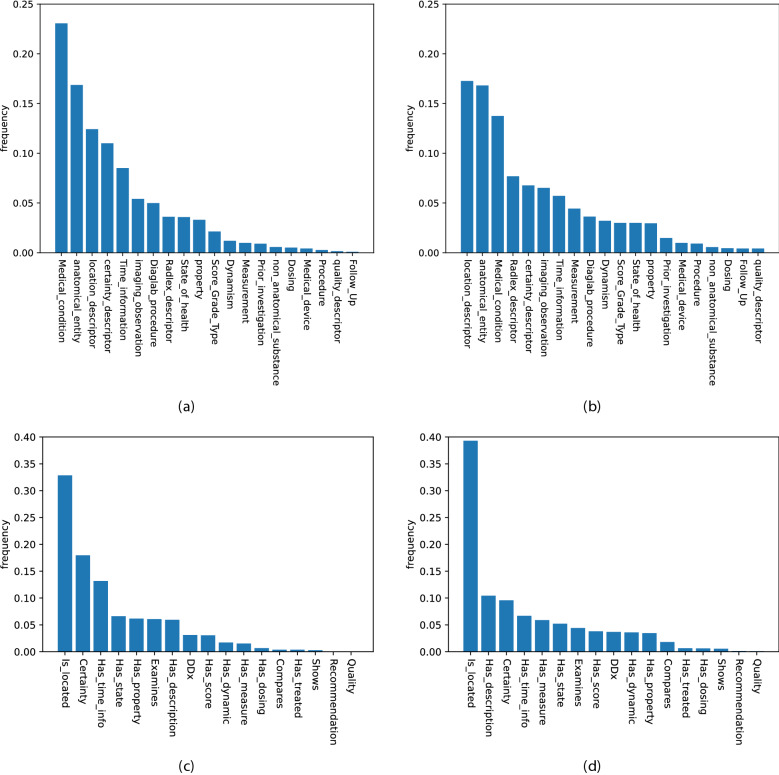
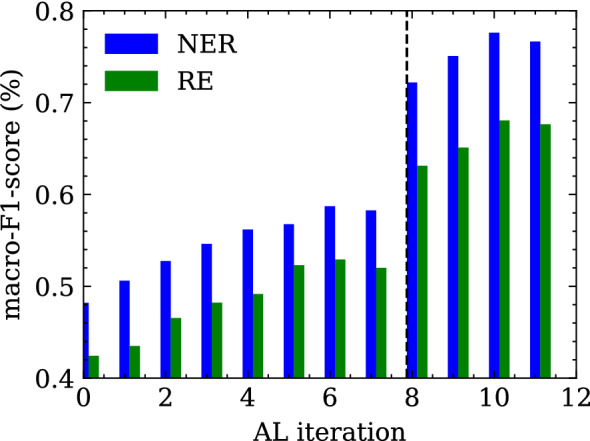
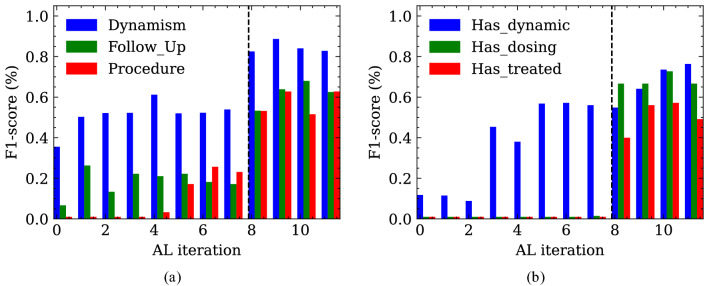
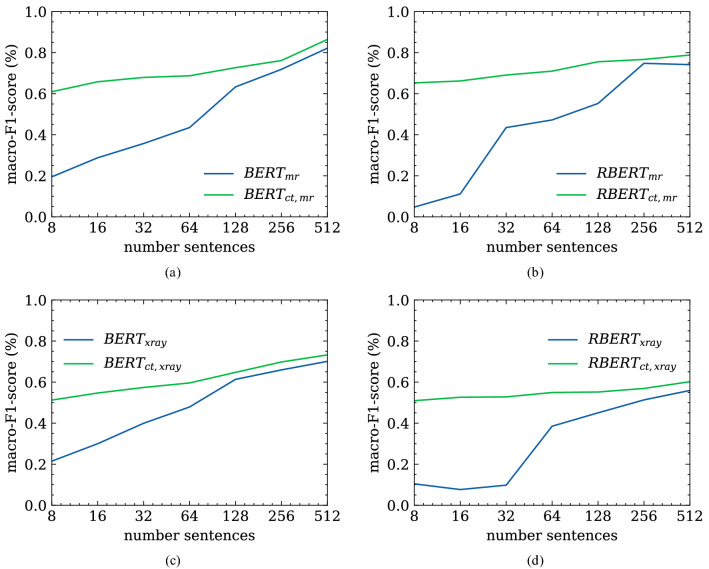
Recent advances in deep learning and natural language processing (NLP) have opened many new opportunities for automatic text understanding and text processing in the medical field. This is of great benefit as many clinical downstream tasks rely on information from unstructured clinical documents. However, for low-resource languages like German, the use of modern text processing applications that require a large amount of training data proves to be difficult, as only few data sets are available mainly due to legal restrictions. In this study, we present an information extraction framework that was initially pre-trained on real-world computed tomographic (CT) reports of head examinations, followed by domain adaptive fine-tuning on reports from different imaging examinations. We show that in the pre-training phase, the semantic and contextual meaning of one clinical reporting domain can be captured and effectively transferred to foreign clinical imaging examinations. Moreover, we introduce an active learning approach with an intrinsic strategic sampling method to generate highly informative training data with low human annotation cost. We see that the model performance can be significantly improved by an appropriate selection of the data to be annotated, without the need to train the model on a specific downstream task. With a general annotation scheme that can be used not only in the radiology field but also in a broader clinical setting, we contribute to a more consistent labeling and annotation process that also facilitates the verification and evaluation of language models in the German clinical setting.
深度学习和自然语言处理(NLP)的最新进展为医学领域的自动文本理解和文本处理开辟了许多新的机会。由于许多临床下游任务依赖于来自非结构化临床文档的信息,因此这非常有益。然而,对于德语等资源较少的语言,使用需要大量训练数据的现代文本处理应用程序证明是困难的,这主要是因为法律限制,可用的数据集很少。在这项研究中,我们提出了一个信息提取框架,该框架最初是在真实世界的头部 CT 检查报告上进行预训练的,然后在来自不同成像检查的报告上进行领域自适应微调。我们表明,在预训练阶段,可以捕获一个临床报告领域的语义和上下文含义,并有效地将其转移到外国临床成像检查中。此外,我们引入了一种主动学习方法,该方法具有内在的策略性采样方法,可以用低人工注释成本生成信息量高的训练数据。我们发现,通过适当选择要注释的数据,可以显著提高模型性能,而无需在特定的下游任务上训练模型。通过一个不仅可以在放射学领域,而且可以在更广泛的临床环境中使用的通用注释方案,我们为更一致的标记和注释过程做出了贡献,这也促进了德语临床环境中语言模型的验证和评估。